Taller RFE 20191026
D. S. Fernandez del Viso
10/19/2019
R
R is an open-source programming environment, for statistical computing and data visualization, among other capabilities.
R has many features to recommend it (Kabacoff, 2015):
Most commercial statistical software platforms cost thousands, if not tens of thousands, of dollars. R is free! If you’re a teacher or a student, the benefits are obvious.
R is a comprehensive statistical platform, offering all manner of data-analytic techniques. Just about any type of data analysis can be done in R.
R contains advanced statistical routines not yet available in other packages. In fact, new methods become available for download on a weekly basis.
R has state-of-the-art graphics capabilities. If you want to visualize complex data, R has the most comprehensive and powerful feature set available.
R is a powerful platform for interactive data analysis and exploration. For example, the results of any analytic step can easily be saved, manipulated, and used as input for additional analyses.
Getting data into a usable form from multiple sources can be a challenging proposition. R can easily import data from a wide variety of sources, including text files, database-management systems, statistical packages, and specialized data stores. It can write data out to these systems as well. R can also access data directly from web pages, social media sites, and a wide range of online data services.
R provides an unparalleled platform for programming new statistical methods in an easy, straightforward manner. It’s easily extensible and provides a natural language for quickly programming recently published methods.
R functionality can be integrated into applications written in other languages, including C++, Java, Python, PHP, Pentaho, SAS, and SPSS. This allows you to continue working in a language that you may be familiar with, while adding R’s capabilities to your applications.
R runs on a wide array of platforms, including Windows, Unix, and Mac OS X. It’s likely to run on any computer you may have. If you don’t want to learn a new language, a variety of graphic user interfaces (GUIs) are available, offering the power of R through menus and dialogs.
where to look in the book?:
chapter 1
RStudio
Programming, editing, project management, and other procedures in R, are more easy and efficient using an integrated development environment (IDE), and the most used and versatile is RStudio.
Exercises
Open RStudio:
- browse all the components of the interface
- establish a Working Directory
- create a R Script (compare with the R console)

- write code to calculate the area of a geometric surface, and run
it
- explore other windows and menus of RStudio
- load packages
#####where to look in the book?: chapter 2 & 3
R Markdown (or R Notebook)
As important as carrying out the data analysis of an investigation (main objective of this workshop), it is also important to communicate the results to an audience, and receive acknowledgement and comments about them. Usually that aspect is addressed at the end (as in the workshop book: Chapter 28), but if we do so, we can leave behind notes, results, graphs, et c., which at some point we have to find, organize and move to a final document.
Creating a R Markdown document
First, check if you have the package rmarkdown installed; for this, look into the Packages menu (User Library).
To create a R Markdown document, use the left-upper corner menu:
Select R Markdown.
Editing the document
The R Markdown has three types of content:
- an (optional) YAML header surrounded by - - -
- R code chunks surrounded by ```
- simple text mixed with formatted text, images, tables
The YAML header is a metadata section of the document, and can be edited to include basic information of the document:
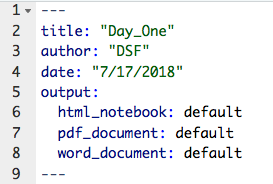
You can change (or eliminate) the title, author, and date. The output option is originally created by RStudio, and depends on the output format that you produce (html, pdf, Word). A R Markdown document (html_document) can be transformed into a R Notebook (html_notebook) and vice versa.
The text and other document features (web links, images, tables) are edited or created using a R Markdown syntax.
Inserting R code chunks
A code chunk is simply a piece of R code by itself, embedded in a R Markdown document. The format is:

Inside the {r} you can write chunk options that control the behavior of the code output, when producing the final document.
Another way to create code chunks (including for other scripting
languages) and select options, is using the  drop-menu.
drop-menu.

El proceso de Investigación
Executing code chunks and controling output
Code in the notebook can be executed in different ways: Use the green triangle button on the toolbar of a code chunk that has the tool tip “Run Current Chunk”, or Ctrl + Shift + Enter (macOS: Cmd + Shift + Enter) to run the current chunk, or use “Run Selected Line(s)”, for one or more selected lines of code.
Press Ctrl + Enter (macOS: Cmd + Enter) to run just the current statement.
There are other ways to run a batch of chunks if you click the menu Run on the editor toolbar, such as “Run All”, “Run All Chunks Above”, and “Run All Chunks Below”.
In the previous section you can find how to control chunk output,
with several options, but you can also select the options using  .
.

El proceso de Investigación
Using Knit to produce a HTML or Word document
Now you can produce a HTML or Word document (this is called knitting, Knit), using the following menu:
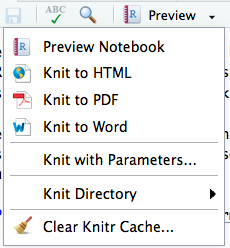
El proceso de Investigación
Producing a PDF document requires a LaTex version for your computer (usually requires more than 1 GB!).
Basic operations and variable types
- Open a new R Markdown, and name it “Apuntes del Taller R”.
- Save it with a short name.
- Edit the YAML metadata information, including a new title, your name and date.
- Write a title for a section called: “Ejercicios Introductorios”. In this section we are going to practice some common R operations and variable types.
- Create a chunk.
- Using # write titles and short descriptions inside the chunk.
Mathematical operations and variable assignment
#basic math operations
56 + 45## [1] 10156/45## [1] 1.244444#order of operations and parentheses
6 + 5 * 9## [1] 51(6 + 5) * 9## [1] 995 + 3 / 2 * 3## [1] 9.55 + 3 / (2 * 3)## [1] 5.5#variable assignment
#you can use <- or = , but the first is more used
v1 <- 2.5
v1## [1] 2.5long <- v1
width <- 1.25
area <- long * width
long## [1] 2.5width## [1] 1.25area## [1] 3.125Data types
There are four basic data types in R:
- numeric (including integer, double)
- character (including “strings”, factor)
- time (including Date and POSIXct)
- logical (TRUE, FALSE)
numeric
# how to know if a variable contain a numeric data?
vari1 <- 14 / 2
vari1## [1] 7class(vari1)## [1] "numeric"# a numeric data can be an integer
vari2 <- as.integer(14 / 2)
vari2## [1] 7class(vari2)## [1] "integer"# try 15/2character
# characters must use " "
char1 <- "hola"
char1## [1] "hola"class(char1)## [1] "character"# numeric to factor
char2 <- factor(3)
char2## [1] 3
## Levels: 3class(char2)## [1] "factor"# nchar output is the length of a character variable (or numeric treated as character)
nchar(char1)## [1] 4nchar(12358)## [1] 5# does it works with a factor?Date and Time of the day
Using as.Date store a date string (“year-month-day”) as a Date type data; it can be converted to numeric (as.numeric), counting days since January 1, 1970. With as.POSIXct a string of date and time of the day (“year-month-day hour:minute:second”) is converted to a time (POSIXct) class data; numerically is the number of seconds
# as.Date store a date string as Date data
today <- as.Date("2019-10-26")
today## [1] "2019-10-26"class(today)## [1] "Date"# number of days since January 1, 1970
today.days <- as.numeric(today)
today.days## [1] 18195class(today.days)## [1] "numeric"# date and time
today.time <- as.POSIXct("2019-10-26 09:00")
today.time## [1] "2019-10-26 09:00:00 AST"class(today.time)## [1] "POSIXct" "POSIXt"# how many seconds since January 1, 1970?logical
A variable can store logical data (TRUE or FALSE), as result of a logical statement.
# does a equal/no equal b?
a <- 23 + 2/3
b <- 25 - 2/3
equal <- a == b
equal## [1] FALSEclass(equal)## [1] "logical"noequal <- a != b
noequal## [1] TRUE# comparing characters, logical results depend on alphanumeric order
char <- "2data" > "data2"
char## [1] FALSE# what is the result: equal*5 - noequal*5 ? Why?#####where to look in the book?: chapter 4
Datasets
The first step in any data analysis is the creation of a dataset containing the data to be analyzed, in a format that meets your needs. In R, this task involves the following:
- Selecting a data structure to hold your data
- Entering or importing your data into the data structure
Data structures
R has a wide variety of objects for holding data, including scalars, vectors, matrices, arrays, data frames, and lists. They differ in terms of the type of data they can hold, how they are created, their structural complexity, and the notation used to identify and access individual elements.
R data structures:
- vector
- matrix
- data frame
- array
- list
Vectors
Vectors are one-dimensional arrays that can hold numeric data, character data, or logical data. The combine function: c(…) is used to form the vector.
# numeric data
vec.num <- c(1, 2, 5, 3, 6, -2, 2.3)
vec.num## [1] 1.0 2.0 5.0 3.0 6.0 -2.0 2.3# character data
vec.char <- c("one", "two", "three")
vec.char## [1] "one" "two" "three"# What happen if we combine different types of data?
##
# vectors can be created with numeric and logic operators:
vec.oper <- c(2/5, 3, 5+3, 4-7, 4 == 4.01, 3.5 < 3.5001, "data" < "2data")
vec.oper## [1] 0.4 3.0 8.0 -3.0 0.0 1.0 0.0# vectors can be created with the content of variables:
vec.var <- c(equal, a, b, today.days)
vec.var## [1] 0.00000 23.66667 24.33333 18195.00000# the function seq(...) can be used to create vectors:
vec.seq <- seq(3, 4.5, 0.2) # c(...) is not necessary
vec.seq## [1] 3.0 3.2 3.4 3.6 3.8 4.0 4.2 4.4You can refer to elements of a vector using a numeric vector of positions within brackets.
# vector created from simple sequence
vec.ref <- c(3:11)
vec.ref## [1] 3 4 5 6 7 8 9 10 11# locate the first three elements and last two elements
# first we need the length of the vector:
length(vec.ref)## [1] 9# now we can look for the elements:
vec.ref[c(1:3, 8, 9)]## [1] 3 4 5 10 11# another way:
vec.ref[-(4:7)]## [1] 3 4 5 10 11We can do operations with vectors.
# multiplying two vectors
f <- c(1, 2, 3, 5, 7)
g <- c(2, 4, 6, 8, 10)
vec.mult <- f * g
vec.mult## [1] 2 8 18 40 70# What happen if vectors are of different length?#####where to look in the book?: chapter 4
Matrices
A matrix is a two-dimensional array in which each element has the same class (numeric, character, or logical). Matrices are created with the matrix(…) function. The general format is:
mymatrix <- matrix(vector,
nrow=number of rows,
ncol=number of columns,
byrow=logical value,
dimnames=list(character vector of row names, character vector of column names)
)
# data vector - [age,glu,chol]
vec.diabetes <- c(32,90,160,26,130,200,40,200,180,55,150,260)
# name vectors
RowN <- c("patient 1","patient 2","patient 3","patient 4")
ColN <- c("Age","Glucose","Cholesterol")
# matrix
mtx.diabetes <- matrix(vec.diabetes,
ncol = 3,
byrow = TRUE,
dimnames = list(RowN,ColN)
)
mtx.diabetes## Age Glucose Cholesterol
## patient 1 32 90 160
## patient 2 26 130 200
## patient 3 40 200 180
## patient 4 55 150 260class(mtx.diabetes)## [1] "matrix" "array"Data selection from a matrix, is similar as vectors, but now we must specify rows and columns.
# selecting all rows and two columns
new.matrix1 <- mtx.diabetes[ ,2:3]
new.matrix1## Glucose Cholesterol
## patient 1 90 160
## patient 2 130 200
## patient 3 200 180
## patient 4 150 260# selecting first and last patient, and age and cholesterol
new.matrix2 <- mtx.diabetes[c(1,4),c(1,3)]
new.matrix2## Age Cholesterol
## patient 1 32 160
## patient 4 55 260Data frames
A data frame is more general than a matrix in that different columns can contain different classes of data (numeric, character, and so on). Data frames are the most common data structure you will deal with in R. A data frame is created with the data.frame(…) function:
mydata <- data.frame(col1, col2, col3,…)
where col1, col2, col3, and so on are column vectors of any type (such as character, numeric, or logical).
# column vectors
ID <- c(1L,2L,3L,4L)
chol <- c(160, 200, 180, 260)
glu <- c(90, 130, 200, 150)
age <- c(32,26,40,55)
sex <- c("M","F","M","M")
diabetes <- c("neg","pos","pos","neg")
# data frame from vectors
patientdata <- data.frame(ID, age, sex, glu, chol, diabetes)
class(patientdata)## [1] "data.frame"patientdata## ID age sex glu chol diabetes
## 1 1 32 M 90 160 neg
## 2 2 26 F 130 200 pos
## 3 3 40 M 200 180 pos
## 4 4 55 M 150 260 neg# changing the name of the columns
new.patiendata <- setNames(patientdata, c("Patient ID","Age","Birth Sex","Blood Glucose","Cholesterol","Diabetes Diagnosis"))
new.patiendata## Patient ID Age Birth Sex Blood Glucose Cholesterol Diabetes Diagnosis
## 1 1 32 M 90 160 neg
## 2 2 26 F 130 200 pos
## 3 3 40 M 200 180 pos
## 4 4 55 M 150 260 negData selection from a data frame is similar to selection from a matrix, but also is possible to do logical selections using factor columns.
# selecting columns by name
select.df1 <- new.patiendata[ ,c("Blood Glucose","Diabetes Diagnosis")]
select.df1## Blood Glucose Diabetes Diagnosis
## 1 90 neg
## 2 130 pos
## 3 200 pos
## 4 150 neg# selecting using logical operator
select.df2 <- new.patiendata[new.patiendata$`Diabetes Diagnosis`=="pos",]
select.df2## Patient ID Age Birth Sex Blood Glucose Cholesterol Diabetes Diagnosis
## 2 2 26 F 130 200 pos
## 3 3 40 M 200 180 pos#####where to look in the book?: chapter 5
Data input
R provides a wide range of tools for importing data, and create data
frames. The definitive guide for importing data in R is the R Data
Import/Export manual available at http://mng.bz/urwn.
We are considering three tools to input data for analyses:
- manually: as we did before with the matrix and data frame examples.
- reading text file with comma separated values (read.csv)
- import Excel files using the Import Dataset menu, in the Environment tab (usually upper-right component of RStudio)
El proceso de Investigación
Reading CSV files
CSV files are text files where values in each line are separated by commas (i.e. 1,2,3,5,7,11), and have a carriage return code at the end of each line. The file can be created with any text editor or exported from a spreadsheet application (Excel, for example). To read a CSV file use the following basic code:
library(readr)
honeymoondata <- read_csv("Data/honeymoon.csv")## Rows: 115 Columns: 6
## ── Column specification ─────────────────────────────────────────────────────────────────────────────────────
## Delimiter: ","
## dbl (6): Person, Satisfaction_Base, Satisfaction_6_Months, Satisfaction_12_M...
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.dim(honeymoondata)## [1] 115 6head(honeymoondata)## # A tibble: 6 × 6
## Person Satisfaction_Base Satisfaction_6_Months Satisfaction_12_Months
## <dbl> <dbl> <dbl> <dbl>
## 1 1 6 6 5
## 2 2 7 7 8
## 3 3 4 6 2
## 4 4 6 9 4
## 5 5 6 7 6
## 6 6 5 10 4
## # ℹ 2 more variables: Satisfaction_18_Months <dbl>, Gender <dbl>class(honeymoondata)## [1] "spec_tbl_df" "tbl_df" "tbl" "data.frame"Import data from Excel file
RStudio provides a menu driven tool to import data from an Excel file (and other types, too). It requires that you have installed and activate the readxl package. Use the menu Import Dataset, select the File, select the Sheet with the data you are interested in, and check First Row as Names if that is the case.
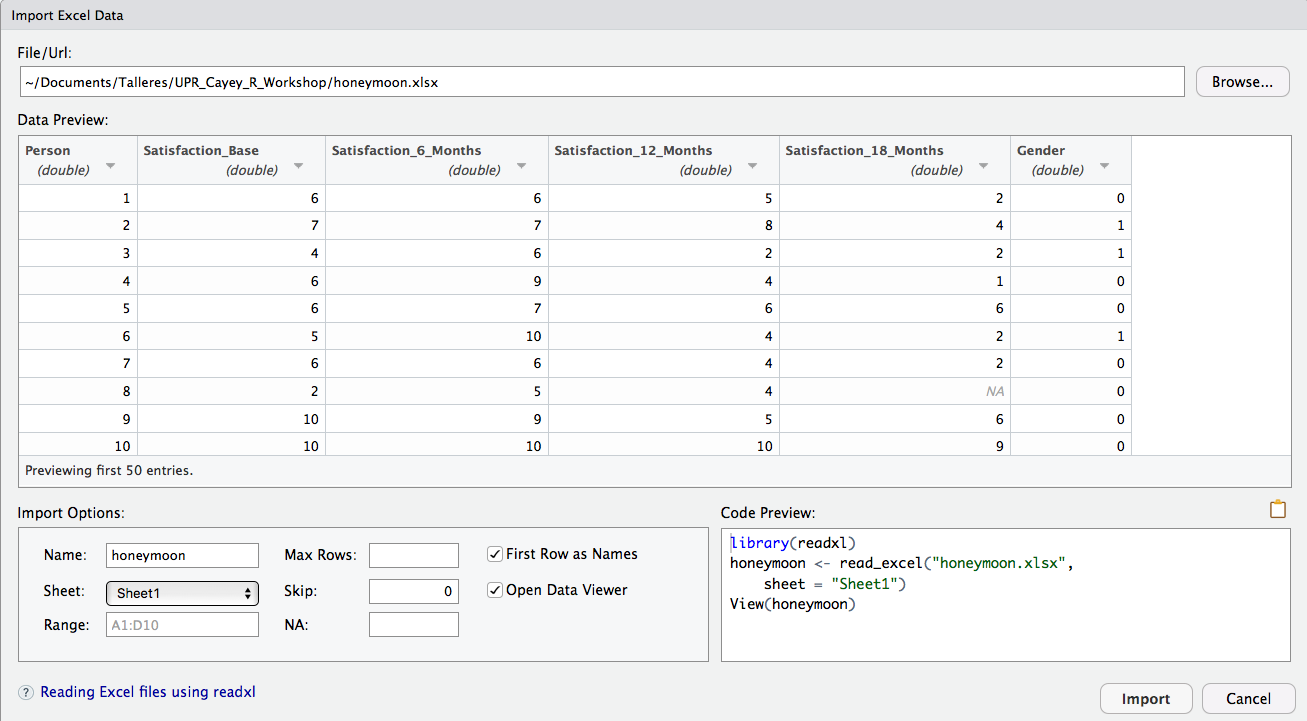
El proceso de Investigación
These menu actions will generate a code that you can use inside your procedure.
library(readr)
melocactus <- read_csv("Data/melocactus.csv")## Rows: 145 Columns: 5
## ── Column specification ─────────────────────────────────────────────────────────────────────────────────────
## Delimiter: ","
## chr (1): estado
## dbl (4): azimuto, distancia, alturatotal, longinflo
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.melodata=melocactus
class(melodata)## [1] "spec_tbl_df" "tbl_df" "tbl" "data.frame"head(melodata)## # A tibble: 6 × 5
## azimuto distancia alturatotal longinflo estado
## <dbl> <dbl> <dbl> <dbl> <chr>
## 1 0 12.0 20 5 S
## 2 0 11.6 47 10 S
## 3 0 17.8 27 16 X
## 4 2 2.75 48 29 S
## 5 3 2.71 23 0 S
## 6 3 2.71 16 0 Stail(melodata)## # A tibble: 6 × 5
## azimuto distancia alturatotal longinflo estado
## <dbl> <dbl> <dbl> <dbl> <chr>
## 1 355 6 43 11 S
## 2 355 4 44 15 E
## 3 355 4.5 46 22 E
## 4 355 2.5 21 0 E
## 5 355 2.5 46 11 E
## 6 358 5 6 0 S#####where to look in the book?: chapter 6
Descriptive Statistics
R has a large number of ways to calculate descriptive statistics on the datasets, some are included in the basic installation, and others in packages that need download-installation (using install.packages(…) or the Package menu) and load (activation) to the R environment (using library(…)).
Using summary
summary is the simplest way to obtain some descriptive statistics from our data.
# select the columns (variable) to analyze
melovars <- c("alturatotal","longinflo")
# use summary
summary(melodata[melovars])## alturatotal longinflo
## Min. : 3.00 Min. : 0.000
## 1st Qu.:11.00 1st Qu.: 0.000
## Median :18.00 Median : 0.000
## Mean :21.93 Mean : 5.966
## 3rd Qu.:30.00 3rd Qu.:11.000
## Max. :69.00 Max. :35.000Using sapply and a function
A more general way to calculate descriptive statistics is using the sapply procedure, with the syntax:
sapply(x, FUN, options))
where FUN is a simple system function (like mean(var), sd(var), et c.) or an user-defined function, with the following syntax:
myfunction <- function(arg1, arg2, … ){
statements
return(object)
}
# defining function
mystats <- function(x){
m <- mean(x)
md <- median(x)
n <- length(x)
s <- sd(x)
return(c(n=n, mean=m, median=md, stdev=s))
}
# sapply function on dataset
sapply(melodata[melovars], mystats)## alturatotal longinflo
## n 145.00000 145.000000
## mean 21.93103 5.965517
## median 18.00000 0.000000
## stdev 14.18120 8.065198We can select some of the data to apply the statistics.
# select plants with longitude of inflorescence different from 0
melo.inflo <- melodata[melodata$longinflo > 0,"longinflo"]
# sapply function mystats
sapply(melo.inflo, mystats)## longinflo
## n 69.000000
## mean 12.536232
## median 11.000000
## stdev 7.359627Using aggregate
When you have variables that can be considered as factor, you can use the aggregate function to obtain basic statistics aggregating by such factors. The function has the following syntax:
aggregate(x, by, FUN)
# calculate the mean of plant heights (alturatotal) by plant status (estado)
aggdata <- aggregate(melodata$alturatotal, by = list(melodata$estado), mean)
aggdata## Group.1 x
## 1 E 21.92593
## 2 S 23.04000
## 3 X 20.00000# we can change the names of columns
aggdata <- setNames(aggdata, c("Plant Status","Mean Height, cm"))
aggdata## Plant Status Mean Height, cm
## 1 E 21.92593
## 2 S 23.04000
## 3 X 20.00000Using a data.table
The data.table package allows for an improved functionality of data.frames operations. First, we have to convert a data.frame into a data.table. Thereafter you can select subgroups and apply functions to them.
# activate data.table package
library(data.table)##
## Attaching package: 'data.table'## The following objects are masked from 'package:lubridate':
##
## hour, isoweek, mday, minute, month, quarter, second, wday, week,
## yday, year## The following objects are masked from 'package:dplyr':
##
## between, first, last## The following object is masked from 'package:purrr':
##
## transpose# conver data.frame o data.table
melodataDT <- data.table(melodata)
class(melodataDT)## [1] "data.table" "data.frame"# descriptive statistics by groups
meloDS <- melodataDT[, list(Media=mean(alturatotal), Median=median(alturatotal), StDev=sd(alturatotal)), by=list(Status=estado)]
meloDS## Status Media Median StDev
## 1: S 23.04000 18 15.52456
## 2: X 20.00000 17 11.01298
## 3: E 21.92593 18 14.90722# ordering results
meloDS[order(Media)]## Status Media Median StDev
## 1: X 20.00000 17 11.01298
## 2: E 21.92593 18 14.90722
## 3: S 23.04000 18 15.52456#####where to look in the book? chapters 11, 18
Introduction to graphs
R is a great platform for building graphs. Literally, in a
typical interactive session, you build a graph one statement at a time,
adding features, until you have what you want.
The base graphics system of R is described at the
beginning of chapter 7 in the Lander’s book. Two other
systems, that are widely used, and provide extensive options are lattice
and ggplot2.
We will be mostly using the base graphics system and ggplot2.
The primary graph for a variable: the histogram
Histograms display the distribution of a continuous variable by dividing the range of scores into a specified number of bins on the x-axis and displaying the frequency of scores in each bin on the y-axis.
Introducing ggplot2: building a histogram
Now we are going to build a histogram using ggplot2. ggplot2 provides a system for creating graphs based on the grammar of graphics. The intention of the ggplot2 package is to provide a comprehensive, grammar-based system for generating graphs in a unified and coherent manner, allowing users to create new and innovative data visualizations. The power of this approach has led ggplot2 to become an important tool for visualizing data using R.
First, let see a basic ggplot2 histogram:
# activating ggplot2
library(ggplot2)
# basic histogram
ggplot(melodata, aes(alturatotal))+
geom_histogram(color="white", bins = 14)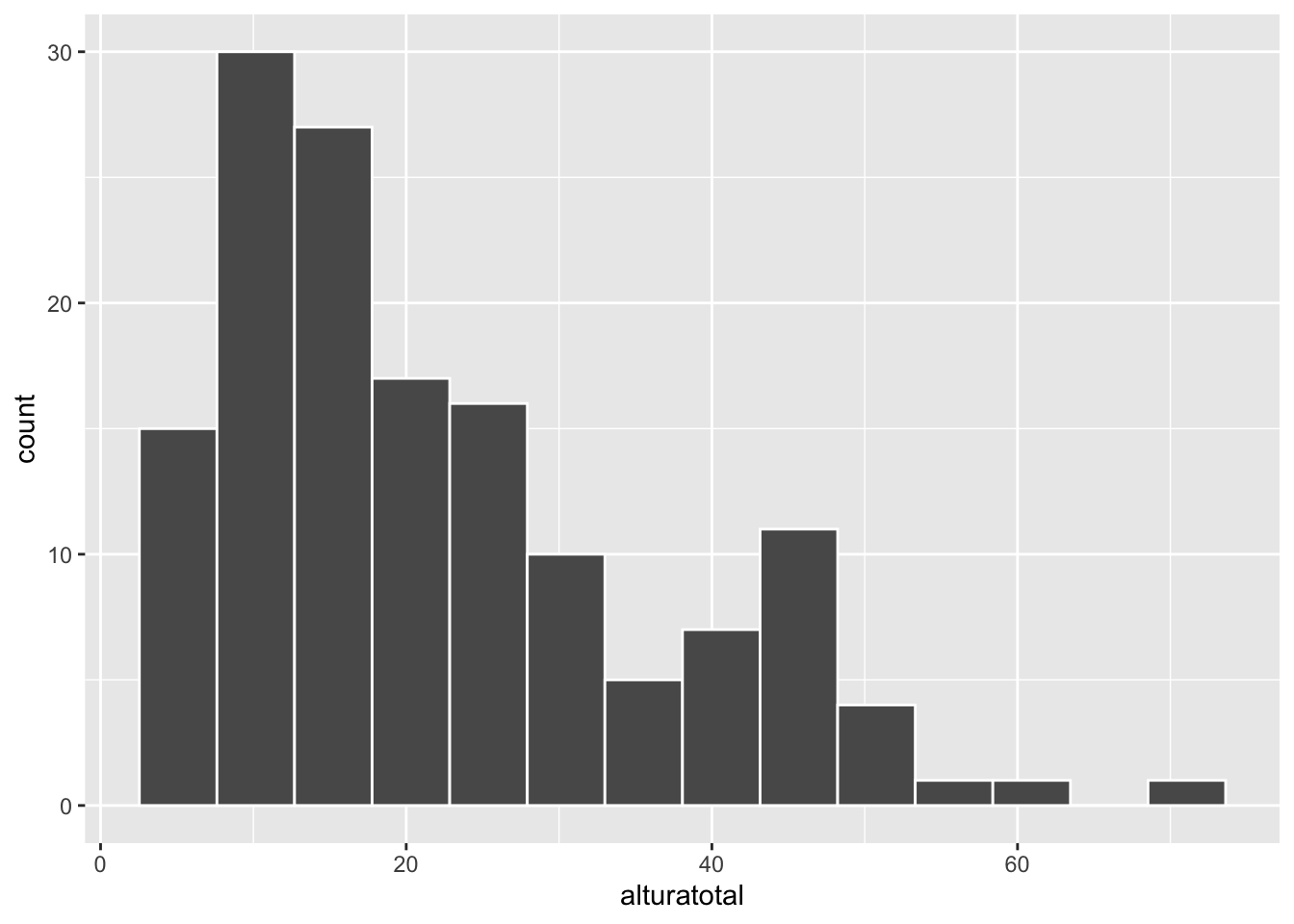 Now a more detailed histogram, including several layers:
Now a more detailed histogram, including several layers:
hist.melodata <- ggplot(melodata, aes(alturatotal)) +
geom_histogram(aes(y=..density..), bins = 14, colour="white", fill="green") +
geom_rug(sides = "t", color = "black") +
labs(x="Total heigth,cm", y = "Density") +
stat_function(fun = dnorm,
args = list(mean = mean(melodata$alturatotal, na.rm = TRUE),
sd = sd(melodata$alturatotal, na.rm = TRUE)),
colour = "red", size = 1)## Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
## ℹ Please use `linewidth` instead.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was generated.hist.melodata## Warning: The dot-dot notation (`..density..`) was deprecated in ggplot2 3.4.0.
## ℹ Please use `after_stat(density)` instead.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was generated.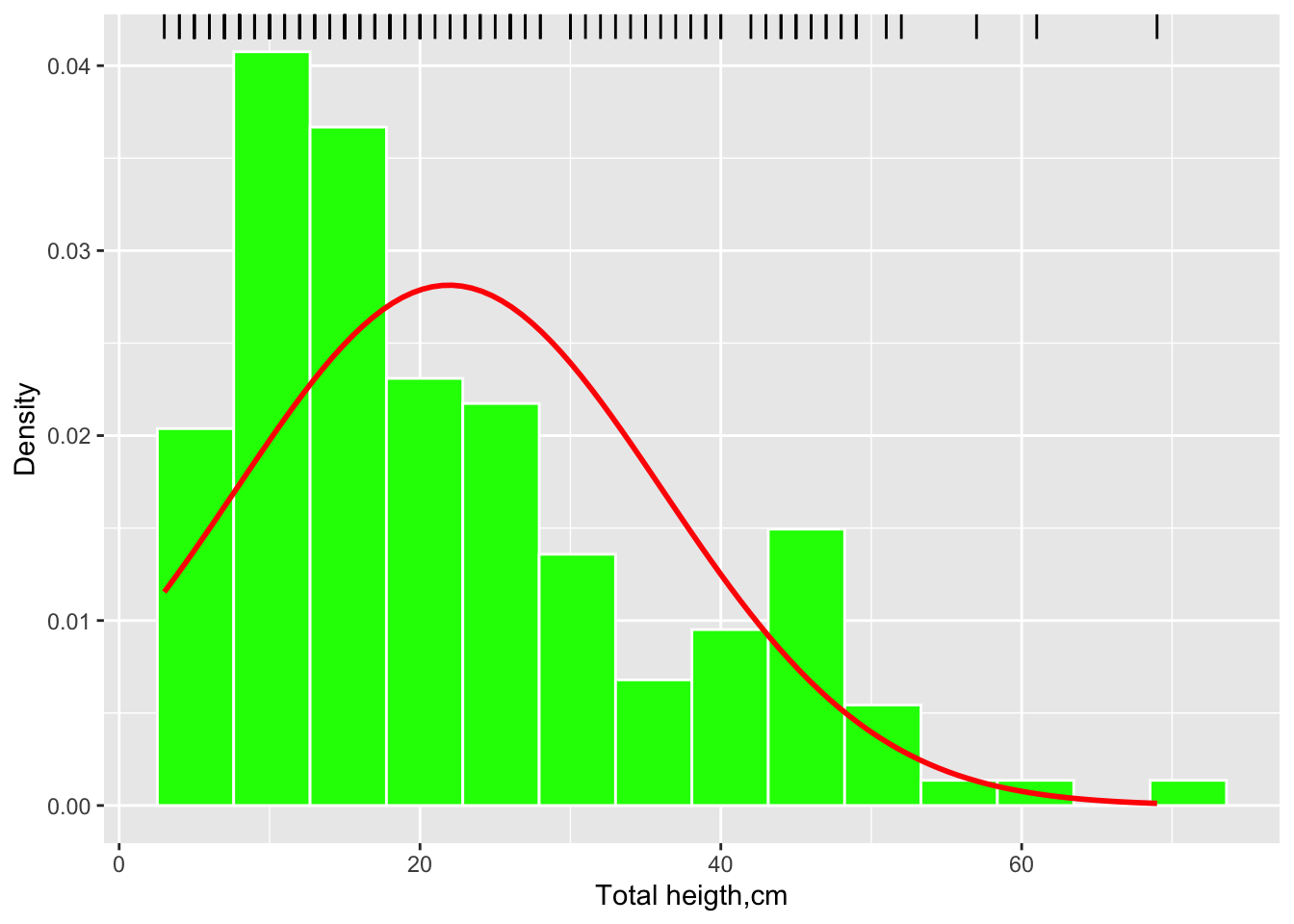
The popular graph: bars with errors
Descriptive statistics are usually graph using bars (for the means), and up and down lines for some measure of deviation or error (standard deviation, standard error, or confidence interval).
# summarySE provides the standard deviation, standard error of the mean, and a (default 95%) confidence interval
library(ggplot2)
library(Rmisc)## Loading required package: lattice## Loading required package: plyr## ------------------------------------------------------------------------------## You have loaded plyr after dplyr - this is likely to cause problems.
## If you need functions from both plyr and dplyr, please load plyr first, then dplyr:
## library(plyr); library(dplyr)## ------------------------------------------------------------------------------##
## Attaching package: 'plyr'## The following objects are masked from 'package:dplyr':
##
## arrange, count, desc, failwith, id, mutate, rename, summarise,
## summarize## The following object is masked from 'package:purrr':
##
## compact# statistics for the bars&errors graph
melo.bars <- summarySE(melodata, measurevar="alturatotal", groupvars="estado")
melo.bars## estado N alturatotal sd se ci
## 1 E 27 21.92593 14.90722 2.868895 5.897098
## 2 S 75 23.04000 15.52456 1.792622 3.571876
## 3 X 43 20.00000 11.01298 1.679464 3.389295# Error bars represent standard error of the mean
ggplot(melo.bars, aes(x=estado, y=alturatotal)) +
geom_bar(position=position_dodge(), stat="identity", fill="cornflowerblue",
width=0.5) +
geom_errorbar(aes(ymin=alturatotal-se, ymax=alturatotal+se),
width=.2, # Width of the error bars
position=position_dodge(.9)) +
scale_x_discrete("Plant Condition") +
scale_y_continuous("Plant Heigth, cm")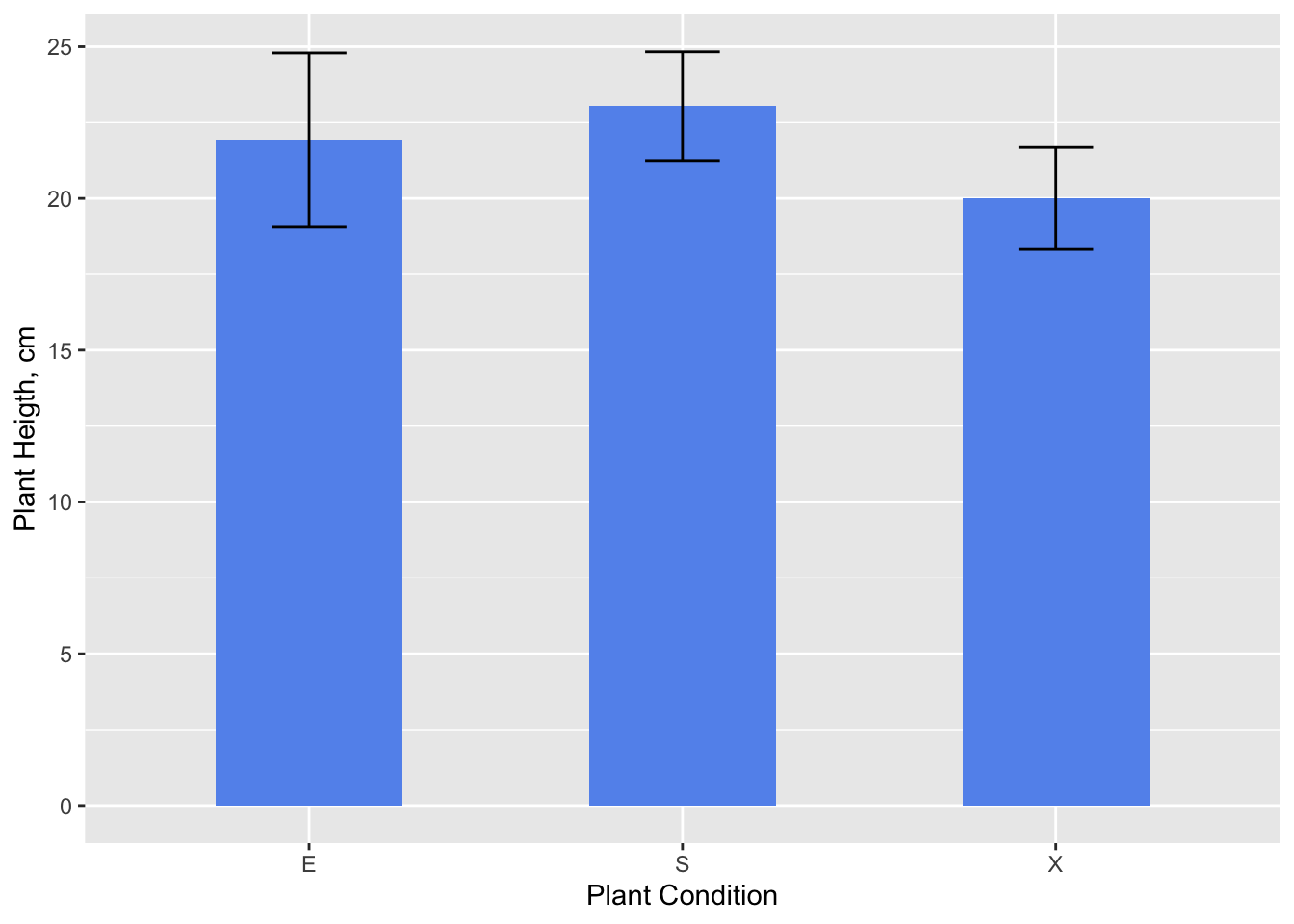
#####where to look in the book? chapter 7
Homework
Here is an assigment to complete, and send me for review.
- Look in your kitchen, fridge, or elsewhere, for food with nutrition labels (Nutrition Facts).
- Find ten canned (sealed) foods, ten in boxes or bags (dry food), and ten beverages or creamy (liquids).
- For each item, take note of the values for calories per serving, serving size (g), total fat (g), cholesterol (mg), sodium (mg), total carbohydrates (g), and protein (g), for each food.
- Create an Excel workbook with the data, using the template: Template for Food Data
References
Kabacoff, R., 2015. R in action: data analysis and graphics with R, Second edition. ed. Manning, Shelter Island.
Lander, J. P., 2014.R for everyone. Pearson Education, Inc., Upper Saddle River, NJ, USA.
Verzani, J., 2012. Getting started with RStudio. O’Reilly, Sebastopol, Calif.
Xie, Y., J. J. Allaire, G. Grolemund, 2018. R Markdown: The Definitive Guide. Chapman & Hall/CRC.