Regresión Lineal

![]()
Fecha de la ultima revisión
## [1] "2023-08-22"El siguiente comando verifica que tenga las librerias necesarias instaladas y las activa de estar disponible en su sistema. El paquete pacman evalúa si los tiene instalado y los instala de ser necesario.
if (!require("pacman")) install.packages("pacman")
pacman::p_load(QuantPsyc, car, ggplot2, tidyverse, sjPlot, janitor)
library(QuantPsyc)
library(car)
library(ggplot2)
library(tidyverse)
library(sjPlot)
library(janitor)Regresión Lineal
La regresión lineal es el modelo básico para evaluar si hay una relación lineal o sea una linea recta entre dos variables. Esta relación entre las variables puede ser positiva o negativa. Hay otros tipos de regresión, que incluye regresión no lineal tal como cuadrática \(y ~ ax^2+bx+c\) o cúbica \(y ~ ax^3 +bx^2+cx+d\), logarítmica \(y ~ a + blog(x)\) entre muchas otras alternativas. Estas alternativas se verán en el modulo de regresión no lineal.
Aquí estaremos evaluando solamente la regresión lineal
Vemos un ejemplo ficticio
Los datos son de unos barrios de Macondo donde se observa el números de barras en un bario y la cantidad de homicidios en ese barrio. Los datos se encuentran la sección de datos abajo
## Rows: 8 Columns: 2
## ── Column specification ─────────────────────────────────────────────────────────────────────────────────────
## Delimiter: ","
## dbl (2): pubs, mortality
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.| pubs | mortality |
|---|---|
| 10 | 1e+03 |
| 20 | 2e+03 |
| 30 | 3e+03 |
| 40 | 4e+03 |
| 50 | 5e+03 |
| 60 | 6e+03 |
| 70 | 7e+03 |
| 500 | 1e+04 |
# Cambiamos los nombres de las columnas al español
pubs=pubs%>%
dplyr::rename(barras=pubs, mortalidad=mortality) # cambiamos los nombres de las columnas al español.
pubs| barras | mortalidad |
|---|---|
| 10 | 1e+03 |
| 20 | 2e+03 |
| 30 | 3e+03 |
| 40 | 4e+03 |
| 50 | 5e+03 |
| 60 | 6e+03 |
| 70 | 7e+03 |
| 500 | 1e+04 |
la función lm()
Hacer un regresión lineal (Linear Regression) simple, usando la función lm(), para “linear model”= modelo lineal. Una regresión necesita dos variable continuas. Es importante que estas variables tengan una distribución normal. La diferencia entre una correlación y una regresión es que la primera es un análisis que describe el patrón general entre las variables y en la segunda es que no solamente se describe el patrón pero se hace una predicción sobre la relación entre las variables. Usando la regresión uno calcula también una linea que describe la relación entre las variables. Esta variable se puede describe como \(y=m_x+b\) donde la m representa la pendiente y la b representa el intercepto. También lo pueden ver en libros de la siguiente forma \(y=\alpha+\beta_x\) donde la \(\beta\) beta representa la pendiente y la \(\alpha\) el intercepto, este es el método preferido en los libros en ingles.
La función en R de regresión lineal es lm() se compone de lm(y~x, data= “df”). Nota la tilde ~. Hay dos pruebas la primera es para determinar si \(\alpha\) es distinto de cero. La hipótesis nula es
- Ho: el intercepto \(\alpha\) es igual a cero
- Ha: el intercepto, \(\alpha\) no es igual a cero. Entonces el punto donde la linea intercepta el cero puede estar mayor de o menor de cero.
La segunda hipótesis nula es que la pendiente es diferente de cero, esto quiere decir que la pendiente no sugiere/apoya un patrón de aumentar y disminuir entre las dos variables.
- Ho: la pendiente \(\beta\) es igual a cero
- Ha: la pendiente, \(\alpha\) no es igual a cero. Entonces la relación entre las dos variables es o positiva o negativa.
Ahora evaluamos los resultados de la regresión entre el número de barras en un vecindarios (los barrios) y la mortalidad en este mismo sector. Se observa que los coeficientes de la linea son \(y=3352+14.3*x\). Entonce el intercepto en cero comienza en 3352 fatalidades y por cada barra adicional hay 14.3 más fatalidades. Esto significa que si no hay barras la x=0, la cantidad de fatalidades esperada es de 3352.
Ahora para determinar si estos valores son significativo hay que evaluar el valor de p en cada linea. La hipótesis nula del intercepto tiene un valor de p =0.005, que sugiere que se debería rechazar la hipótesis nula, y por consecuencia aceptamos la hipótesis alterna, que el intercepto no es igual a cero. La pendiente tiene un valor de p=0.015 y también se rechaza la hipótesis nula, esto sugiere que a medida que aumenta la cantidad de barras aumenta la cantidad de fatalidades, por cada barra adicional esperamos 14.3 fatalidades adicionales.
pubReg <- lm(mortalidad~barras, data = pubs)
summary(pubReg) # Si no se acuerda de la función que sigue use la siguiente función (que es más sencilla)##
## Call:
## lm(formula = mortalidad ~ barras, data = pubs)
##
## Residuals:
## Min 1Q Median 3Q Max
## -2495.3 -996.3 -223.5 1145.2 2644.3
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 3351.955 781.236 4.291 0.00515 **
## barras 14.339 4.301 3.334 0.01572 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1864 on 6 degrees of freedom
## Multiple R-squared: 0.6495, Adjusted R-squared: 0.591
## F-statistic: 11.12 on 1 and 6 DF, p-value: 0.01572## 1 2 3 4 5 6 7
## -2495.3445 -1638.7337 -782.1229 74.4879 931.0987 1787.7095 2644.3203
## 8
## -521.4153## 1 2 3 4 5 6
## 2.132784e-01 8.530493e-02 1.814286e-02 1.547980e-04 2.293965e-02 8.092291e-02
## 7 8
## 1.710655e-01 2.271429e+02tab_model(
pubReg,show.df = TRUE,
CSS = list(
css.depvarhead = 'color: red;',
css.centeralign = 'text-align: left;',
css.firsttablecol = 'font-weight: bold;',
css.summary = 'color: blue;'
)
)## Registered S3 method overwritten by 'parameters':
## method from
## predict.kmeans statip| mortalidad | ||||
|---|---|---|---|---|
| Predictors | Estimates | CI | p | df |
| (Intercept) | 3351.96 | 1440.34 – 5263.57 | 0.005 | 6.00 |
| barras | 14.34 | 3.82 – 24.86 | 0.016 | 6.00 |
| Observations | 8 | |||
| R2 / R2 adjusted | 0.649 / 0.591 | |||
Visualización de la regresión
Se observa que hay un aumento en fatalidades con aumento en el número de barras. Pero nota el valor a la derecha que parece ser muy atípico comparado a los otros.
## `geom_smooth()` using formula = 'y ~ x'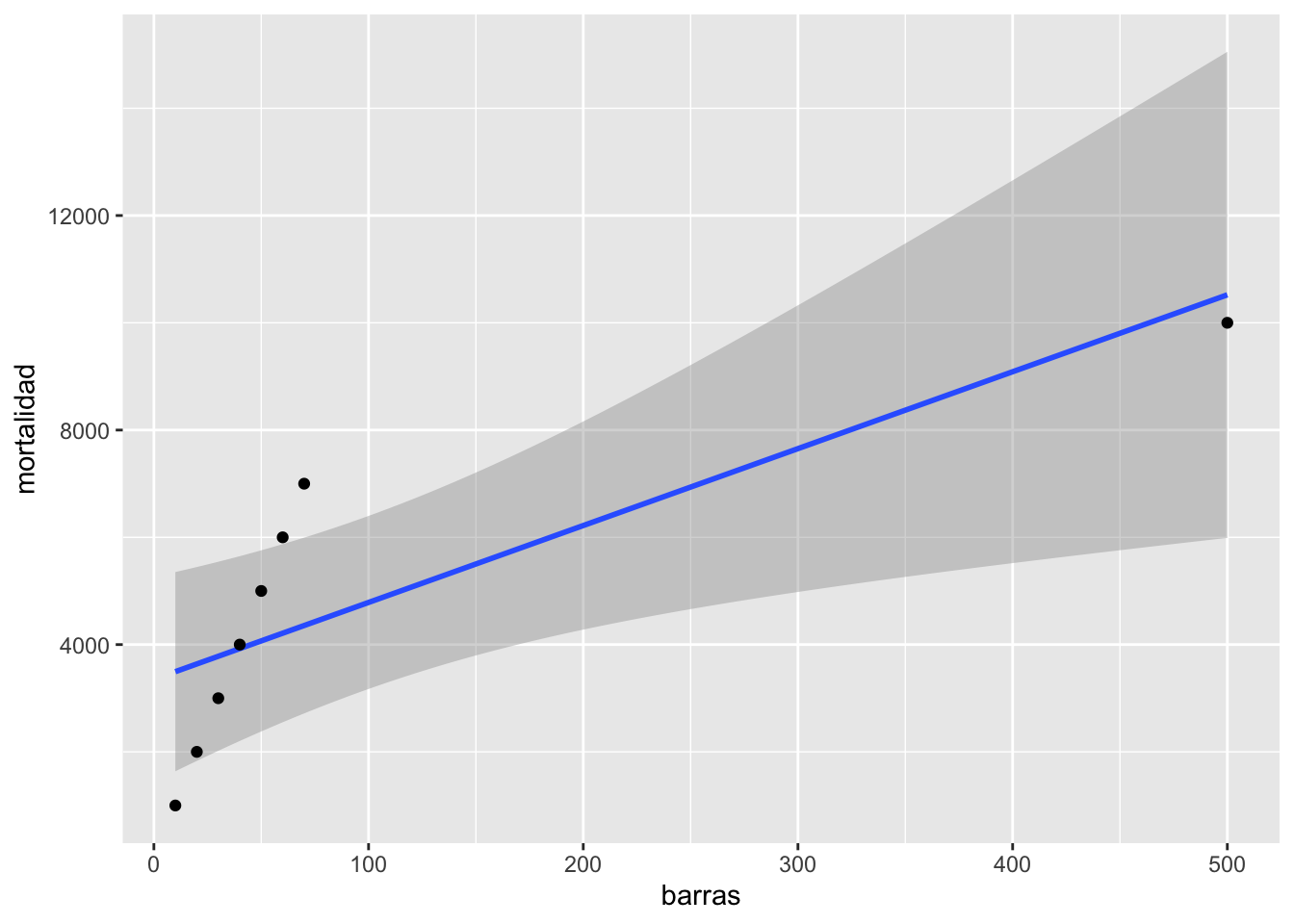
El impacto de valores atípicos
En cierta ocasiones valores fuera de lo normal pueden hacer grandes cambios en el resultado, en este caso el resultado de la regresión. ¿Cual es el efecto del valor grande? Removemos ese valor del archivo de datos y re-evaluamos el modelo (la regresión lineal). Nota que ahora el modelo es sumamente diferente \(y=-163.7+103.2*x\). ¿Ahora se rechazan las dos hipótesis?
pubsnew <- pubs[ which(pubs$barras<80), ] # remover el valor grande
pubsnew=pubsnew %>%
add_row(barras = 4, mortalidad = 0) # Añadiendo un par de valores
pubRegNew <- lm(mortalidad~barras, data = pubsnew)
summary(pubRegNew)##
## Call:
## lm(formula = mortalidad ~ barras, data = pubsnew)
##
## Residuals:
## Min 1Q Median 3Q Max
## -249.11 -36.48 19.57 75.62 131.67
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -163.701 86.000 -1.903 0.106
## barras 103.203 2.055 50.229 4.18e-09 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 128.9 on 6 degrees of freedom
## Multiple R-squared: 0.9976, Adjusted R-squared: 0.9972
## F-statistic: 2523 on 1 and 6 DF, p-value: 4.177e-09tab_model(
pubRegNew,show.df = TRUE,
CSS = list(
css.depvarhead = 'color: red;',
css.centeralign = 'text-align: left;',
css.firsttablecol = 'font-weight: bold;',
css.summary = 'color: blue;'
)
)| mortalidad | ||||
|---|---|---|---|---|
| Predictors | Estimates | CI | p | df |
| (Intercept) | -163.70 | -374.14 – 46.73 | 0.106 | 6.00 |
| barras | 103.20 | 98.18 – 108.23 | <0.001 | 6.00 |
| Observations | 8 | |||
| R2 / R2 adjusted | 0.998 / 0.997 | |||
## `geom_smooth()` using formula = 'y ~ x'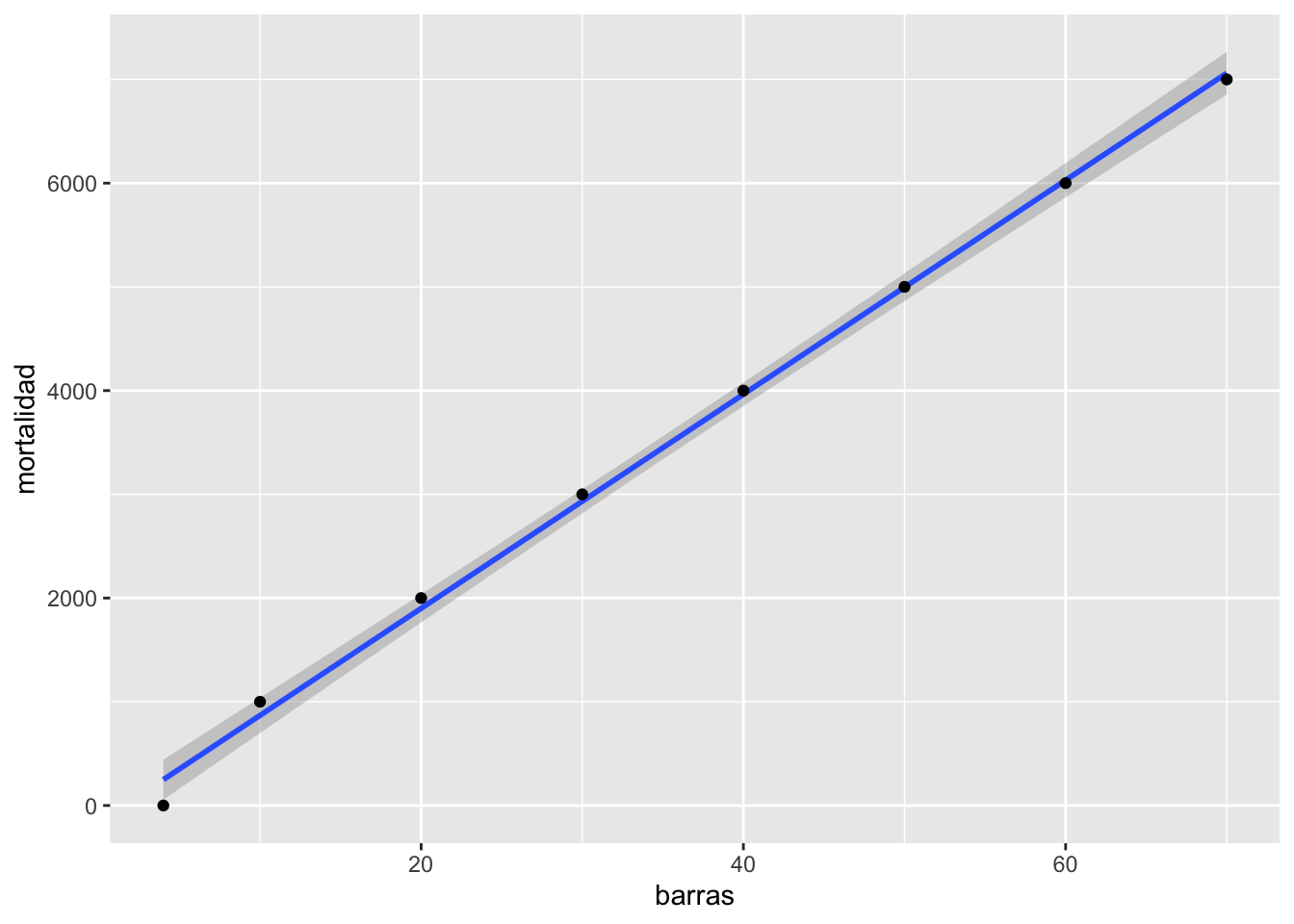
La venta de discos de música
Ahora evaluamos un conjunto de datos más complejo y más realista similar a los que uno encontraría en un estudio en medicina, sociología o ecológica.
Los datos representan la cantidad de dinero dedicado a la promoción de diferentes CD’s de una compañía de música y la cantidad de CD’s (CD/downloads) vendidos. En la primera linea se observa la cantidad de libras esterlina, £ (UK) dedicada a la promoción del álbum de música, en la primera linea vemos que se gastó £10,256, y después la cantidad de CD vendidos fue 330. Tenemos información sobre 200 albumes diferentes.
## Rows: 200 Columns: 4
## ── Column specification ─────────────────────────────────────────────────────────────────────────────────────
## Delimiter: ","
## dbl (4): adverts, sales, airplay, attract
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.| adverts | sales | airplay | attract |
|---|---|---|---|
| 10.3 | 330 | 43 | 10 |
| 986 | 120 | 28 | 7 |
| 1.45e+03 | 360 | 35 | 7 |
| 1.19e+03 | 270 | 33 | 7 |
| 575 | 220 | 44 | 5 |
| 569 | 170 | 19 | 5 |
## [1] 200##
## Shapiro-Wilk normality test
##
## data: Album_Sales_1_new$adverts
## W = 0.92542, p-value = 1.482e-08##
## Anderson-Darling normality test
##
## data: Album_Sales_1_new$adverts
## A = 3.8762, p-value = 1.089e-09Comenzamos graficando la relcacion entre las dos variables. Nota que en la parte de geom_smooth(), tiene que incluir method=lm, esto significa que el método de construir la linea usará la regresión lineal. Se añade a la función lineal \(\epsilon\) que representa los errores de los valores al comparar con la linea que representa el mejor modelo.
\[Y_{ i }=\beta _{ 0 }+\beta _{ 1 }X_{ i }+\epsilon _{ i }\] Recuerda que \(\beta _{ 0 }\) es el intercepto y el \(\beta _{ 1 }x_{ i }\) es la pendiente. El área sombreada es el área de 95% de intervalo de confianza. Esto quiere decir que la mejor linea, intercepto y pendiente podría variar en este rango si repetimos el experimento. Nota aquí todas las alternativas, añadí las dos pendientes extremas, con una pendiente mayor (roja) y una menor (violeta). Cada punto representa la venta de un CD con su correspondiente cantidad dedicada a la promoción. Los \(epsilon\) seria la diferencia entre la mejor linea y el valor original, esto se llama también los residuales.
library(ggplot2)
ggplot(Album_Sales_1_new,aes(x=adverts, y=sales))+
geom_smooth(method=lm, se = TRUE)+
geom_point()+
geom_segment(aes(x=0, y=120, xend=2250, yend=380), colour="red")+
geom_segment(aes(x=0, y=150, xend=2250, yend=320), colour="purple")## `geom_smooth()` using formula = 'y ~ x'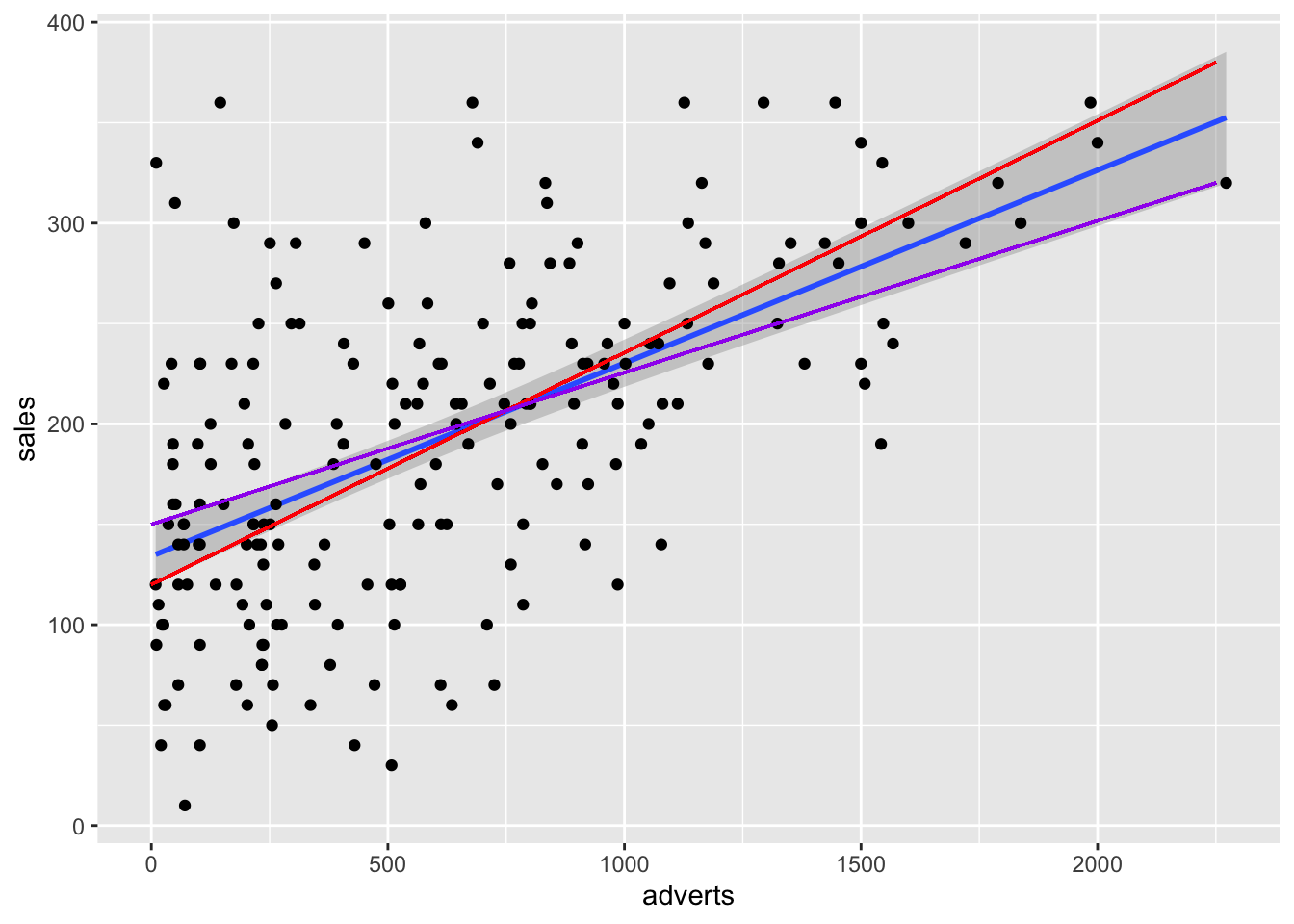
El modelo lineal con la función lm(). ¿Como interpretas los coeficientes y si estos son significativos? ¿se rechaza la hipótesis nula?
library(sjPlot)
model1=lm(sales~adverts, Album_Sales_1_new)
#summary(model1)
tab_model(
model1,show.df = TRUE,
CSS = list(
css.depvarhead = 'color: red;',
css.centeralign = 'text-align: left;',
css.firsttablecol = 'font-weight: bold;',
css.summary = 'color: blue;'
)
)| sales | ||||
|---|---|---|---|---|
| Predictors | Estimates | CI | p | df |
| (Intercept) | 134.14 | 119.28 – 149.00 | <0.001 | 198.00 |
| adverts | 0.10 | 0.08 – 0.12 | <0.001 | 198.00 |
| Observations | 200 | |||
| R2 / R2 adjusted | 0.335 / 0.331 | |||
## `geom_smooth()` using formula = 'y ~ x'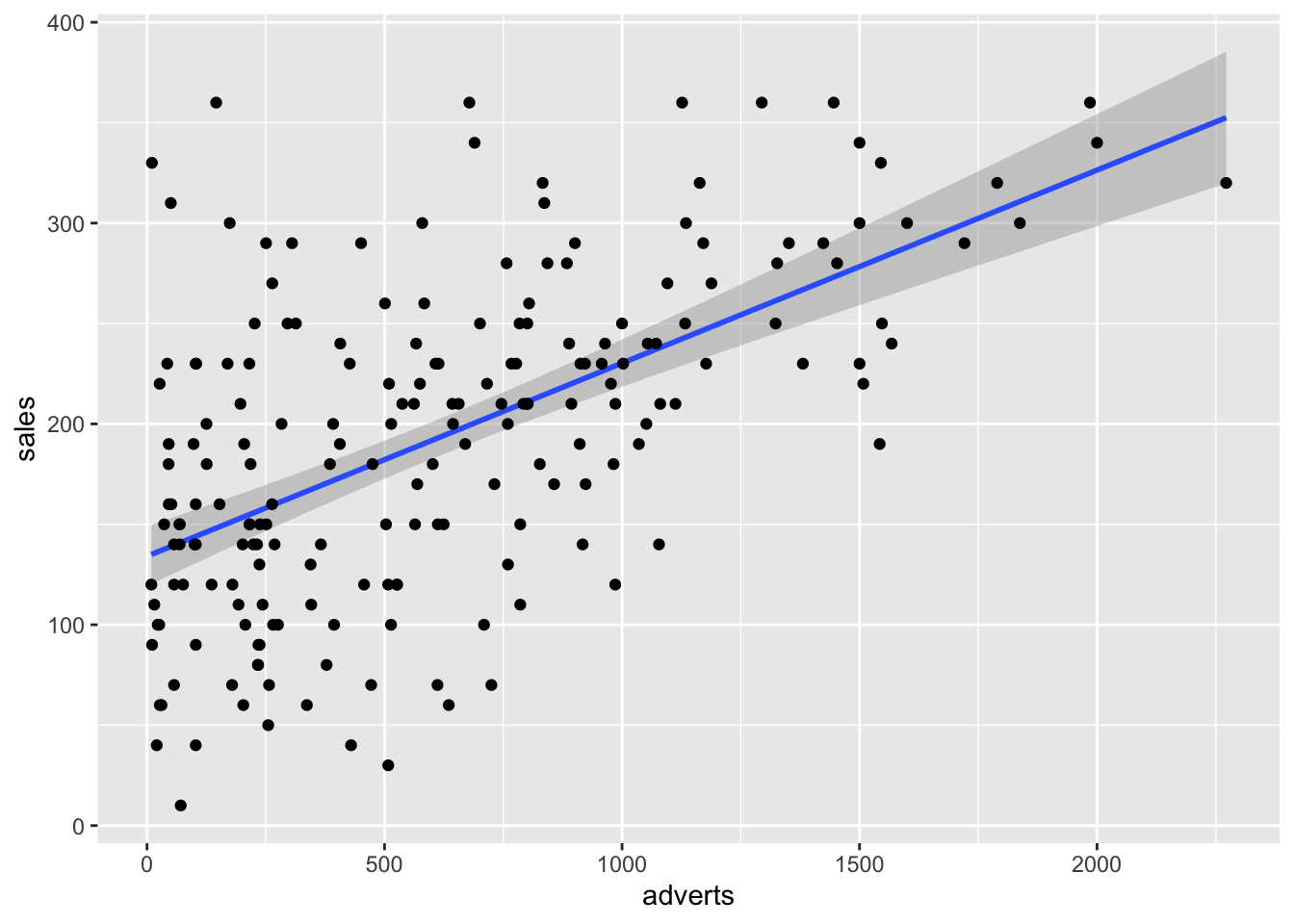
Supuestos de la regresión lineal
Igualdad de varianza: En el primer gráfico debe evaluar si los datos están distribuidos más o menos igual. Osea debe determinar que no hay más variación en un área del gráfico comparando a otra área. Se observa que los datos están más o menos distribuido igualmente por encima y debajo de la linea cero atreves de la distribución de los valores “Fitted”, que son los valores predicho.
Normalidad de los datos, evaluar el gráfico #2. Con el gráfico de qqplot vemos que los datos siguen el modelo nulo (la linea entrecortada) casi perfectamente, Entonces uno puede asumir que los datos cumplen con una distribución normal. Pero nota que los datos en el cuartil superior no están sobre la linea.
Evaluar si hay datos sesgados (atípicos) que influencian los resultados, evaluar el gráfico #3. Si los valores estandarizados de “Student” son mayor de 3, esto sugiere que hay datos atípicos.
En el cuarto gráfico evaluar si hay valores que tienen mucho peso si se incluyen o no en el análisis, evaluar el gráfico #4. Estos van a ser identificados. Los valores con los que hay que preocuparse son los que están por encima o por debajo de la linea entrecortada. En el presente gráfico hay tres valores que hay que evaluar (1, 42, 169), estos valores se tiene que asegurar que son correctos. Siempre es bueno remover los valores sesgados y rehacer el análisis para observar cuan diferente son los resultas. Tipicamente más datos en un análisis , menos peso tendrá un valor sesgado sobre los resultados, al menos que este valor sea muy diferente a la mayoría de los datos.
plot(model1) # Evaluar los supuestos, 1. Igualdad de varianza, 2. Normalidad, 4. Datos sesgados (Cook's Distance)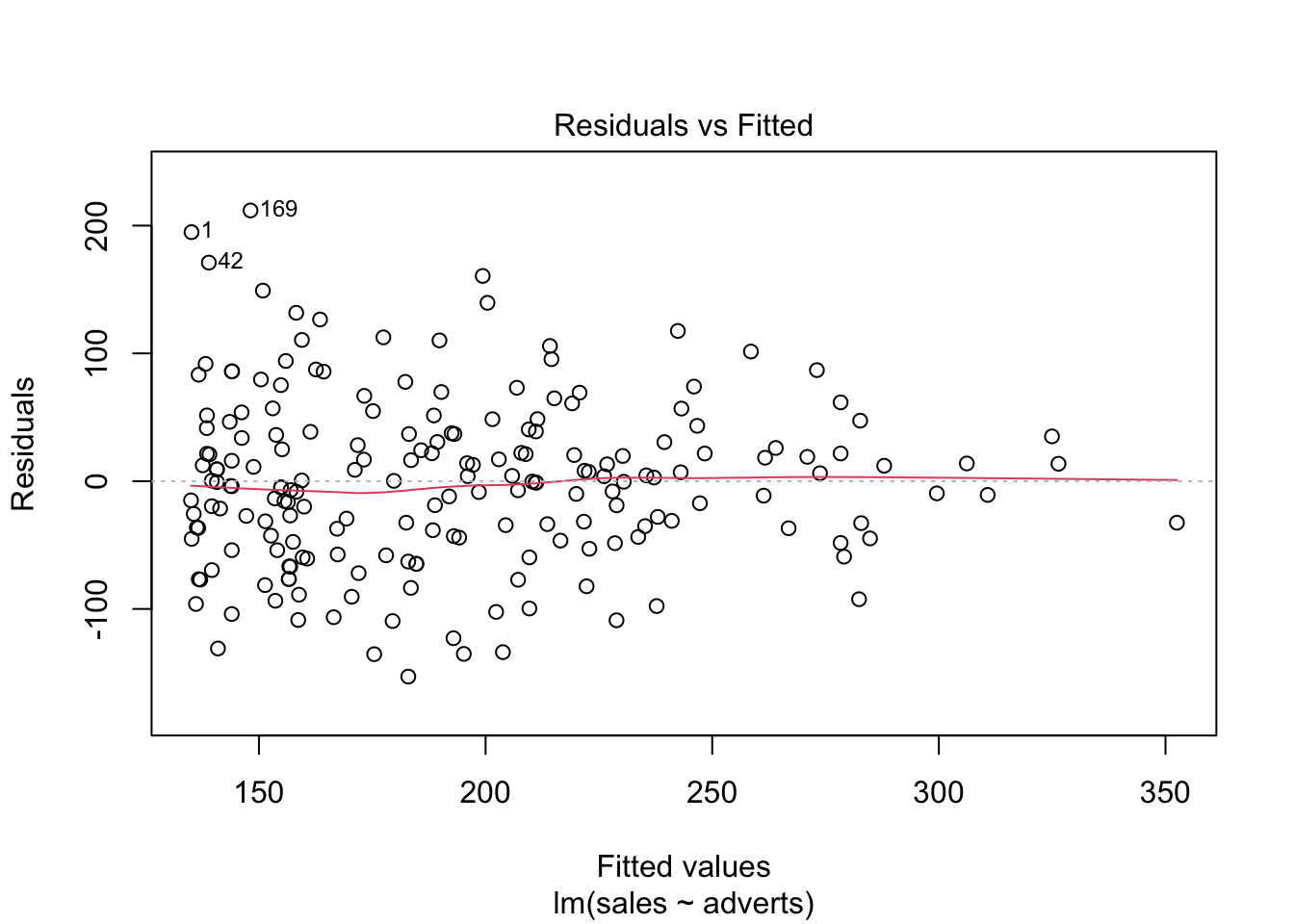
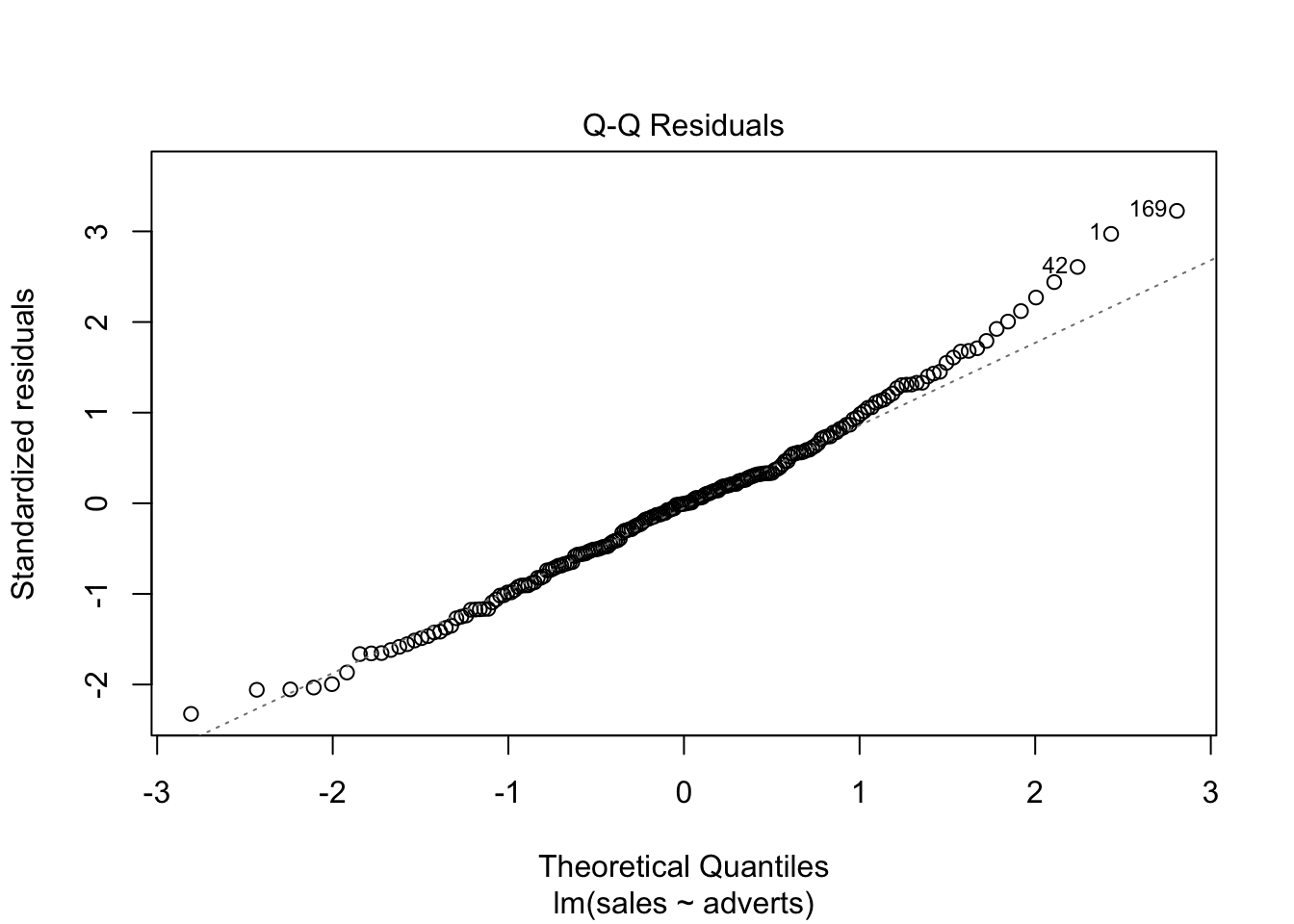
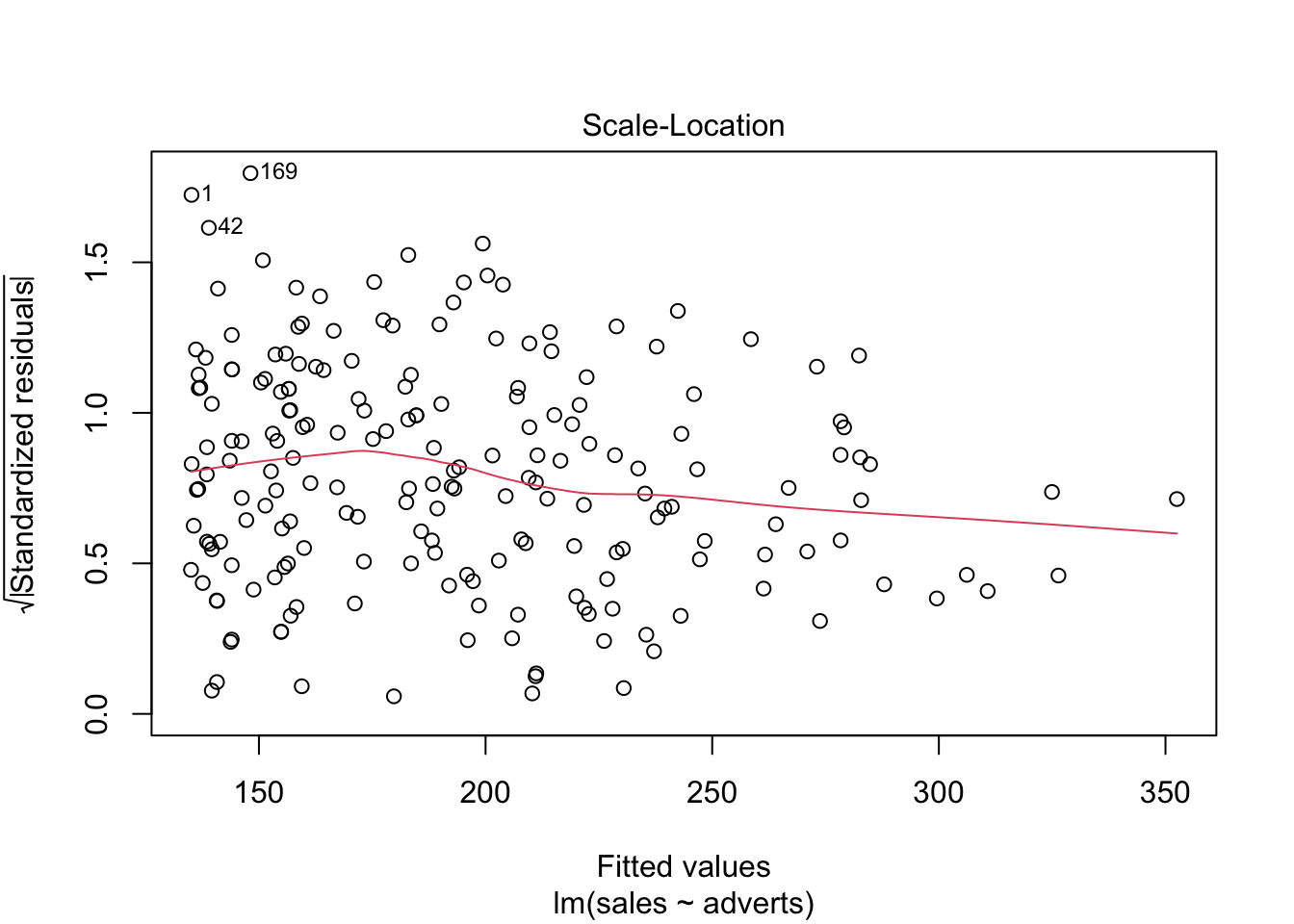
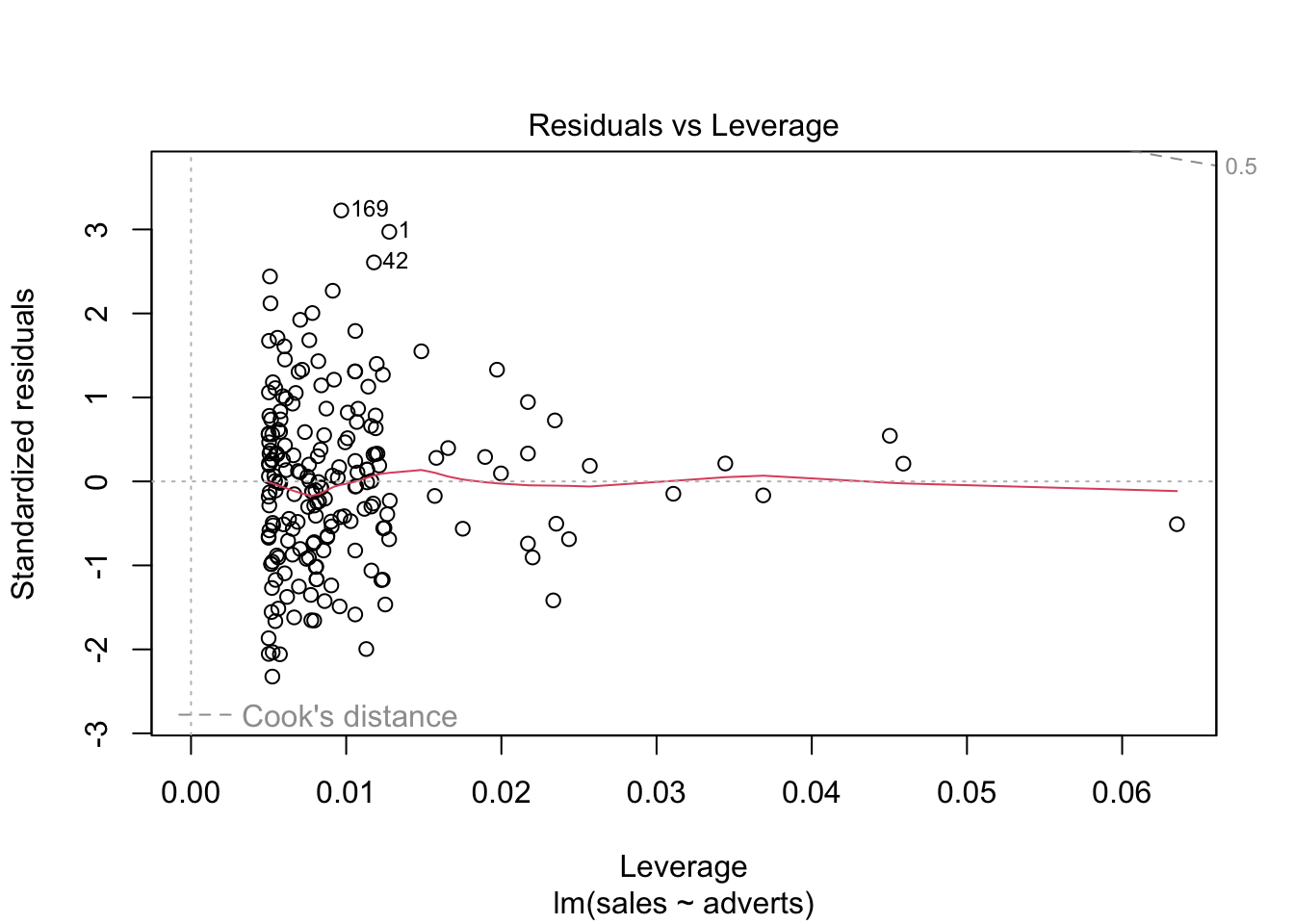
Cook’s Distance (La distancia de Cook)
Continuando con el tema de evaluar si hay valores que podrían influenciar mucho el análisis, podemos utilizar una de las herramientas para evaluar el peso de cada valor sobre una regresión lineal basada en métodos de los mínimos cuadrados, llamada la Distancia de Cook. Este análisis fue desarrollado por R. Dennis Cook en 1977 y tiene como objetivo evaluar cada valor en la matriz de datos y el peso que tiene sobre el resultado (cuando esté este incluido o no en el análisis). Produce un índice para cada uno de los valores sobre el resultado basándose en los valores residuales que se llama la Distancia de Cook. Por lo tanto, ese análisis evalúa el impacto relativo de cada valor sobre el índice. Desafortunadamente no está claro cuál es el valor crítico; o sea, qué valor nos puede indicar que se tiene exceso de peso sobre los resultados. Las dos principales sugerencias son: Distancia de Cook, Di, es mayor a 1 (sugerido por R. Dennis Cook Cook mismo en 1982); y que la Di > 4/n, donde n es el número de observaciones (Bollen et al. 1990).
Para hacer una ilustración, continuaremos con el modelo model1 usando los valores calculados en el modelo anterior. El gráfico se construirá utilizando la opción seq_along, para que los valores en el eje de X se basen en la secuencia de datos en el archivo y los valores en el eje de Y se basen en los valores de la Distancia de Cook. En este caso, vemos que todos los valores están muy por debajo de 1, lo que sugiere que ninguno de los valores individuales influenciaría mucho en los resultados aún si estos fuesen excluidos. Si utilizáramos la segunda alternativa de Di > 4/n, entonces nos deberían preocupar los 6 valores de Di que son mayores a 4/200=0.02, donde 200 es la cantidad de datos en el archivo. Si se considera esta segunda alternativa, sería necesario evaluar 6 valores en la tabla de datos que pudiesen ser sospechosos (los valores encima de la línea roja). Note que no es que están incorrectos; más bien, este resultado es solamente una herramienta para evaluar valores que parecen tener un impacto considerable sobre los resultados.
A continuación se demuestra como añadir
- los valores de “cook.distance” a su archivo
- Añadir una columna de “secuencia” de los datos
- Crear una gráfica de las distancia de Cook.
- Determinar si hay valores de Cook’s \(D_i\) mayor de 1, o 4/n.
## [1] 0.02Album_Sales_1_new$cooks.distance<-cooks.distance(model1)
Album_Sales_1_new$sequence=c(1:200)
ggplot(Album_Sales_1_new, aes(sequence, cooks.distance))+
geom_point()+
geom_hline(aes(yintercept=4/length(Album_Sales_1_new$adverts), colour="red"))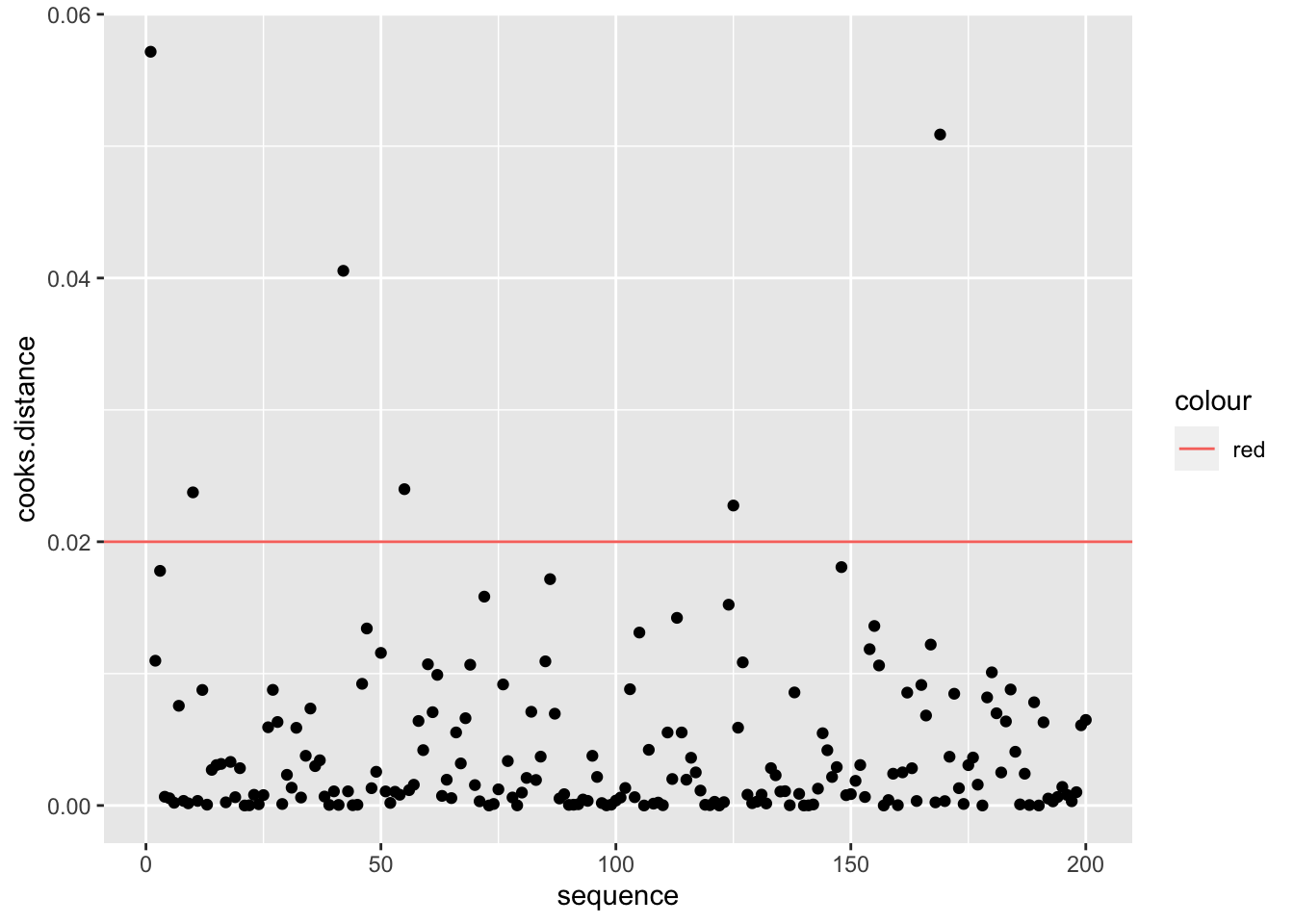
Pasos para hacer un análisis de regresión lineal
Paso 1
Primer paso, construir su modelo y evaluar los coeficientes.
El resultado: El coeficiente (intercepto) y la pendiente del modelo
Paso 2
Evaluar si los coeficientes son diferentes de cero.
La primera hipótesis: Determinar si el intercepto es igual a cero. Mira el valor de p, Pr(>|t|), determinar si el valor es menor de 0.05, si lo es se rechaza la Ho y por consecuencia tenemos confianza que el intercepto no incluye cero.
La segunda hipótesis nula: Determinar si la pendiente es igual a cero. Mira el valor de p, Pr(>|t|), como el valor es menor de p=0.05, se rechaza la Ho y por consecuencia tenemos confianza que la pendiente no incluye cero.
Paso 3
– Evaluar si los datos cumplen con los supuestos:
Igualdad de varianza, usa la gráfica de residuales
Normalidad, qqplot
Valores sesgados, la prueba de Cook
##
## Call:
## lm(formula = sales ~ adverts, data = Album_Sales_1_new)
##
## Residuals:
## Min 1Q Median 3Q Max
## -152.949 -43.796 -0.393 37.040 211.866
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.341e+02 7.537e+00 17.799 <2e-16 ***
## adverts 9.612e-02 9.632e-03 9.979 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 65.99 on 198 degrees of freedom
## Multiple R-squared: 0.3346, Adjusted R-squared: 0.3313
## F-statistic: 99.59 on 1 and 198 DF, p-value: < 2.2e-16tab_model(
advertizingReg,show.df = TRUE,
CSS = list(
css.depvarhead = 'color: red;',
css.centeralign = 'text-align: left;',
css.firsttablecol = 'font-weight: bold;',
css.summary = 'color: blue;'
)
)| sales | ||||
|---|---|---|---|---|
| Predictors | Estimates | CI | p | df |
| (Intercept) | 134.14 | 119.28 – 149.00 | <0.001 | 198.00 |
| adverts | 0.10 | 0.08 – 0.12 | <0.001 | 198.00 |
| Observations | 200 | |||
| R2 / R2 adjusted | 0.335 / 0.331 | |||
Alternativa para Gráficar los residuales
Gráficar los residuales
Si el supuesto de igualdad de varianza se cumple lo que observaremos es que la distribución de los residuales luce más o menos uniforme alrededor del promedio de los residuales (el cero). Hay aproximadamente igual cantidad de valores mayor a cero (por encima de la línea en azul) y menor a cero (por debajo de la línea en azul) que están distribuidos a través de la variable en el eje de X, o valores estimados. En adición que los residuales (negativos o positivos) no son limitado a sub grupos de los valores estimados (en la X).
# "model1", nota que este no es un data frame pero un modelo
# La figura principal
ggplot(Album_Sales_1_new, aes(x=adverts, y=sales))+
geom_smooth(method=lm, se = TRUE)+
geom_point()## `geom_smooth()` using formula = 'y ~ x'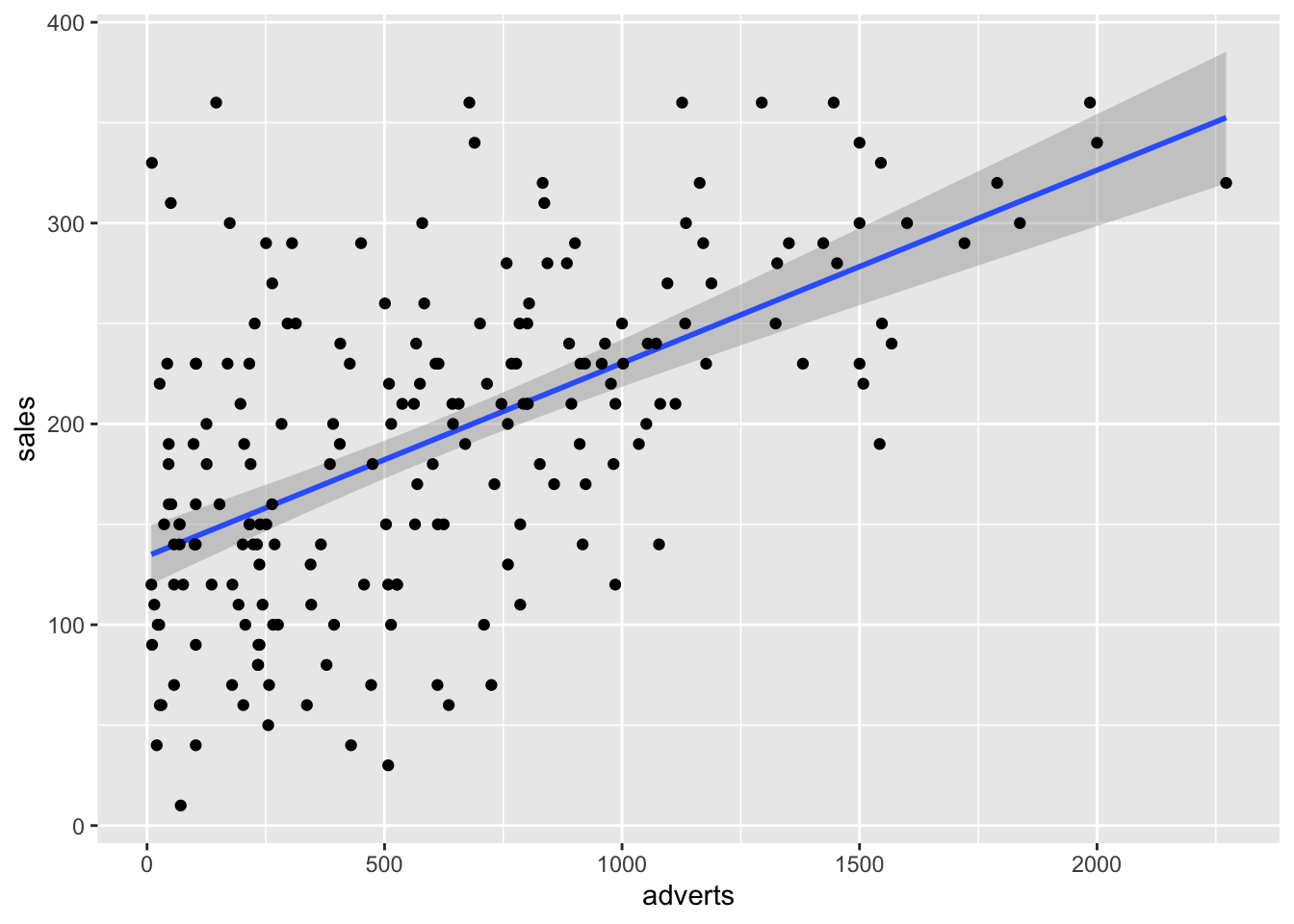
# Graficando los residuales con ggplot2
ggplot(model1, aes(x=.fitted, y=.resid))+
geom_point()+
geom_smooth(method=lm)## `geom_smooth()` using formula = 'y ~ x'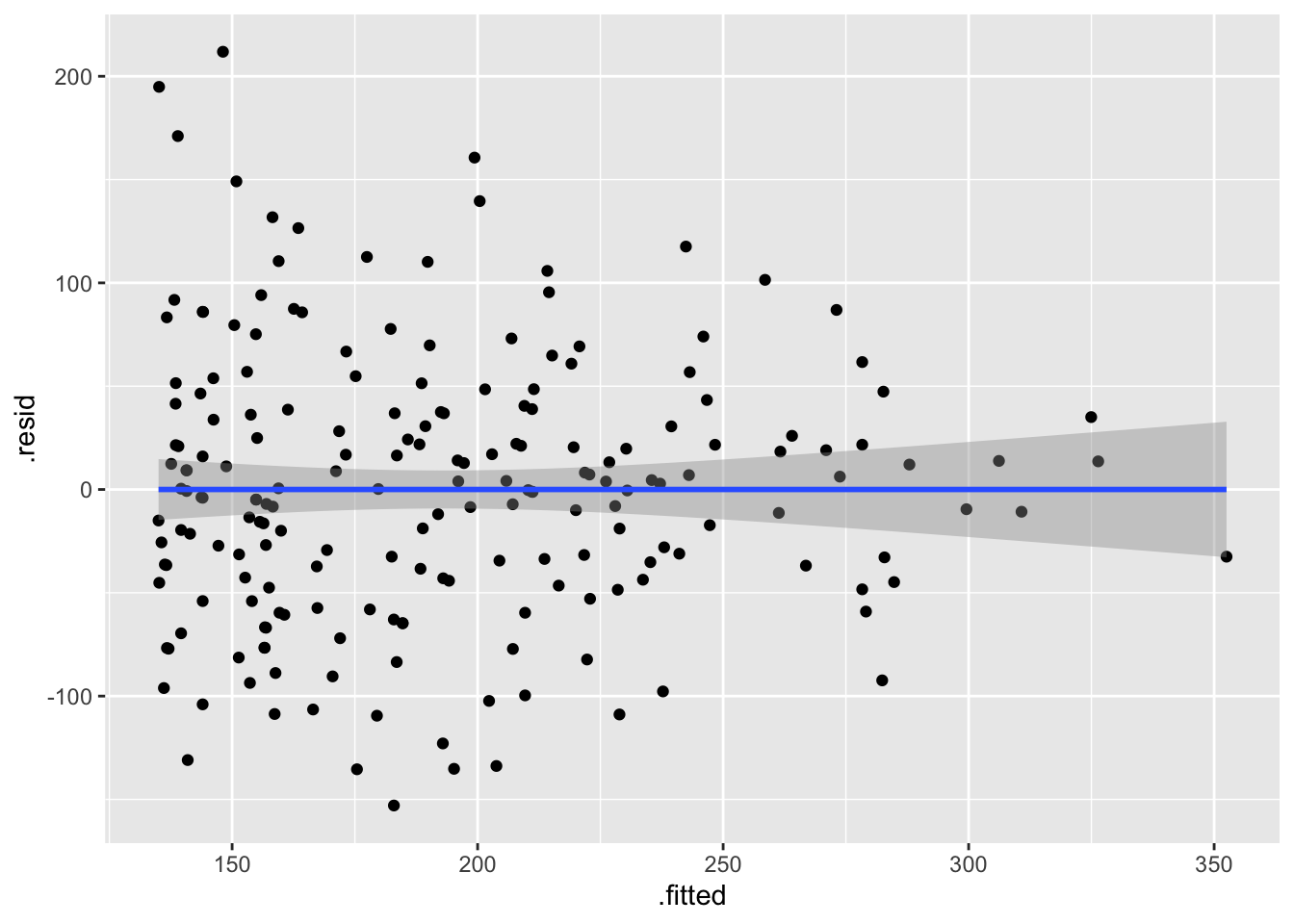
Ejercicio 1
Los datos state.x77 provienen del paquete datasets donde representa información sobre los estados americanos, su nivel poblacional, ingreso, nivel de analfabetismo, expectativa de vida, y otras variables. Selecciona la variables de analfabetismo y “life expectancy”, y evalua si hay una relación entre las dos variables.
Nota se tiene que limpiar los nombres de las variables, pq algunos tiene espacios. Se usa el paquete janitor y la función clean_names().
Usa los datos de analfabetismo (illiteracy) y evalua es un predictor de la expectativa de vida (life_exp).
Usando los siguientes datos haga un análisis completo de regresión lineal.
Determina si los supuestos de la regresión lineal se cumple.
library(datasets)
state.x77=as.data.frame(state.x77) # convertir los datos en un data frame
state.x77=janitor::clean_names(state.x77) # limpiar los nombres de las variables
head(state.x77)| population | income | illiteracy | life_exp | murder | hs_grad | frost | area |
|---|---|---|---|---|---|---|---|
| 3.62e+03 | 3.62e+03 | 2.1 | 69 | 15.1 | 41.3 | 20 | 5.07e+04 |
| 365 | 6.32e+03 | 1.5 | 69.3 | 11.3 | 66.7 | 152 | 5.66e+05 |
| 2.21e+03 | 4.53e+03 | 1.8 | 70.5 | 7.8 | 58.1 | 15 | 1.13e+05 |
| 2.11e+03 | 3.38e+03 | 1.9 | 70.7 | 10.1 | 39.9 | 65 | 5.19e+04 |
| 2.12e+04 | 5.11e+03 | 1.1 | 71.7 | 10.3 | 62.6 | 20 | 1.56e+05 |
| 2.54e+03 | 4.88e+03 | 0.7 | 72.1 | 6.8 | 63.9 | 166 | 1.04e+05 |
Ejercicio 2
El conjunto de datos ToothGrowth del paquete datasets contiene el resultado de un experimento que estudia el efecto de la vitamina C en el crecimiento de los dientes en 60 cobayas (Guinea Pigs). Cada animal recibió uno de los tres niveles de dosis de vitamina C (0,5, 1 y 2 mg / día) mediante uno de los dos métodos de administración (jugo de naranja o ácido ascórbico (una forma de vitamina C y codificado como VC).
Usando los siguiente datos haga un análisis completo de regresión lineal.
| len | supp | dose |
|---|---|---|
| 4.2 | VC | 0.5 |
| 11.5 | VC | 0.5 |
| 7.3 | VC | 0.5 |
| 5.8 | VC | 0.5 |
| 6.4 | VC | 0.5 |
| 10 | VC | 0.5 |

“Activities reported in this website was supported by the National Institute Of General Medical Sciences of the National Institutes of Health under Award Number R25GM121270. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.”