Regressión beta

![]() #Un cambio para modificar los gráficos
#Un cambio para modificar los gráficos
Regressión beta
El método presentado aquí es bastante innovador (2010 en adelante). Desafortunadamente no hay mucha información en la literatura o el web sobre el método. Puede encontrar información suplementaria en el Vignette del paquete betareg.
Referencias:
Cribari-Neto, F., and Zeileis, A. (2010). Beta Regression in R. Journal of Statistical Software, 34(2), 1–24. http://www.jstatsoft.org/v34/i02/.
Grün, B., Kosmidis, I., and Zeileis, A. (2012). Extended Beta Regression in R: Shaken, Stirred, Mixed, and Partitioned. Journal of Statistical Software, 48(11), 1–25. http://www.jstatsoft.org/v48/i11/.
Articulo sobre regresión beta y diferentes paquetes de R que se puede usar para hacer los análisis Douma and Weedon 2019
¿Qué es la Regresión beta?
La regresión beta es una aproximación bajo GLM “Modelos lineales generalizado”. La regresión beta modela variables dependientes distribuidas con la distribución beta. Datos con la distribución beta incluyen proporciones y razones, donde los valores \(x\) se encuentran entre 0 y 1 pero no inclusivo (i.e. \(0 < x< 1\)). Además de producir una regresión que máxima la verosimilitud (tanto para la media como para la precisión de una respuesta distribuida en beta), se proporcionan estimaciones con corrección de sesgo.
Los valores de la variable de respuesta satisfacen \(0 < x < 1\). Por consecuencia si tiene valores que son 0 o 1, es necesario cambiarlos a \(0= 0.001\) y \(1 = 0.999\). Los números no pueden ser 0 ni 1, deben ser mayores que 0 y menores que 1. Efectivamente a cambiar los los valores a \(0.001\) y \(0.999\) no tiene impacto sobre la interpretación de los datos, al menos que todos sus datos son solamente \(0\) ó \(1\), en este caso no se debería usar esta herramienta pero una regresión logística.
El paquete “betareg” y sus datos. Tenga en cuenta que el enfoque del modelo GLM es desarrollar una regresión con la respuesta a través de una función de enlace y un predictor lineal. Igual como GLM normal, existen numerosas funciones de enlace, que pueden ser útil como “logit”, “probit”, “cloglog”, “cauchit”, “log”, “loglog” para linearizar los datos.
Casi toda la información que se estará presentando aquí proviene de Cribari-Neto y Zeileis (Beta Regression in R).
Consulte el pdf, https://cran.r-project.org/web/packages/betareg/betareg.pdf para obtener una descripción del paquete y más detalles.
Estaré usando datos diferentes a lo que se presenta en el paquete para demostrar el valor de los análisis.
Errores típicos de análisis con datos que son fracciones.
Miramos un ejemplo. Aquí la relación entre el gasto se salud publica per capita en 156 paises y el porcentaje de niñas que no están en la escuela.
Datos del “World Development Agency”
Que es lo que obseva que no tienen sentido?
library(ggversa)
#Edu_Salud_Gastos_GDP
ggplot(Edu_Salud_Gastos_GDP, aes(Gasto_Salud_percapita, Porc_Ninas_no_escuela))+
geom_point()+
geom_smooth(method = lm)## `geom_smooth()` using formula = 'y ~ x'## Warning: Removed 46 rows containing non-finite values (`stat_smooth()`).## Warning: Removed 46 rows containing missing values (`geom_point()`).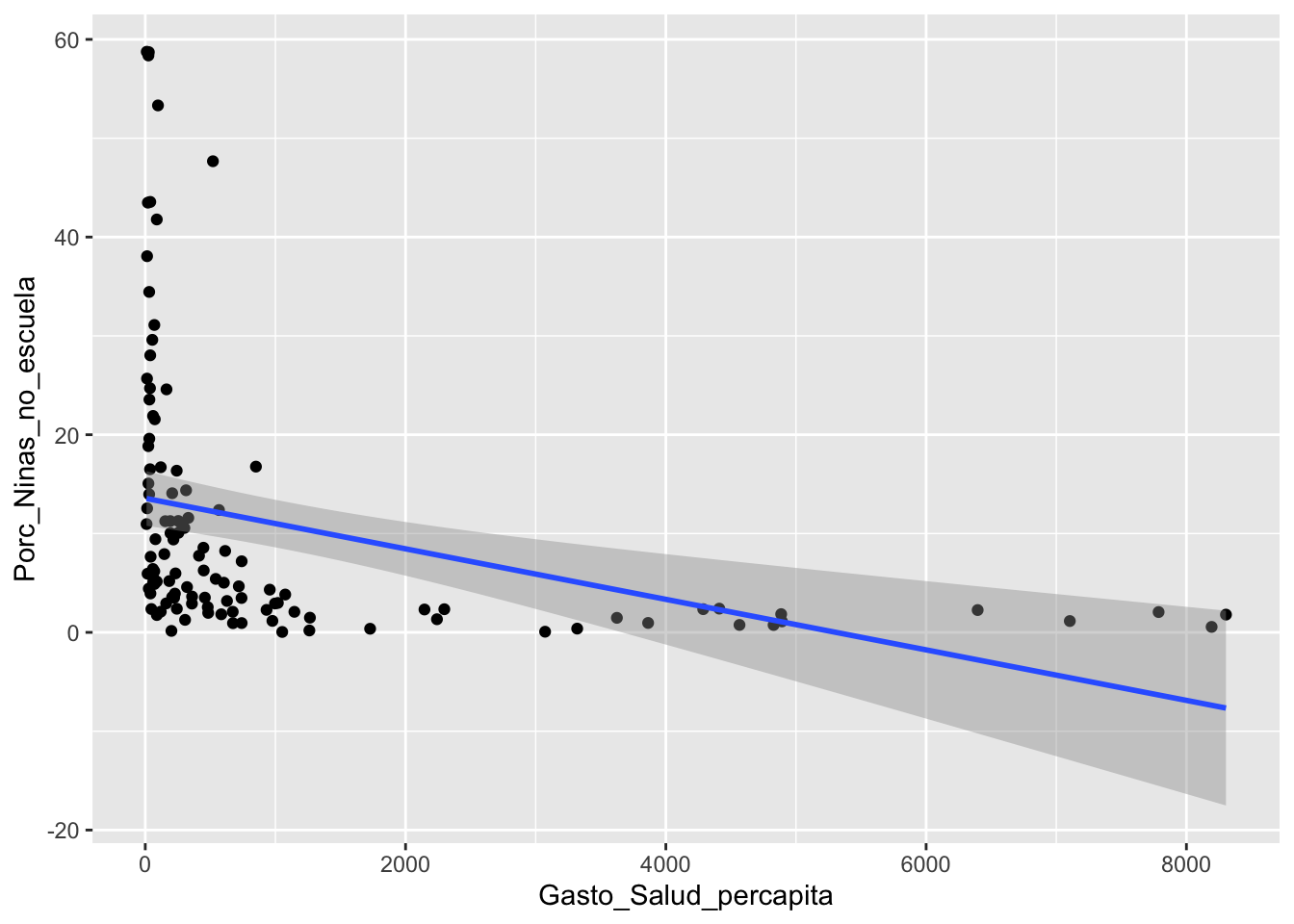
Nota: - hay valores de proporciones negativa - el intervalo de confianza también es negativo - la dispersión de los datos en y alrededor de la media no es igual a medida que el gasto de salud per capita cambia (en x).
Los modelos usando la distribución beta resuelve estos asuntos.
Primer paso, que es una distribución beta?
Lo más importante de la distribución beta es que los valores NUNCA son menores de 0 ni mayores de 1 (i.e. \(0 < x < 1\)). En adición los intervalos de confianza tampoco no pueden ser ni menor de 0 ni mayor de 1.
Se construye múltiples conjuntos de datos con distribuciones beta distinta, para evaluar como se ve la distribuciones, nota que aquí los parametros no son el promedio y la sd, pero dos parámetros que se llama shape.
Aquí una serie de distribuciones beta. La distribución beta se calcula con dos parametros, shape 1 o \(\alpha\) y shape 2 o \(\beta\). No vamos a entrar en estos parámetros, aunque pueden ir a la pagina de Wikipedia para tener más información. Deben fijarse en que si los parámetros no sin iguales (\(\alpha \neq \beta\)) la distribución no es simétrica. Siempre hay una cola que se extiende en los valores pequeños o grandes.
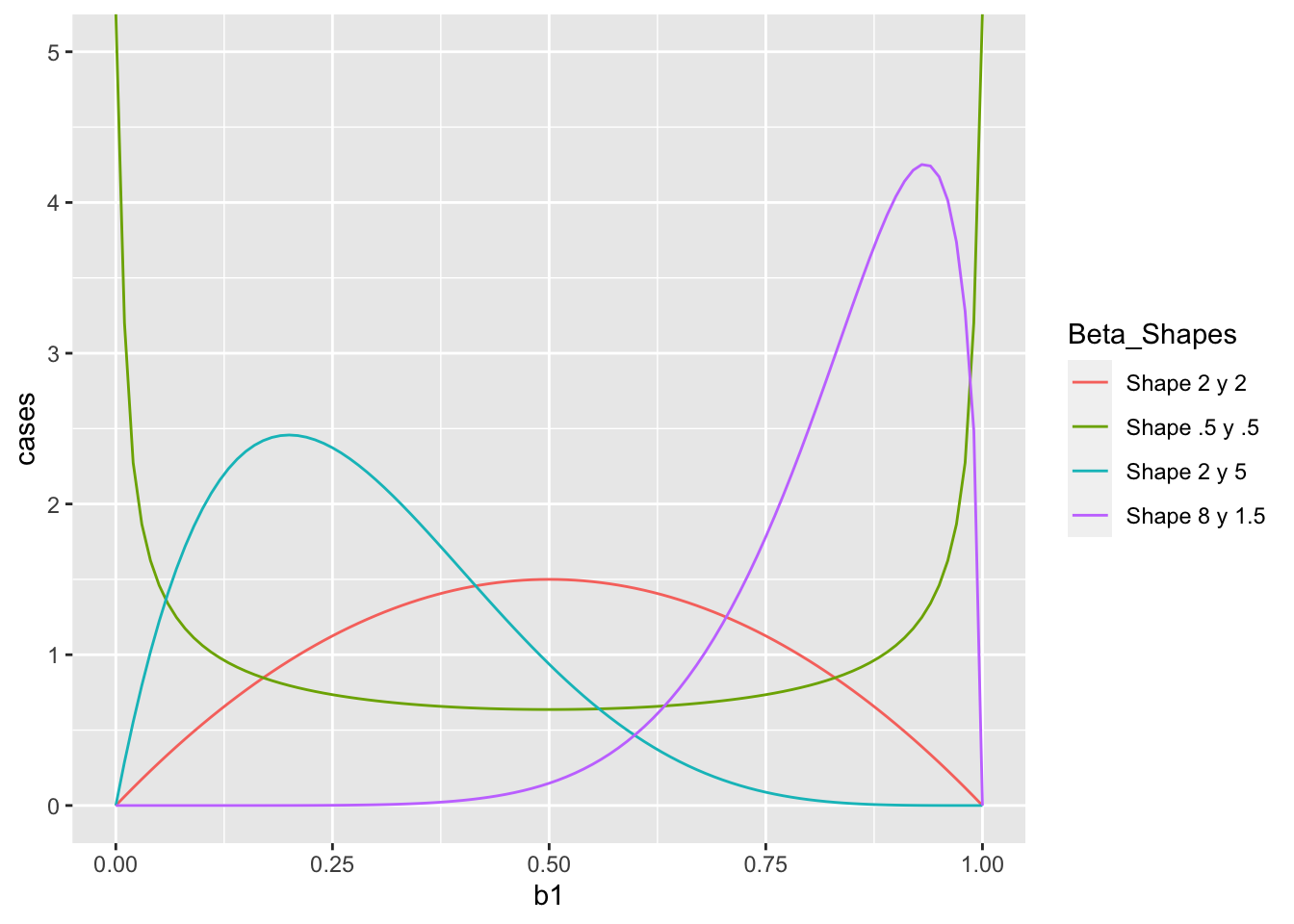
Wikipedia
En la pagina de Wikipedia sobre distribución beta se puede apreciar como la distribución cambian cuando varia los parametros

Proporción de fumadores por diferentes paises.
Los datos provienen de World Bank en el siguiente enlace, Smokers. En el archivo se encuentra información sobre 187 pais y la proporción de población mayor de 15 años que fuman.
Los datos están debajo pestaña de “Los Datos”
## Rows: 187 Columns: 13
## ── Column specification ─────────────────────────────────────────────────────────────────────────────────────
## Delimiter: ","
## chr (4): Country_Name, Country_Code, Indicator_Name, Indicator_Code
## dbl (9): Y2000, Y2005, Y2010, Y2011, Y2012, Y2013, Y2014, Y2015, Y2016
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.| Country_Name | Country_Code | Indicator_Name | Indicator_Code | Y2000 | Y2005 | Y2010 | Y2011 | Y2012 | Y2013 | Y2014 | Y2015 | Y2016 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Honduras | HND | Smoking prevalence, total (ages 15+) | SH.PRV.SMOK | 3.9 | 3.1 | 2.5 | 2.4 | 2.4 | 2.3 | 2.2 | 2.1 | 2.0 |
| Ethiopia | ETH | Smoking prevalence, total (ages 15+) | SH.PRV.SMOK | 4.8 | 4.6 | 4.5 | 4.4 | 4.5 | 4.4 | 4.4 | 4.4 | 4.4 |
| Congo, Rep. | COG | Smoking prevalence, total (ages 15+) | SH.PRV.SMOK | 5.7 | 9.1 | 14.7 | 16.1 | 17.9 | 19.8 | 22.0 | 24.2 | 26.9 |
| Ghana | GHA | Smoking prevalence, total (ages 15+) | SH.PRV.SMOK | 5.9 | 5.0 | 4.4 | 4.3 | 4.3 | 4.1 | 4.1 | 4.0 | 3.9 |
| Niger | NER | Smoking prevalence, total (ages 15+) | SH.PRV.SMOK | 6.4 | 6.7 | 7.1 | 7.2 | 7.3 | 7.4 | 7.5 | 7.6 | 7.7 |
| Nigeria | NGA | Smoking prevalence, total (ages 15+) | SH.PRV.SMOK | 7.7 | 7.0 | 6.3 | 6.2 | 6.1 | 6.1 | 5.9 | 5.8 | 5.8 |
Primero vamos a convertir los datos en proporción ya que el programa tiene que utilizar datos mayor de 0 y menor de 1. Seleccionamos el año 2000 y creamos un histograma de la distribución.
Smokers$Y2000P=(Smokers$Y2000)/100 # convertir en proporción
Smokers %>% dplyr::select(Country_Name, Y2000P)| Country_Name | Y2000P |
|---|---|
| Honduras | 0.039 |
| Ethiopia | 0.048 |
| Congo, Rep. | 0.057 |
| Ghana | 0.059 |
| Niger | 0.064 |
| Nigeria | 0.077 |
| Oman | 0.082 |
| Barbados | 0.083 |
| Eritrea | 0.087 |
| Benin | 0.091 |
| Eswatini | 0.093 |
| Togo | 0.1 |
| Bahamas, The | 0.106 |
| Senegal | 0.109 |
| Haiti | 0.121 |
| Peru | 0.121 |
| Cabo Verde | 0.13 |
| Mali | 0.13 |
| Sub-Saharan Africa (excluding high income) | 0.134 |
| Sub-Saharan Africa | 0.134 |
| Sub-Saharan Africa (IDA & IBRD countries) | 0.134 |
| Liberia | 0.138 |
| Ecuador | 0.139 |
| Saudi Arabia | 0.145 |
| Panama | 0.15 |
| Uzbekistan | 0.158 |
| El Salvador | 0.16 |
| Singapore | 0.163 |
| Sri Lanka | 0.165 |
| Qatar | 0.165 |
| Algeria | 0.166 |
| Kenya | 0.166 |
| Brunei Darussalam | 0.17 |
| Uganda | 0.171 |
| Burkina Faso | 0.172 |
| Iran, Islamic Rep. | 0.175 |
| IDA blend | 0.175 |
| Djibouti | 0.176 |
| Egypt, Arab Rep. | 0.176 |
| Lesotho | 0.176 |
| Rwanda | 0.178 |
| Costa Rica | 0.18 |
| Zambia | 0.18 |
| Zimbabwe | 0.18 |
| Jamaica | 0.184 |
| Dominican Republic | 0.187 |
| Morocco | 0.187 |
| Middle East & North Africa (excluding high income) | 0.189 |
| Middle East & North Africa (IDA & IBRD countries) | 0.189 |
| Middle East & North Africa | 0.19 |
| Arab World | 0.191 |
| Botswana | 0.195 |
| Gambia, The | 0.199 |
| Colombia | 0.201 |
| IDA total | 0.206 |
| Malawi | 0.21 |
| Comoros | 0.211 |
| India | 0.212 |
| Namibia | 0.223 |
| Tanzania | 0.223 |
| Bahrain | 0.224 |
| Lower middle income | 0.224 |
| IDA only | 0.226 |
| South Asia | 0.227 |
| South Asia (IDA & IBRD) | 0.227 |
| South Africa | 0.227 |
| Moldova | 0.233 |
| Yemen, Rep. | 0.233 |
| Mozambique | 0.234 |
| Least developed countries: UN classification | 0.235 |
| Early-demographic dividend | 0.239 |
| Mexico | 0.24 |
| Australia | 0.245 |
| Pakistan | 0.245 |
| Latin America & Caribbean (excluding high income) | 0.246 |
| Kuwait | 0.248 |
| Thailand | 0.249 |
| Mauritius | 0.25 |
| Seychelles | 0.251 |
| Vietnam | 0.251 |
| United Arab Emirates | 0.252 |
| Brazil | 0.252 |
| Latin America & the Caribbean (IDA & IBRD countries) | 0.253 |
| Latin America & Caribbean | 0.258 |
| Portugal | 0.259 |
| Small states | 0.26 |
| Other small states | 0.262 |
| Low & middle income | 0.263 |
| Italy | 0.265 |
| IDA & IBRD total | 0.265 |
| Azerbaijan | 0.267 |
| Middle income | 0.267 |
| Slovenia | 0.268 |
| Kyrgyz Republic | 0.273 |
| IBRD only | 0.277 |
| World | 0.277 |
| Canada | 0.282 |
| Malaysia | 0.282 |
| New Zealand | 0.294 |
| Palau | 0.296 |
| Finland | 0.297 |
| China | 0.301 |
| Iceland | 0.301 |
| Cambodia | 0.301 |
| Upper middle income | 0.301 |
| East Asia & Pacific (excluding high income) | 0.304 |
| East Asia & Pacific (IDA & IBRD countries) | 0.304 |
| Late-demographic dividend | 0.304 |
| East Asia & Pacific | 0.305 |
| Paraguay | 0.308 |
| North America | 0.311 |
| Switzerland | 0.312 |
| Bangladesh | 0.314 |
| United States | 0.314 |
| Armenia | 0.318 |
| Tunisia | 0.318 |
| Israel | 0.319 |
| Kazakhstan | 0.319 |
| Vanuatu | 0.319 |
| Slovak Republic | 0.321 |
| Georgia | 0.322 |
| Mongolia | 0.322 |
| Sweden | 0.323 |
| Myanmar | 0.325 |
| Indonesia | 0.329 |
| Japan | 0.33 |
| OECD members | 0.33 |
| Croatia | 0.331 |
| High income | 0.336 |
| Post-demographic dividend | 0.338 |
| Czech Republic | 0.341 |
| Korea, Rep. | 0.343 |
| Philippines | 0.344 |
| Luxembourg | 0.347 |
| Albania | 0.348 |
| France | 0.349 |
| Euro area | 0.35 |
| Fiji | 0.351 |
| Germany | 0.353 |
| Malta | 0.353 |
| Lithuania | 0.359 |
| Ukraine | 0.36 |
| European Union | 0.361 |
| Tonga | 0.363 |
| Belarus | 0.367 |
| Europe & Central Asia | 0.37 |
| Maldives | 0.371 |
| Andorra | 0.374 |
| Belgium | 0.374 |
| Lebanon | 0.375 |
| Netherlands | 0.377 |
| Ireland | 0.378 |
| United Kingdom | 0.382 |
| Europe & Central Asia (excluding high income) | 0.383 |
| Pacific island small states | 0.383 |
| Denmark | 0.383 |
| Turkey | 0.384 |
| Europe & Central Asia (IDA & IBRD countries) | 0.385 |
| Latvia | 0.388 |
| Nepal | 0.389 |
| Spain | 0.395 |
| Central Europe and the Baltics | 0.395 |
| Estonia | 0.396 |
| Romania | 0.396 |
| Poland | 0.407 |
| Hungary | 0.411 |
| Argentina | 0.414 |
| Sierra Leone | 0.422 |
| Cyprus | 0.424 |
| Lao PDR | 0.427 |
| Russian Federation | 0.428 |
| Norway | 0.431 |
| Samoa | 0.451 |
| Cuba | 0.457 |
| Bosnia and Herzegovina | 0.477 |
| Serbia | 0.487 |
| Austria | 0.491 |
| Suriname | 0.5 |
| Timor-Leste | 0.518 |
| Bulgaria | 0.52 |
| Montenegro | 0.527 |
| Uruguay | 0.527 |
| Greece | 0.535 |
| Chile | 0.566 |
| Papua New Guinea | 0.609 |
| Nauru | 0.638 |
| Kiribati | 0.734 |
Convertir el promedio y varianza en shape \(\alpha\) y \(\beta\)
Convertir el promedio y la varianza de los datos en los valores del shape \(\alpha\) y \(\beta\). Se usa la siguiente para calcular los shapes. Los valores esperado y la varianza se comportan de forma distinta.
\[E(X) = \frac{\alpha}{\alpha+\beta}\]
\[V(X) = \frac{\alpha\beta}{(\alpha+\beta+1)(\alpha+\beta)^2}\]
Usando el promedio y varianza se puede convertir en \(\alpha\) y \(\beta\) con la siguiente ecuaciones
\[\alpha = \frac{1-mu}{(var-1)/mu}*mu^2\] \[\beta = \alpha*(\frac{1}{mu}-1)\] Aquí un script para convertir los parametros en shape
estBetaParams <- function(mu, var) {
alpha <- ((1 - mu) / var - 1 / mu) * mu ^ 2
beta <- alpha * (1 / mu - 1)
return(params = list(alpha = alpha, beta = beta))
}
#mean(Smokers$Y2000P)
#var(Smokers$Y2000P)
estBetaParams((mean(Smokers$Y2000P)), (var(Smokers$Y2000P)))## $alpha
## [1] 3.592488
##
## $beta
## [1] 9.181559Ahora comparamos la distribución beta y normal de los datos de los fumadores de mayores de 15 años
Smokers$Y2000P=(Smokers$Y2000)/100 # convertir en proporción
x <- seq(0, 1, len = 100)
#mean(Smokers$Y2000P)
#var(Smokers$Y2000P)
ggplot(Smokers, aes(Y2000P))+
geom_histogram(aes(y=..density..), colour="white", fill="grey50")+
stat_function(aes(x = Smokers$Y2000P, y = ..y..), fun = dbeta, colour="red", n = 100,
args = list(shape1 = 3.593, shape2 = 9.185))+
stat_function(fun = dnorm,
args = list(mean = mean(Smokers$Y2000P, na.rm = TRUE),
sd = sd(Smokers$Y2000P, na.rm = TRUE)),
colour = "green", size = 1)+
xlab("Proporción de fumadores de mayor \n de 15 años por Pais")+
ylab("Densidad")+
annotate("text", x = .5, y = 4.2, label = "Verde: dist Normal", color="darkgreen")+
annotate("text", x = .5, y = 3.7, label = "Verde: dist Beta", color="red")+
xlim(-0.1, 0.9)## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.## Warning: Removed 2 rows containing missing values (`geom_bar()`).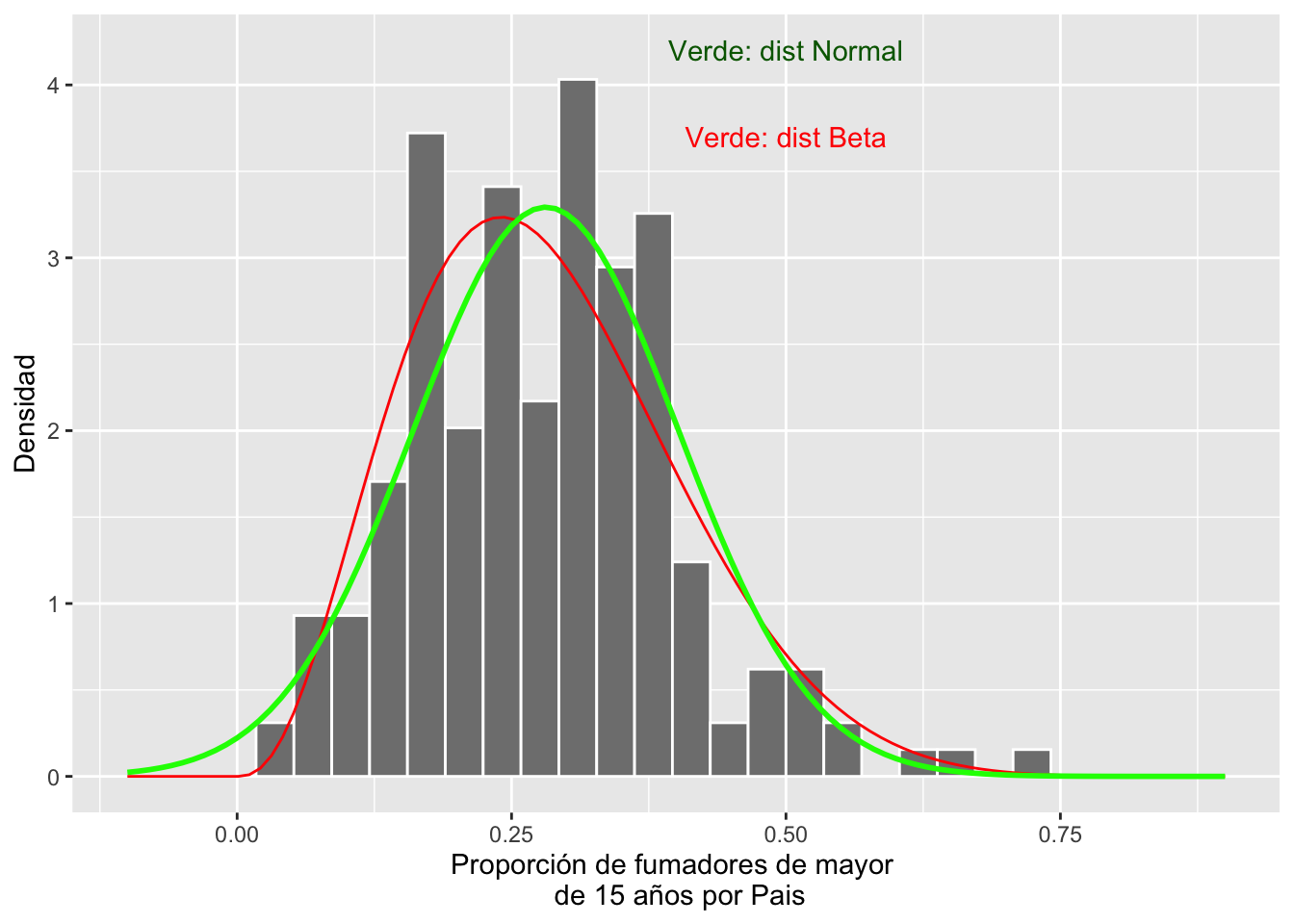
Calculando el intervalo de confianza del promedio de una distribución beta. Se necesita los siguientes paquetes simpleboot , boot.
library(simpleboot)
library(boot) # paquete para calcular el intervalo de confianza de una distribución beta
n=187 # El tamaño de muestra de los datos
alpha = 3.593 # estimado de la función arriba
beta = 9.185
x = rbeta(n, alpha, beta)
x.boot = one.boot(x, median, R=10^4) # Aquí se usa la mediana, pq el promedio *mean* sera sesgado a la derecha.
boot.ci(x.boot, type="bca")## BOOTSTRAP CONFIDENCE INTERVAL CALCULATIONS
## Based on 10000 bootstrap replicates
##
## CALL :
## boot.ci(boot.out = x.boot, type = "bca")
##
## Intervals :
## Level BCa
## 95% ( 0.2324, 0.2837 )
## Calculations and Intervals on Original ScaleVisualización de la distribución
Sobreponemos el intervalo de confianza de la mediana sobre la distribución beta
ggplot(Smokers, aes(Y2000P))+
geom_histogram(aes(y=..density..), bins=20, colour="white", fill="grey50")+
stat_function(aes(x = Smokers$Y2000P, y = ..y..), fun = dbeta, colour="red", n = 100,
args = list(shape1 = 3.593, shape2 = 9.185))+
geom_vline(xintercept =0.2320, colour="blue")+ # El intervalo de confianza del promedio
geom_vline(xintercept =0.2768, colour="blue")+
rlt_theme+
xlab("Proporción de fumadores por Pais")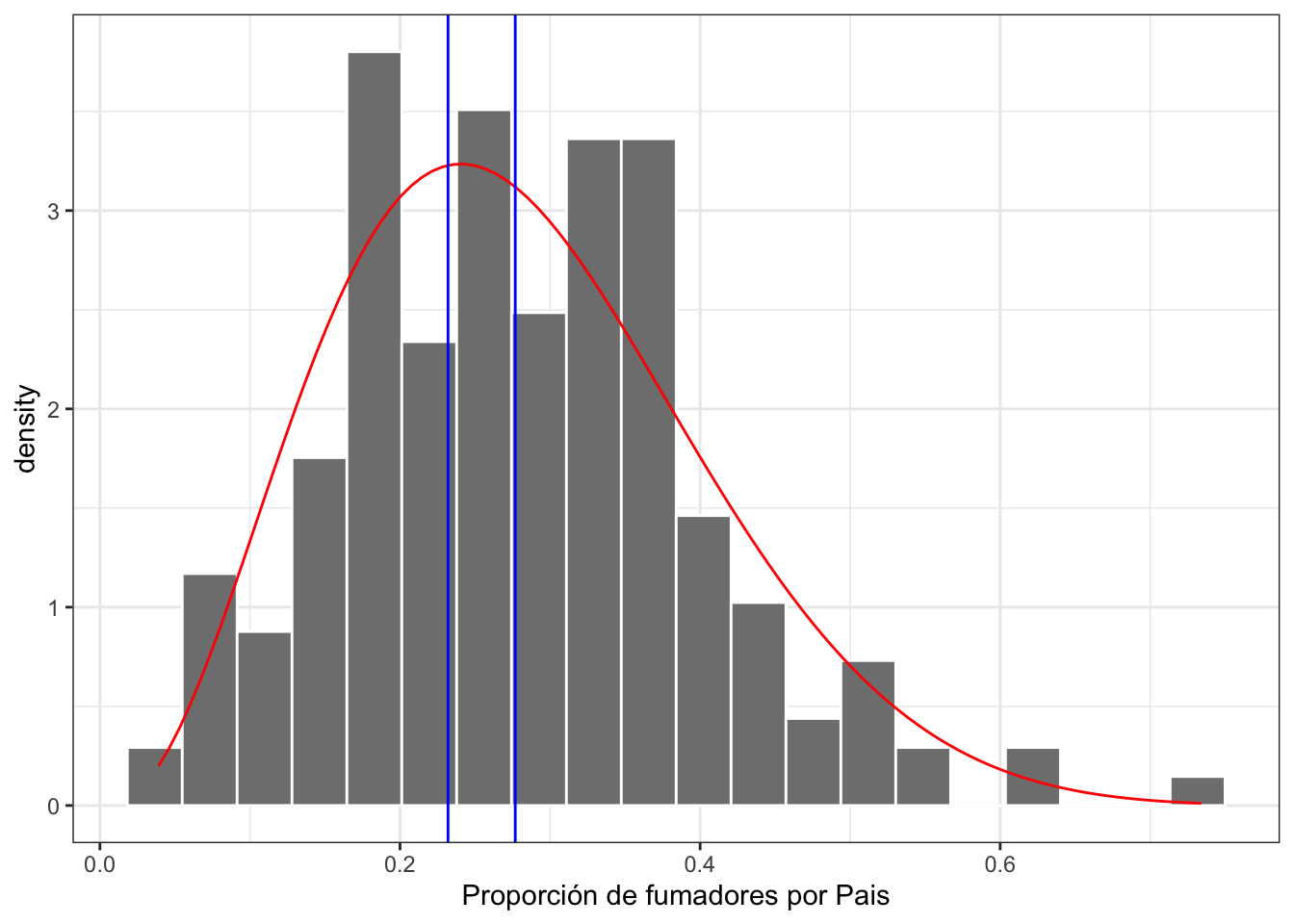
library(betareg) # El paquete para hacer regresión beta
library(ggversa) # paquete para los datos
attach(dipodium)
head(dipodium, n=4)| Tree Number | Tree species | DBH | Plant number | Ramet number | Distance | Orientation | Number_of_Flowers | Height_Inflo | Herbivory | RowPosition_NF | Number_Flowers_position | Number_of_fruits | Perc_FR_set | pardalinum_or_roseum | Fruit_position_effect | Frutos_si_o_no | P_or_R_Infl_Lenght | Num of fruits | Species_Name | Cardinal orientation |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | E.o | 75 | 1 | 1 | 2.47 | 40 | 11 | 35 | n | 1 | 24 | 0 | 0 | r | 1 | 0 | r | 0 | r | 1 |
| 1 | E.o | 76 | 2 | 1 | 1.97 | 50 | 19 | 47 | n | 2 | 23 | 0 | 0 | r | 2 | 0 | r | 0 | r | 2 |
| 2 | E.o | 76 | 3 | 1 | 1.95 | 350 | 18 | 63 | n | 3 | 25 | 1 | 0.04 | r | 3 | 0 | r | 1 | r | 8 |
| 3 | E.o | 58 | 4 | 1 | 3.24 | 210 | 24 | 47 | n | 4 | 20 | 5 | 0.25 | r | 4 | 0 | r | 5 | r | 5 |
Regresión beta, proporción de frutos por cantidad de flores

from this webpage: https://binalongbungalows.wordpress.com/tasmanian-orchids/dipodium-roseum-rosy-hyacinth-orchid-0615-web/
Ahora haremos el primer análisis de regresión donde nuestra respuesta es una proporción.
Los datos provienen de una especie de orquidea de Australia, Dipodium roseum, recolectado por RLT en 2004-2005. Vamos a evaluar la relación entre el número de flores y la proporción de frutos por planta. El primer paso es asegarar que no haya valores de 0 y 1. En este caso no hay ni una planta que tiene 100% de frutos, pero si hay individuos que tienen cero frutos.
RECUERDA x >0 y <1. NO se acepta 0 o 1. Entonces a los valores de 0 se le puede añadir un valor mínimo como 0.001 y a los 1 restar 0.001. En realidad esta modificación no impacta la interpretación de los resultados.
se remueva también del archivo los NA.
Nota que el modelo se construye como un modelo lineal betareg(y~x, data =na.omit(df)). Las variables del archivo son PropFR, el proporción de frutos (número de frutos/números de flores) por cada individuo y el número de flores, Number_of_Flowers.
#head(dipodium)
library(tidyverse)
dipodium$PropFR=dipodium$Perc_FR_set+0.0001 # solucionar para remover los cero
#dipodium$PropFR
dipodium2=dipodium %>%
dplyr::select(PropFR, Number_of_Flowers,Height_Inflo, Distance) %>%
filter(complete.cases(PropFR, Number_of_Flowers,Height_Inflo, Distance))
#dipodium2
write.csv(x=dipodium2, file="dipodium2.csv")
library(readr)
dipodium2 <- read_csv("Data/dipodium2.csv")## New names:
## Rows: 62 Columns: 5
## ── Column specification
## ───────────────────────────────────────────────────────────────────────────────────── Delimiter: "," dbl
## (5): ...1, PropFR, Number_of_Flowers, Height_Inflo, Distance
## ℹ Use `spec()` to retrieve the full column specification for this data. ℹ Specify the column types or set
## `show_col_types = FALSE` to quiet this message.
## • `` -> `...1`modelpropFr=betareg(PropFR~Number_of_Flowers+Height_Inflo+Distance, data =na.omit(dipodium2))
summary(modelpropFr)##
## Call:
## betareg(formula = PropFR ~ Number_of_Flowers + Height_Inflo + Distance,
## data = na.omit(dipodium2))
##
## Standardized weighted residuals 2:
## Min 1Q Median 3Q Max
## -3.8613 -0.4046 0.2672 0.8535 1.2798
##
## Coefficients (mean model with logit link):
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -3.796016 0.727139 -5.220 1.78e-07 ***
## Number_of_Flowers 0.076200 0.028247 2.698 0.00698 **
## Height_Inflo 0.006054 0.017847 0.339 0.73444
## Distance -0.111010 0.093825 -1.183 0.23674
##
## Phi coefficients (precision model with identity link):
## Estimate Std. Error z value Pr(>|z|)
## (phi) 4.8382 0.9982 4.847 1.25e-06 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Type of estimator: ML (maximum likelihood)
## Log-likelihood: 113.9 on 5 Df
## Pseudo R-squared: 0.2757
## Number of iterations: 19 (BFGS) + 2 (Fisher scoring)Visualizar un gráfico de regresión beta
dipodiumbeta=dipodium2[,c("Number_of_Flowers","PropFR")] # crear un df con solamente las columnas de interes
dp2=dipodiumbeta[complete.cases(dipodiumbeta),] # remover los "NA"
modelpropFr=betareg(PropFR~Number_of_Flowers, data=dp2) # El modelo con solamente la explicativa
summary(modelpropFr)##
## Call:
## betareg(formula = PropFR ~ Number_of_Flowers, data = dp2)
##
## Standardized weighted residuals 2:
## Min 1Q Median 3Q Max
## -3.3221 -0.3181 0.2414 0.8225 1.2346
##
## Coefficients (mean model with logit link):
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -3.88360 0.44251 -8.776 < 2e-16 ***
## Number_of_Flowers 0.08259 0.01803 4.581 4.62e-06 ***
##
## Phi coefficients (precision model with identity link):
## Estimate Std. Error z value Pr(>|z|)
## (phi) 4.6947 0.9699 4.84 1.3e-06 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Type of estimator: ML (maximum likelihood)
## Log-likelihood: 112.9 on 3 Df
## Pseudo R-squared: 0.2538
## Number of iterations: 18 (BFGS) + 1 (Fisher scoring) #head(dp2)
#dp2$PropFR
predict(modelpropFr, type = "response") # calcular los valores estimados (predichos)## 1 2 3 4 5 6 7
## 0.02568523 0.02783519 0.03015954 0.04856508 0.05679268 0.05679268 0.05679268
## 8 9 10 11 12 13 14
## 0.06138242 0.06138242 0.06138242 0.06138242 0.06138242 0.06138242 0.06631700
## 15 16 17 18 19 20 21
## 0.06631700 0.07161801 0.07161801 0.07161801 0.07161801 0.07730766 0.07730766
## 22 23 24 25 26 27 28
## 0.07730766 0.08340872 0.08340872 0.08994433 0.08994433 0.08994433 0.08994433
## 29 30 31 32 33 34 35
## 0.09693789 0.10441284 0.10441284 0.10441284 0.10441284 0.10441284 0.11239245
## 36 37 38 39 40 41 42
## 0.11239245 0.12089957 0.12089957 0.12089957 0.12089957 0.12089957 0.12089957
## 43 44 45 46 47 48 49
## 0.12995632 0.12995632 0.12995632 0.12995632 0.12995632 0.13958381 0.14980172
## 50 51 52 53 54 55 56
## 0.14980172 0.14980172 0.17207828 0.17207828 0.17207828 0.17207828 0.19690033
## 57 58 59 60 61 62
## 0.19690033 0.22433274 0.22433274 0.23903102 0.27035714 0.28695536dp2$response=predict(modelpropFr, type = "response")
#dp2$link=predict(modelpropFr, type = "link")
dp2$precision=predict(modelpropFr, type = "precision")
dp2$variance=predict(modelpropFr, type = "variance")
dp2$quantile_.01=predict(modelpropFr, type = "quantile", at = c(0.01))
dp2$quantile_.05=predict(modelpropFr, type = "quantile", at = c(0.05))
dp2$quantile_.10=predict(modelpropFr, type = "quantile", at = c(0.10))
dp2$quantile_.15=predict(modelpropFr, type = "quantile", at = c(0.15))
dp2$quantile_.20=predict(modelpropFr, type = "quantile", at = c(0.20))
dp2$quantile_.25=predict(modelpropFr, type = "quantile", at = c(0.25))
dp2$quantile_.30=predict(modelpropFr, type = "quantile", at = c(0.30))
dp2$quantile_.35=predict(modelpropFr, type = "quantile", at = c(0.35))
dp2$quantile_.40=predict(modelpropFr, type = "quantile", at = c(0.40))
dp2$quantile_.45=predict(modelpropFr, type = "quantile", at = c(0.45))
dp2$quantile_.50=predict(modelpropFr, type = "quantile", at = c(0.50))
dp2$quantile_.55=predict(modelpropFr, type = "quantile", at = c(0.55))
dp2$quantile_.60=predict(modelpropFr, type = "quantile", at = c(0.60))
dp2$quantile_.65=predict(modelpropFr, type = "quantile", at = c(0.65))
dp2$quantile_.70=predict(modelpropFr, type = "quantile", at = c(0.70))
dp2$quantile_.75=predict(modelpropFr, type = "quantile", at = c(0.75))
dp2$quantile_.80=predict(modelpropFr, type = "quantile", at = c(0.80))
dp2$quantile_.85=predict(modelpropFr, type = "quantile", at = c(0.85))
dp2$quantile_.90=predict(modelpropFr, type = "quantile", at = c(0.90))
dp2$quantile_.95=predict(modelpropFr, type = "quantile", at = c(0.95))
dp2$quantile_.99=predict(modelpropFr, type = "quantile", at = c(0.99))
dp2| Number_of_Flowers | PropFR | response | precision | variance | quantile_.01 | quantile_.05 | quantile_.10 | quantile_.15 | quantile_.20 | quantile_.25 | quantile_.30 | quantile_.35 | quantile_.40 | quantile_.45 | quantile_.50 | quantile_.55 | quantile_.60 | quantile_.65 | quantile_.70 | quantile_.75 | quantile_.80 | quantile_.85 | quantile_.90 | quantile_.95 | quantile_.99 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 | 0.0001 | 0.0257 | 4.69 | 0.00439 | 3.86e-18 | 2.42e-12 | 7.58e-10 | 2.19e-08 | 2.38e-07 | 1.51e-06 | 6.86e-06 | 2.46e-05 | 7.46e-05 | 0.000198 | 0.000475 | 0.00105 | 0.00217 | 0.00424 | 0.00792 | 0.0143 | 0.0253 | 0.0444 | 0.0792 | 0.153 | 0.342 |
| 4 | 0.0001 | 0.0278 | 4.69 | 0.00475 | 7.44e-17 | 1.66e-11 | 3.34e-09 | 7.44e-08 | 6.72e-07 | 3.71e-06 | 1.5e-05 | 4.87e-05 | 0.000135 | 0.000333 | 0.000748 | 0.00155 | 0.00304 | 0.00565 | 0.0101 | 0.0175 | 0.0299 | 0.0506 | 0.0872 | 0.163 | 0.353 |
| 5 | 0.0001 | 0.0302 | 4.69 | 0.00514 | 1.14e-15 | 9.81e-11 | 1.31e-08 | 2.3e-07 | 1.75e-06 | 8.48e-06 | 3.07e-05 | 9.13e-05 | 0.000235 | 0.000539 | 0.00114 | 0.00224 | 0.00416 | 0.0074 | 0.0127 | 0.0212 | 0.0349 | 0.0572 | 0.0957 | 0.173 | 0.364 |
| 11 | 0.0001 | 0.0486 | 4.69 | 0.00811 | 2.75e-10 | 3.2e-07 | 6.69e-06 | 3.96e-05 | 0.00014 | 0.000372 | 0.000829 | 0.00163 | 0.00295 | 0.00497 | 0.00795 | 0.0122 | 0.0182 | 0.0265 | 0.0378 | 0.0534 | 0.0751 | 0.106 | 0.155 | 0.242 | 0.434 |
| 13 | 0.0358 | 0.0568 | 4.69 | 0.00941 | 5.29e-09 | 2.21e-06 | 2.98e-05 | 0.000136 | 0.000401 | 0.000928 | 0.00184 | 0.0033 | 0.00547 | 0.00859 | 0.0129 | 0.0187 | 0.0265 | 0.0368 | 0.0503 | 0.0683 | 0.0926 | 0.127 | 0.177 | 0.267 | 0.458 |
| 13 | 0.0939 | 0.0568 | 4.69 | 0.00941 | 5.29e-09 | 2.21e-06 | 2.98e-05 | 0.000136 | 0.000401 | 0.000928 | 0.00184 | 0.0033 | 0.00547 | 0.00859 | 0.0129 | 0.0187 | 0.0265 | 0.0368 | 0.0503 | 0.0683 | 0.0926 | 0.127 | 0.177 | 0.267 | 0.458 |
| 13 | 0.0001 | 0.0568 | 4.69 | 0.00941 | 5.29e-09 | 2.21e-06 | 2.98e-05 | 0.000136 | 0.000401 | 0.000928 | 0.00184 | 0.0033 | 0.00547 | 0.00859 | 0.0129 | 0.0187 | 0.0265 | 0.0368 | 0.0503 | 0.0683 | 0.0926 | 0.127 | 0.177 | 0.267 | 0.458 |
| 14 | 0.0001 | 0.0614 | 4.69 | 0.0101 | 1.96e-08 | 5.21e-06 | 5.77e-05 | 0.000236 | 0.000641 | 0.00139 | 0.00263 | 0.00451 | 0.00723 | 0.011 | 0.016 | 0.0227 | 0.0314 | 0.0427 | 0.0574 | 0.0765 | 0.102 | 0.137 | 0.189 | 0.28 | 0.47 |
| 14 | 0.364 | 0.0614 | 4.69 | 0.0101 | 1.96e-08 | 5.21e-06 | 5.77e-05 | 0.000236 | 0.000641 | 0.00139 | 0.00263 | 0.00451 | 0.00723 | 0.011 | 0.016 | 0.0227 | 0.0314 | 0.0427 | 0.0574 | 0.0765 | 0.102 | 0.137 | 0.189 | 0.28 | 0.47 |
| 14 | 0.105 | 0.0614 | 4.69 | 0.0101 | 1.96e-08 | 5.21e-06 | 5.77e-05 | 0.000236 | 0.000641 | 0.00139 | 0.00263 | 0.00451 | 0.00723 | 0.011 | 0.016 | 0.0227 | 0.0314 | 0.0427 | 0.0574 | 0.0765 | 0.102 | 0.137 | 0.189 | 0.28 | 0.47 |
| 14 | 0.131 | 0.0614 | 4.69 | 0.0101 | 1.96e-08 | 5.21e-06 | 5.77e-05 | 0.000236 | 0.000641 | 0.00139 | 0.00263 | 0.00451 | 0.00723 | 0.011 | 0.016 | 0.0227 | 0.0314 | 0.0427 | 0.0574 | 0.0765 | 0.102 | 0.137 | 0.189 | 0.28 | 0.47 |
| 14 | 0.231 | 0.0614 | 4.69 | 0.0101 | 1.96e-08 | 5.21e-06 | 5.77e-05 | 0.000236 | 0.000641 | 0.00139 | 0.00263 | 0.00451 | 0.00723 | 0.011 | 0.016 | 0.0227 | 0.0314 | 0.0427 | 0.0574 | 0.0765 | 0.102 | 0.137 | 0.189 | 0.28 | 0.47 |
| 14 | 0.0001 | 0.0614 | 4.69 | 0.0101 | 1.96e-08 | 5.21e-06 | 5.77e-05 | 0.000236 | 0.000641 | 0.00139 | 0.00263 | 0.00451 | 0.00723 | 0.011 | 0.016 | 0.0227 | 0.0314 | 0.0427 | 0.0574 | 0.0765 | 0.102 | 0.137 | 0.189 | 0.28 | 0.47 |
| 15 | 0.0001 | 0.0663 | 4.69 | 0.0109 | 6.54e-08 | 1.15e-05 | 0.000107 | 0.000392 | 0.000989 | 0.00203 | 0.00366 | 0.00605 | 0.00937 | 0.0138 | 0.0197 | 0.0273 | 0.037 | 0.0493 | 0.0651 | 0.0854 | 0.112 | 0.149 | 0.202 | 0.293 | 0.483 |
| 15 | 0.179 | 0.0663 | 4.69 | 0.0109 | 6.54e-08 | 1.15e-05 | 0.000107 | 0.000392 | 0.000989 | 0.00203 | 0.00366 | 0.00605 | 0.00937 | 0.0138 | 0.0197 | 0.0273 | 0.037 | 0.0493 | 0.0651 | 0.0854 | 0.112 | 0.149 | 0.202 | 0.293 | 0.483 |
| 16 | 0.0371 | 0.0716 | 4.69 | 0.0117 | 1.99e-07 | 2.39e-05 | 0.000188 | 0.000627 | 0.00148 | 0.00288 | 0.00499 | 0.00794 | 0.0119 | 0.0172 | 0.0239 | 0.0324 | 0.0431 | 0.0565 | 0.0733 | 0.0948 | 0.123 | 0.16 | 0.215 | 0.307 | 0.496 |
| 16 | 0.0001 | 0.0716 | 4.69 | 0.0117 | 1.99e-07 | 2.39e-05 | 0.000188 | 0.000627 | 0.00148 | 0.00288 | 0.00499 | 0.00794 | 0.0119 | 0.0172 | 0.0239 | 0.0324 | 0.0431 | 0.0565 | 0.0733 | 0.0948 | 0.123 | 0.16 | 0.215 | 0.307 | 0.496 |
| 16 | 0.125 | 0.0716 | 4.69 | 0.0117 | 1.99e-07 | 2.39e-05 | 0.000188 | 0.000627 | 0.00148 | 0.00288 | 0.00499 | 0.00794 | 0.0119 | 0.0172 | 0.0239 | 0.0324 | 0.0431 | 0.0565 | 0.0733 | 0.0948 | 0.123 | 0.16 | 0.215 | 0.307 | 0.496 |
| 16 | 0.077 | 0.0716 | 4.69 | 0.0117 | 1.99e-07 | 2.39e-05 | 0.000188 | 0.000627 | 0.00148 | 0.00288 | 0.00499 | 0.00794 | 0.0119 | 0.0172 | 0.0239 | 0.0324 | 0.0431 | 0.0565 | 0.0733 | 0.0948 | 0.123 | 0.16 | 0.215 | 0.307 | 0.496 |
| 17 | 0.0801 | 0.0773 | 4.69 | 0.0125 | 5.56e-07 | 4.69e-05 | 0.000317 | 0.00097 | 0.00215 | 0.00399 | 0.00664 | 0.0102 | 0.015 | 0.021 | 0.0286 | 0.0381 | 0.0498 | 0.0642 | 0.0822 | 0.105 | 0.134 | 0.172 | 0.228 | 0.321 | 0.509 |
| 17 | 0.333 | 0.0773 | 4.69 | 0.0125 | 5.56e-07 | 4.69e-05 | 0.000317 | 0.00097 | 0.00215 | 0.00399 | 0.00664 | 0.0102 | 0.015 | 0.021 | 0.0286 | 0.0381 | 0.0498 | 0.0642 | 0.0822 | 0.105 | 0.134 | 0.172 | 0.228 | 0.321 | 0.509 |
| 17 | 0.0001 | 0.0773 | 4.69 | 0.0125 | 5.56e-07 | 4.69e-05 | 0.000317 | 0.00097 | 0.00215 | 0.00399 | 0.00664 | 0.0102 | 0.015 | 0.021 | 0.0286 | 0.0381 | 0.0498 | 0.0642 | 0.0822 | 0.105 | 0.134 | 0.172 | 0.228 | 0.321 | 0.509 |
| 18 | 0.0401 | 0.0834 | 4.69 | 0.0134 | 1.44e-06 | 8.76e-05 | 0.000515 | 0.00145 | 0.00304 | 0.00541 | 0.00868 | 0.013 | 0.0185 | 0.0254 | 0.034 | 0.0444 | 0.0571 | 0.0726 | 0.0916 | 0.115 | 0.145 | 0.185 | 0.242 | 0.335 | 0.522 |
| 18 | 0.0001 | 0.0834 | 4.69 | 0.0134 | 1.44e-06 | 8.76e-05 | 0.000515 | 0.00145 | 0.00304 | 0.00541 | 0.00868 | 0.013 | 0.0185 | 0.0254 | 0.034 | 0.0444 | 0.0571 | 0.0726 | 0.0916 | 0.115 | 0.145 | 0.185 | 0.242 | 0.335 | 0.522 |
| 19 | 0.0001 | 0.0899 | 4.69 | 0.0144 | 3.45e-06 | 0.000156 | 0.000808 | 0.00212 | 0.0042 | 0.00718 | 0.0112 | 0.0163 | 0.0226 | 0.0305 | 0.0399 | 0.0514 | 0.0651 | 0.0816 | 0.102 | 0.126 | 0.158 | 0.198 | 0.256 | 0.35 | 0.535 |
| 19 | 0.0001 | 0.0899 | 4.69 | 0.0144 | 3.45e-06 | 0.000156 | 0.000808 | 0.00212 | 0.0042 | 0.00718 | 0.0112 | 0.0163 | 0.0226 | 0.0305 | 0.0399 | 0.0514 | 0.0651 | 0.0816 | 0.102 | 0.126 | 0.158 | 0.198 | 0.256 | 0.35 | 0.535 |
| 19 | 0.238 | 0.0899 | 4.69 | 0.0144 | 3.45e-06 | 0.000156 | 0.000808 | 0.00212 | 0.0042 | 0.00718 | 0.0112 | 0.0163 | 0.0226 | 0.0305 | 0.0399 | 0.0514 | 0.0651 | 0.0816 | 0.102 | 0.126 | 0.158 | 0.198 | 0.256 | 0.35 | 0.535 |
| 19 | 0.182 | 0.0899 | 4.69 | 0.0144 | 3.45e-06 | 0.000156 | 0.000808 | 0.00212 | 0.0042 | 0.00718 | 0.0112 | 0.0163 | 0.0226 | 0.0305 | 0.0399 | 0.0514 | 0.0651 | 0.0816 | 0.102 | 0.126 | 0.158 | 0.198 | 0.256 | 0.35 | 0.535 |
| 20 | 0.0001 | 0.0969 | 4.69 | 0.0154 | 7.76e-06 | 0.000267 | 0.00123 | 0.003 | 0.00568 | 0.00935 | 0.0141 | 0.0201 | 0.0273 | 0.0361 | 0.0465 | 0.059 | 0.0737 | 0.0913 | 0.112 | 0.138 | 0.17 | 0.212 | 0.27 | 0.365 | 0.549 |
| 21 | 0.179 | 0.104 | 4.69 | 0.0164 | 1.64e-05 | 0.000438 | 0.00181 | 0.00415 | 0.00752 | 0.012 | 0.0176 | 0.0244 | 0.0326 | 0.0424 | 0.0538 | 0.0673 | 0.0831 | 0.102 | 0.124 | 0.151 | 0.184 | 0.226 | 0.285 | 0.38 | 0.563 |
| 21 | 0.154 | 0.104 | 4.69 | 0.0164 | 1.64e-05 | 0.000438 | 0.00181 | 0.00415 | 0.00752 | 0.012 | 0.0176 | 0.0244 | 0.0326 | 0.0424 | 0.0538 | 0.0673 | 0.0831 | 0.102 | 0.124 | 0.151 | 0.184 | 0.226 | 0.285 | 0.38 | 0.563 |
| 21 | 0.273 | 0.104 | 4.69 | 0.0164 | 1.64e-05 | 0.000438 | 0.00181 | 0.00415 | 0.00752 | 0.012 | 0.0176 | 0.0244 | 0.0326 | 0.0424 | 0.0538 | 0.0673 | 0.0831 | 0.102 | 0.124 | 0.151 | 0.184 | 0.226 | 0.285 | 0.38 | 0.563 |
| 21 | 0.278 | 0.104 | 4.69 | 0.0164 | 1.64e-05 | 0.000438 | 0.00181 | 0.00415 | 0.00752 | 0.012 | 0.0176 | 0.0244 | 0.0326 | 0.0424 | 0.0538 | 0.0673 | 0.0831 | 0.102 | 0.124 | 0.151 | 0.184 | 0.226 | 0.285 | 0.38 | 0.563 |
| 21 | 0.0001 | 0.104 | 4.69 | 0.0164 | 1.64e-05 | 0.000438 | 0.00181 | 0.00415 | 0.00752 | 0.012 | 0.0176 | 0.0244 | 0.0326 | 0.0424 | 0.0538 | 0.0673 | 0.0831 | 0.102 | 0.124 | 0.151 | 0.184 | 0.226 | 0.285 | 0.38 | 0.563 |
| 22 | 0.296 | 0.112 | 4.69 | 0.0175 | 3.28e-05 | 0.000694 | 0.00259 | 0.00562 | 0.00978 | 0.0151 | 0.0216 | 0.0294 | 0.0386 | 0.0494 | 0.0618 | 0.0763 | 0.0931 | 0.113 | 0.136 | 0.164 | 0.198 | 0.241 | 0.301 | 0.396 | 0.577 |
| 22 | 0.0456 | 0.112 | 4.69 | 0.0175 | 3.28e-05 | 0.000694 | 0.00259 | 0.00562 | 0.00978 | 0.0151 | 0.0216 | 0.0294 | 0.0386 | 0.0494 | 0.0618 | 0.0763 | 0.0931 | 0.113 | 0.136 | 0.164 | 0.198 | 0.241 | 0.301 | 0.396 | 0.577 |
| 23 | 0.333 | 0.121 | 4.69 | 0.0187 | 6.23e-05 | 0.00106 | 0.00362 | 0.00746 | 0.0125 | 0.0188 | 0.0263 | 0.0351 | 0.0453 | 0.057 | 0.0705 | 0.086 | 0.104 | 0.124 | 0.149 | 0.177 | 0.212 | 0.256 | 0.317 | 0.412 | 0.591 |
| 23 | 0.26 | 0.121 | 4.69 | 0.0187 | 6.23e-05 | 0.00106 | 0.00362 | 0.00746 | 0.0125 | 0.0188 | 0.0263 | 0.0351 | 0.0453 | 0.057 | 0.0705 | 0.086 | 0.104 | 0.124 | 0.149 | 0.177 | 0.212 | 0.256 | 0.317 | 0.412 | 0.591 |
| 23 | 0.105 | 0.121 | 4.69 | 0.0187 | 6.23e-05 | 0.00106 | 0.00362 | 0.00746 | 0.0125 | 0.0188 | 0.0263 | 0.0351 | 0.0453 | 0.057 | 0.0705 | 0.086 | 0.104 | 0.124 | 0.149 | 0.177 | 0.212 | 0.256 | 0.317 | 0.412 | 0.591 |
| 23 | 0.0527 | 0.121 | 4.69 | 0.0187 | 6.23e-05 | 0.00106 | 0.00362 | 0.00746 | 0.0125 | 0.0188 | 0.0263 | 0.0351 | 0.0453 | 0.057 | 0.0705 | 0.086 | 0.104 | 0.124 | 0.149 | 0.177 | 0.212 | 0.256 | 0.317 | 0.412 | 0.591 |
| 23 | 0.231 | 0.121 | 4.69 | 0.0187 | 6.23e-05 | 0.00106 | 0.00362 | 0.00746 | 0.0125 | 0.0188 | 0.0263 | 0.0351 | 0.0453 | 0.057 | 0.0705 | 0.086 | 0.104 | 0.124 | 0.149 | 0.177 | 0.212 | 0.256 | 0.317 | 0.412 | 0.591 |
| 23 | 0.0589 | 0.121 | 4.69 | 0.0187 | 6.23e-05 | 0.00106 | 0.00362 | 0.00746 | 0.0125 | 0.0188 | 0.0263 | 0.0351 | 0.0453 | 0.057 | 0.0705 | 0.086 | 0.104 | 0.124 | 0.149 | 0.177 | 0.212 | 0.256 | 0.317 | 0.412 | 0.591 |
| 24 | 0.25 | 0.13 | 4.69 | 0.0199 | 0.000113 | 0.00158 | 0.00496 | 0.00972 | 0.0158 | 0.023 | 0.0316 | 0.0414 | 0.0527 | 0.0655 | 0.08 | 0.0964 | 0.115 | 0.137 | 0.162 | 0.191 | 0.227 | 0.272 | 0.333 | 0.428 | 0.605 |
| 24 | 0.0456 | 0.13 | 4.69 | 0.0199 | 0.000113 | 0.00158 | 0.00496 | 0.00972 | 0.0158 | 0.023 | 0.0316 | 0.0414 | 0.0527 | 0.0655 | 0.08 | 0.0964 | 0.115 | 0.137 | 0.162 | 0.191 | 0.227 | 0.272 | 0.333 | 0.428 | 0.605 |
| 24 | 0.179 | 0.13 | 4.69 | 0.0199 | 0.000113 | 0.00158 | 0.00496 | 0.00972 | 0.0158 | 0.023 | 0.0316 | 0.0414 | 0.0527 | 0.0655 | 0.08 | 0.0964 | 0.115 | 0.137 | 0.162 | 0.191 | 0.227 | 0.272 | 0.333 | 0.428 | 0.605 |
| 24 | 0.0001 | 0.13 | 4.69 | 0.0199 | 0.000113 | 0.00158 | 0.00496 | 0.00972 | 0.0158 | 0.023 | 0.0316 | 0.0414 | 0.0527 | 0.0655 | 0.08 | 0.0964 | 0.115 | 0.137 | 0.162 | 0.191 | 0.227 | 0.272 | 0.333 | 0.428 | 0.605 |
| 24 | 0.0626 | 0.13 | 4.69 | 0.0199 | 0.000113 | 0.00158 | 0.00496 | 0.00972 | 0.0158 | 0.023 | 0.0316 | 0.0414 | 0.0527 | 0.0655 | 0.08 | 0.0964 | 0.115 | 0.137 | 0.162 | 0.191 | 0.227 | 0.272 | 0.333 | 0.428 | 0.605 |
| 25 | 0.25 | 0.14 | 4.69 | 0.0211 | 0.000195 | 0.00229 | 0.00664 | 0.0125 | 0.0196 | 0.0279 | 0.0376 | 0.0485 | 0.0608 | 0.0746 | 0.0902 | 0.108 | 0.127 | 0.15 | 0.176 | 0.206 | 0.243 | 0.289 | 0.35 | 0.445 | 0.62 |
| 26 | 0.0501 | 0.15 | 4.69 | 0.0224 | 0.000325 | 0.00322 | 0.00872 | 0.0157 | 0.024 | 0.0335 | 0.0443 | 0.0563 | 0.0697 | 0.0846 | 0.101 | 0.12 | 0.14 | 0.164 | 0.191 | 0.222 | 0.259 | 0.306 | 0.367 | 0.462 | 0.634 |
| 26 | 0.31 | 0.15 | 4.69 | 0.0224 | 0.000325 | 0.00322 | 0.00872 | 0.0157 | 0.024 | 0.0335 | 0.0443 | 0.0563 | 0.0697 | 0.0846 | 0.101 | 0.12 | 0.14 | 0.164 | 0.191 | 0.222 | 0.259 | 0.306 | 0.367 | 0.462 | 0.634 |
| 26 | 0.107 | 0.15 | 4.69 | 0.0224 | 0.000325 | 0.00322 | 0.00872 | 0.0157 | 0.024 | 0.0335 | 0.0443 | 0.0563 | 0.0697 | 0.0846 | 0.101 | 0.12 | 0.14 | 0.164 | 0.191 | 0.222 | 0.259 | 0.306 | 0.367 | 0.462 | 0.634 |
| 28 | 0.0691 | 0.172 | 4.69 | 0.025 | 0.00081 | 0.00599 | 0.0143 | 0.024 | 0.0349 | 0.0469 | 0.06 | 0.0743 | 0.0899 | 0.107 | 0.125 | 0.146 | 0.168 | 0.194 | 0.222 | 0.255 | 0.294 | 0.341 | 0.403 | 0.497 | 0.664 |
| 28 | 0.22 | 0.172 | 4.69 | 0.025 | 0.00081 | 0.00599 | 0.0143 | 0.024 | 0.0349 | 0.0469 | 0.06 | 0.0743 | 0.0899 | 0.107 | 0.125 | 0.146 | 0.168 | 0.194 | 0.222 | 0.255 | 0.294 | 0.341 | 0.403 | 0.497 | 0.664 |
| 28 | 0.22 | 0.172 | 4.69 | 0.025 | 0.00081 | 0.00599 | 0.0143 | 0.024 | 0.0349 | 0.0469 | 0.06 | 0.0743 | 0.0899 | 0.107 | 0.125 | 0.146 | 0.168 | 0.194 | 0.222 | 0.255 | 0.294 | 0.341 | 0.403 | 0.497 | 0.664 |
| 28 | 0.235 | 0.172 | 4.69 | 0.025 | 0.00081 | 0.00599 | 0.0143 | 0.024 | 0.0349 | 0.0469 | 0.06 | 0.0743 | 0.0899 | 0.107 | 0.125 | 0.146 | 0.168 | 0.194 | 0.222 | 0.255 | 0.294 | 0.341 | 0.403 | 0.497 | 0.664 |
| 30 | 0.1 | 0.197 | 4.69 | 0.0278 | 0.00178 | 0.0103 | 0.0222 | 0.035 | 0.0488 | 0.0634 | 0.079 | 0.0956 | 0.113 | 0.132 | 0.153 | 0.175 | 0.2 | 0.226 | 0.256 | 0.29 | 0.33 | 0.378 | 0.441 | 0.533 | 0.694 |
| 30 | 0.154 | 0.197 | 4.69 | 0.0278 | 0.00178 | 0.0103 | 0.0222 | 0.035 | 0.0488 | 0.0634 | 0.079 | 0.0956 | 0.113 | 0.132 | 0.153 | 0.175 | 0.2 | 0.226 | 0.256 | 0.29 | 0.33 | 0.378 | 0.441 | 0.533 | 0.694 |
| 32 | 0.111 | 0.224 | 4.69 | 0.0306 | 0.00353 | 0.0166 | 0.0327 | 0.049 | 0.0659 | 0.0833 | 0.101 | 0.12 | 0.14 | 0.161 | 0.184 | 0.208 | 0.234 | 0.262 | 0.293 | 0.328 | 0.369 | 0.418 | 0.48 | 0.571 | 0.725 |
| 32 | 0.0858 | 0.224 | 4.69 | 0.0306 | 0.00353 | 0.0166 | 0.0327 | 0.049 | 0.0659 | 0.0833 | 0.101 | 0.12 | 0.14 | 0.161 | 0.184 | 0.208 | 0.234 | 0.262 | 0.293 | 0.328 | 0.369 | 0.418 | 0.48 | 0.571 | 0.725 |
| 33 | 0.154 | 0.239 | 4.69 | 0.0319 | 0.00481 | 0.0206 | 0.039 | 0.0573 | 0.0757 | 0.0946 | 0.114 | 0.134 | 0.155 | 0.177 | 0.2 | 0.225 | 0.252 | 0.281 | 0.313 | 0.348 | 0.389 | 0.438 | 0.5 | 0.589 | 0.74 |
| 35 | 0.25 | 0.27 | 4.69 | 0.0346 | 0.0084 | 0.0306 | 0.0541 | 0.0763 | 0.0981 | 0.12 | 0.142 | 0.164 | 0.187 | 0.211 | 0.236 | 0.262 | 0.29 | 0.32 | 0.353 | 0.39 | 0.431 | 0.479 | 0.54 | 0.628 | 0.77 |
| 36 | 0.1 | 0.287 | 4.69 | 0.0359 | 0.0108 | 0.0366 | 0.0629 | 0.0872 | 0.111 | 0.134 | 0.157 | 0.18 | 0.204 | 0.229 | 0.255 | 0.282 | 0.311 | 0.341 | 0.374 | 0.411 | 0.452 | 0.501 | 0.561 | 0.647 | 0.785 |
#modelpropFr$precision
#quantile_many=predict(modelpropFr, type = "quantile", at=c(.99))
#quantile_manyAl construir la figura para la regresión beta, una de las principales ventajas de utilizar este enfoque es que los cuartiles se calcula con una distribución beta. Por lo tanto, el margen de error NO baja de 0 y NO pasa de 1.
Evalua la siguiente figura en cada x hay una distribución beta, donde la linea roja representa una mediana, las lineas verdes son los cuartiles 25 y 75 y las lineas azules las percentilas 5 y 95. NOTA que la distribución no es simétrica, y cambia a travez de la regresión.
library(ggplot2)
ggplot(dp2, aes(x=Number_of_Flowers, y=PropFR))+
geom_point()+
geom_line(aes(y=quantile_.05), linetype="twodash", colour="blue")+
geom_line(aes(y=quantile_.25),linetype=2, colour="green")+
geom_line(aes(y=quantile_.50), colour="red")+
geom_line(aes(y=quantile_.75), linetype=2, colour="green")+
geom_line(aes(y=quantile_.95), linetype="twodash", colour="blue")+
ylab("Predicción de la proporción de frutos")+
xlab("Números de Flores")+
annotate("text", x=25, y=0.50, label="95th quartile", fontface="italic")+
annotate("text", x=32, y=0.39, label="75th quartile", fontface="italic")+
annotate("text", x=33, y=0.14, label="25th quartile", fontface="italic")+
annotate("text", x=33, y=0.27, label="Median", fontface="italic")+
annotate("text", x=35, y=-0.02, label="5th quartile", fontface="italic")+
theme(axis.title.y = element_text(colour="grey20",size=20,face="bold"),
axis.text.x = element_text(colour="grey20",size=20,face="bold"),
axis.text.y = element_text(colour="grey20",size=20,face="bold"),
axis.title.x = element_text(colour="grey20",size=20,face="bold"))+
theme(legend.position="none")+
rlt_theme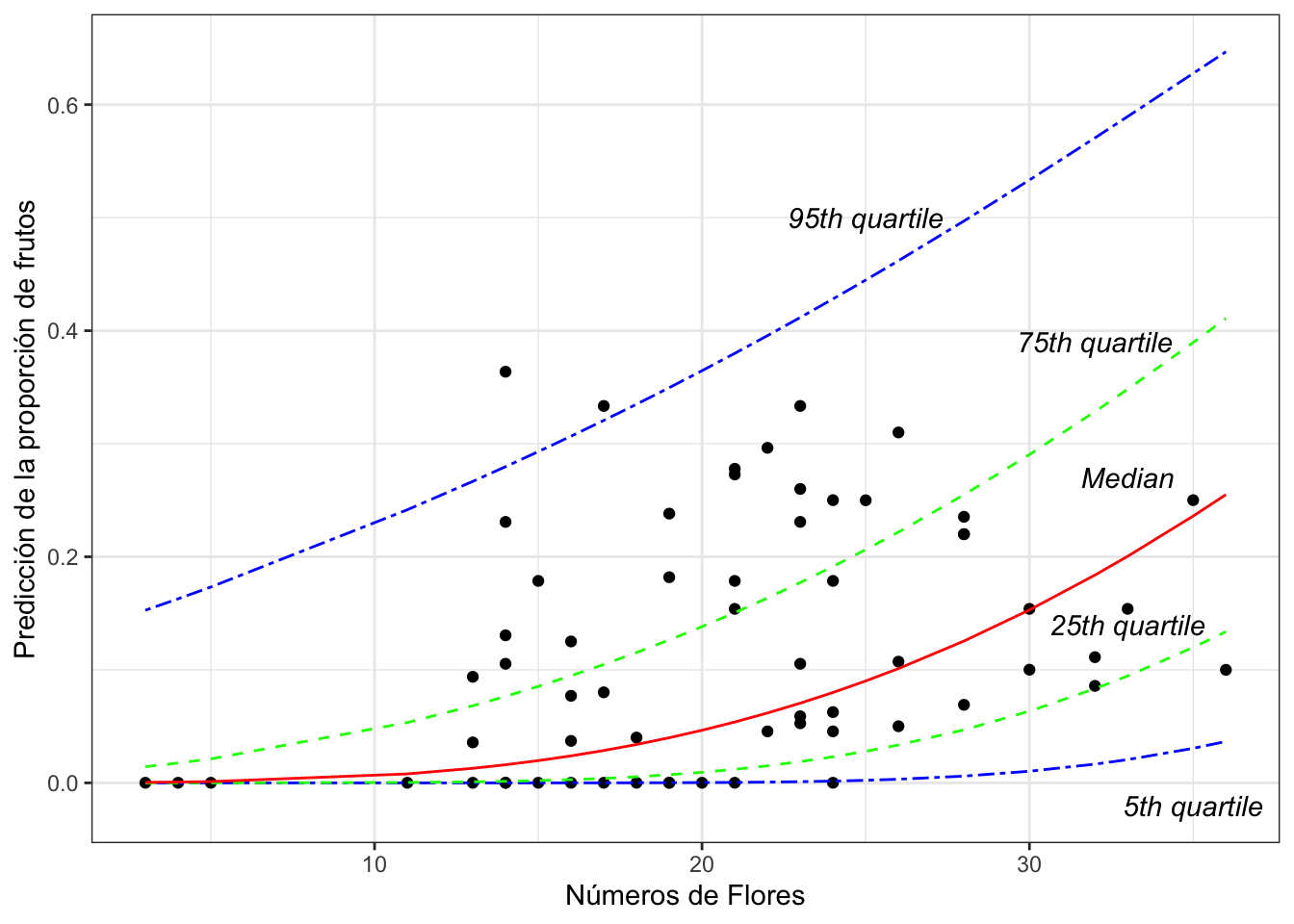
## Saving 7 x 5 in imageEsto es una representación de las distribuciones beta en las x, número de flores. En rojo simulamos la distribución de la proporción esperada de frutos en plantas que tienen 15 flores y en la linea azul simulamos la distribución esperada de la proporción de frutos en plantas con 30 flores.
Comparar el modelo tradicional lineal versus un modelo beta
Para comparar efectivadad de los modelos usamos el Akaike Information Criterion (AIC). En un acercmiento de selección modelo se acepta como mejor modelo el indice de AIC más pequeño, que representa el modelo meas parsimonio. Una diferencia de AIC DE 4 es significativo. Nota que el modelo beta es mucho mejor (AIC = -219) que el modelo de regresión lineal (AIC = -102)
#AIC(modelpropFr) # modelo beta
modelpropFr_lm=lm(PropFR~Number_of_Flowers, data=dp2)
AIC(modelpropFr,modelpropFr_lm)| df | AIC |
|---|---|
| 3 | -220 |
| 3 | -102 |
Distribución de valores especificos
Evaluando la distribución de beta para valores específicos de x= Proporción de frutos por plantas basado en la cantidad de flores en la planta.
Seleccionar los diferentes valores de x y calcular el promedio y la varianza y convertir estos en \(\alpha\) y \(\beta\). Con estos parámetros se puede construir la densidad de la distribución por cada valor de x.
Se seleccionan valores específicos para la visualizar la distribución, las plantas que tienen 25, 30 y 35 flores. Se tiene que reorganizar los datos para calcular el promedio y la varianza.
dpQ=dp2 %>%
dplyr::select(c(1, 6:26))
dpQ2=dpQ%>%
filter(Number_of_Flowers== 35) %>% dplyr::select(c(2:22))%>% t %>% as.data.frame
dpQ2$Quartiles=c(.01, 0.05, .1, .15, .2, .25, .30, .35, .4, .45, .5, .55, .6, .65, .7,.75, .8, .85, .9, .95, .99 )
mean(dpQ2$V1, na.rm=FALSE)## [1] 0.2757771## [1] 0.04226223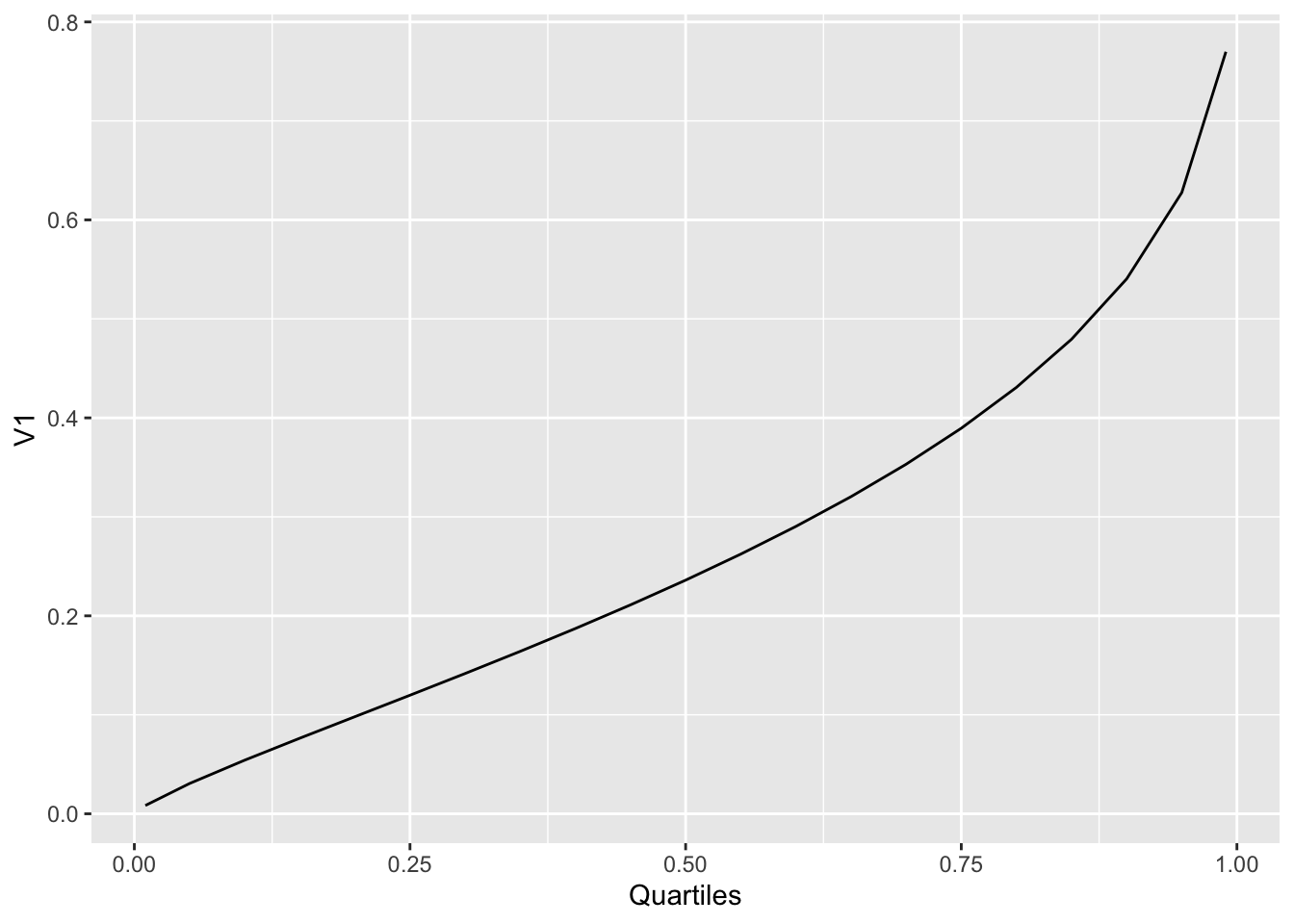
Usando la varianza calculada en el chunk anterior, se puede calcular el \(\alpha\) y el \(\beta\).
estBetaParams <- function(mu, var) {
alpha <- ((1 - mu) / var - 1 / mu) * mu ^ 2
beta <- alpha * (1 / mu - 1)
return(params = list(alpha = alpha, beta = beta))
}
#mean(Smokers$Y2000P)
#var(Smokers$Y2000P)
estBetaParams(0.2757771,0.04226223)## $alpha
## [1] 1.027498
##
## $beta
## [1] 2.698331Producción de los gráficos. Se observa que para las plantas que tienen 25 y 30 flores la densidad esta sesgada a la izquierda, en otra palabra la probabilidad de tener pocas frutos domina la distribuciones.
library(gridExtra)
a=ggplot(dipodium2, aes(PropFR))+
stat_function(aes(x = dipodium2$PropFR, y = ..y..), fun = dbeta, colour="red", n = 62,
args = list(shape1 =0.5418068, shape2 =3.135593))+
ylab("Beta \nDensity")+
xlab("Probabilidad de tener frutos")+
coord_cartesian(xlim=c(0,0.05))+
ggtitle("Densidad beta para plantas con 25 flores")
b=ggplot(dipodium2, aes(PropFR))+
stat_function(aes(x = dipodium2$PropFR, y = ..y..), fun = dbeta, colour="blue", n = 62,
args = list(shape1 = 0.7549048, shape2 =2.949404))+
ylab("Beta \nDensity")+
xlab("Probabilidad de tener frutos")+
coord_cartesian(xlim=c(0,0.1))+
ggtitle("Densidad beta para plantas con 30 flores")
c=ggplot(dipodium2, aes(PropFR))+
stat_function(aes(x = dipodium2$PropFR, y = ..y..), fun = dbeta, colour="black", n = 62,
args = list(shape1 = 1.027498, shape2 =2.698331))+
ylab("Beta \nDensity")+
xlab("Probabilidad de tener frutos")+
coord_cartesian(xlim=c(0,0.10))+
ggtitle("Densidad beta para plantas con 35 flores")
tresDensidad=grid.arrange(a,b,c, ncol=1)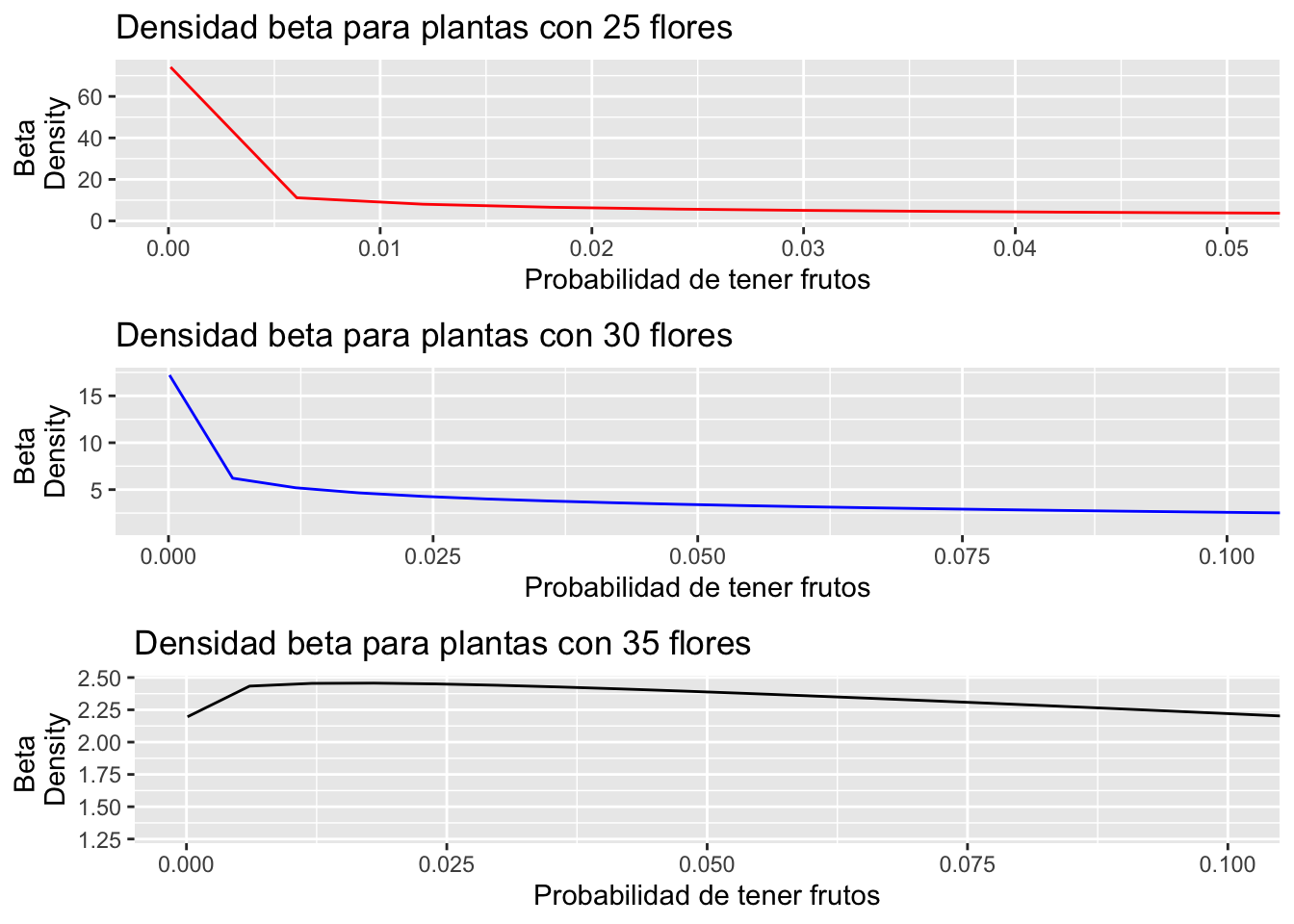
## TableGrob (3 x 1) "arrange": 3 grobs
## z cells name grob
## 1 1 (1-1,1-1) arrange gtable[layout]
## 2 2 (2-2,1-1) arrange gtable[layout]
## 3 3 (3-3,1-1) arrange gtable[layout]## Saving 7 x 5 in imageUn segundo ejemplo
data("StressAnxiety", package = "betareg")
StressAnxiety <- StressAnxiety[order(StressAnxiety$stress),]
## Smithson & Verkuilen (2006, Table 4)
sa_null <- betareg(anxiety ~ 1 | 1,
data = StressAnxiety, hessian = TRUE)
sa_stress <- betareg(anxiety ~ stress | stress,
data = StressAnxiety, hessian = TRUE)
summary(sa_null)##
## Call:
## betareg(formula = anxiety ~ 1 | 1, data = StressAnxiety, hessian = TRUE)
##
## Standardized weighted residuals 2:
## Min 1Q Median 3Q Max
## -0.6806 -0.6806 -0.2705 0.6581 2.0002
##
## Coefficients (mean model with logit link):
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -2.24396 0.09879 -22.71 <2e-16 ***
##
## Phi coefficients (precision model with log link):
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 1.796 0.123 14.6 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Type of estimator: ML (maximum likelihood)
## Log-likelihood: 239.4 on 2 Df
## Number of iterations in BFGS optimization: 9##
## Call:
## betareg(formula = anxiety ~ stress | stress, data = StressAnxiety, hessian = TRUE)
##
## Standardized weighted residuals 2:
## Min 1Q Median 3Q Max
## -2.3686 -0.6704 -0.0024 0.6213 2.0510
##
## Coefficients (mean model with logit link):
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -4.0237 0.1442 -27.90 <2e-16 ***
## stress 4.9414 0.4409 11.21 <2e-16 ***
##
## Phi coefficients (precision model with log link):
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) 3.9608 0.2511 15.776 < 2e-16 ***
## stress -4.2733 0.7532 -5.674 1.4e-08 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Type of estimator: ML (maximum likelihood)
## Log-likelihood: 302 on 4 Df
## Pseudo R-squared: 0.4748
## Number of iterations in BFGS optimization: 16| df | AIC |
|---|---|
| 2 | -475 |
| 4 | -596 |
## [1] 0.207021## visualization
attach(StressAnxiety)
plot(jitter(anxiety) ~ jitter(stress),
xlab = "Stress", ylab = "Anxiety",
xlim = c(0, 1), ylim = c(0, 1))
lines(lowess(anxiety ~ stress))
lines(fitted(sa_stress) ~ stress, lty = 2)
lines(fitted(lm(anxiety ~ stress)) ~ stress, lty = 3)
legend("topleft", c("lowess", "betareg", "lm"), lty = 1:3, bty = "n")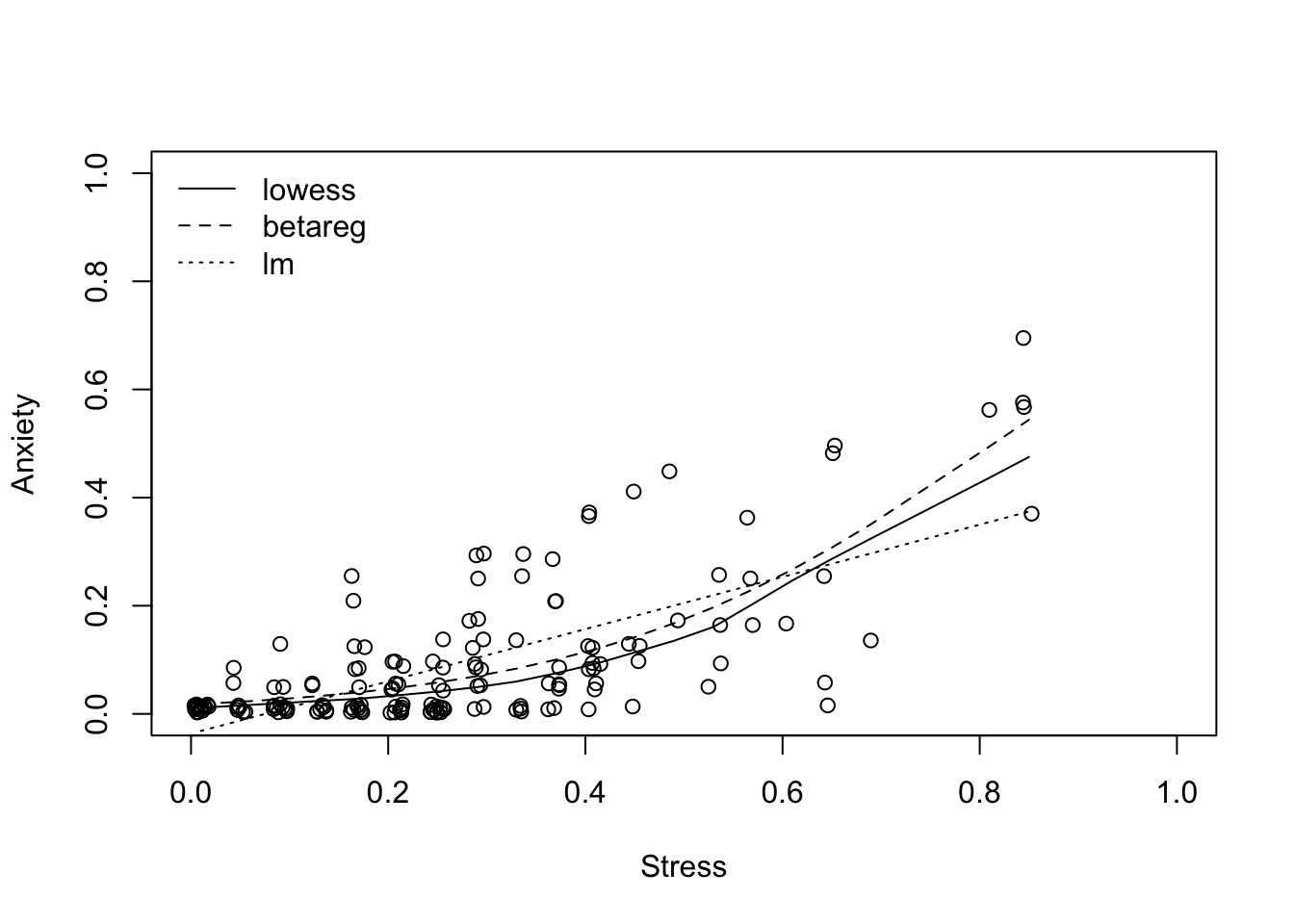
For an excellent new step by step use of the beta regression and why it is usefull see this website.
https://www.andrewheiss.com/blog/2021/11/08/beta-regression-guide/
“Activities reported in this website was supported by the National Institute of General Medical Sciences of the National Institutes of Health under Award Number R25GM121270. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.”
