Capítulo10 Transformación: Mutate, transmute, lag, lead, cumsum, cummean, cumvar
10.1 Funciones en este módulo
- mutate() # crea nuevas variables
- transmute() # crea nuevas variables y elimina las antiguas
- lag() # calcula la diferencia entre valores en la misma columna
- lead() # calcula el siguiente valor en un vector
- cumsum() # suma cumulativa
- cummean() # promedio cumulativo
- cumvar() # varianza cumulativa## [1] "anio" "mes" "dia"
## [4] "horario_salida" "salida_programada" "atraso_salida"
## [7] "horario_llegada" "llegada_programada" "atraso_llegada"
## [10] "aerolinea" "vuelo" "codigo_cola"
## [13] "origen" "destino" "tiempo_vuelo"
## [16] "distancia" "hora" "minuto"
## [19] "fecha_hora"# |> es igual %>%
new_df=vuelos |> dplyr::select(distancia, tiempo_vuelo, atraso_salida, atraso_llegada) |>
mutate( ganancia = atraso_salida - atraso_llegada,
velocidad = distancia / tiempo_vuelo * 60)
new_df## # A tibble: 336,776 × 6
## distancia tiempo_vuelo atraso_salida atraso_llegada ganancia velocidad
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1400 227 2 11 -9 370.
## 2 1416 227 4 20 -16 374.
## 3 1089 160 2 33 -31 408.
## 4 1576 183 -1 -18 17 517.
## 5 762 116 -6 -25 19 394.
## 6 719 150 -4 12 -16 288.
## 7 1065 158 -5 19 -24 404.
## 8 229 53 -3 -14 11 259.
## 9 944 140 -3 -8 5 405.
## 10 733 138 -2 8 -10 319.
## # ℹ 336,766 more rows10.2 Crear un data frame más pequeño con las variables de interés
## # A tibble: 6 × 19
## year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
## <int> <int> <int> <int> <int> <dbl> <int> <int>
## 1 2013 1 1 517 515 2 830 819
## 2 2013 1 1 533 529 4 850 830
## 3 2013 1 1 542 540 2 923 850
## 4 2013 1 1 544 545 -1 1004 1022
## 5 2013 1 1 554 600 -6 812 837
## 6 2013 1 1 554 558 -4 740 728
## # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
## # tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
## # hour <dbl>, minute <dbl>, time_hour <dttm>## [1] "anio" "mes" "dia"
## [4] "horario_salida" "salida_programada" "atraso_salida"
## [7] "horario_llegada" "llegada_programada" "atraso_llegada"
## [10] "aerolinea" "vuelo" "codigo_cola"
## [13] "origen" "destino" "tiempo_vuelo"
## [16] "distancia" "hora" "minuto"
## [19] "fecha_hora" vuelos_sml <- dplyr::select(vuelos,
anio:dia,
starts_with("atraso"),
distancia,
tiempo_vuelo
)
head(vuelos_sml)## # A tibble: 6 × 7
## anio mes dia atraso_salida atraso_llegada distancia tiempo_vuelo
## <int> <int> <int> <dbl> <dbl> <dbl> <dbl>
## 1 2013 1 1 2 11 1400 227
## 2 2013 1 1 4 20 1416 227
## 3 2013 1 1 2 33 1089 160
## 4 2013 1 1 -1 -18 1576 183
## 5 2013 1 1 -6 -25 762 116
## 6 2013 1 1 -4 12 719 15010.3 Crear nuevas variables
mutate(vuelos_sml,
ganado = atraso_salida - atraso_llegada,
velocidad = distancia / tiempo_vuelo * 60
)## # A tibble: 336,776 × 9
## anio mes dia atraso_salida atraso_llegada distancia tiempo_vuelo ganado
## <int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 2013 1 1 2 11 1400 227 -9
## 2 2013 1 1 4 20 1416 227 -16
## 3 2013 1 1 2 33 1089 160 -31
## 4 2013 1 1 -1 -18 1576 183 17
## 5 2013 1 1 -6 -25 762 116 19
## 6 2013 1 1 -4 12 719 150 -16
## 7 2013 1 1 -5 19 1065 158 -24
## 8 2013 1 1 -3 -14 229 53 11
## 9 2013 1 1 -3 -8 944 140 5
## 10 2013 1 1 -2 8 733 138 -10
## # ℹ 336,766 more rows
## # ℹ 1 more variable: velocidad <dbl>10.4 transmute()
Para guardar solamente la nueva variable usa transmute
flights |> transmute(
gain = dep_delay - arr_delay,
hours = air_time / 60,
gain_per_hour = gain / hours
)## # A tibble: 336,776 × 3
## gain hours gain_per_hour
## <dbl> <dbl> <dbl>
## 1 -9 3.78 -2.38
## 2 -16 3.78 -4.23
## 3 -31 2.67 -11.6
## 4 17 3.05 5.57
## 5 19 1.93 9.83
## 6 -16 2.5 -6.4
## 7 -24 2.63 -9.11
## 8 11 0.883 12.5
## 9 5 2.33 2.14
## 10 -10 2.3 -4.35
## # ℹ 336,766 more rows10.5 lag()
Para calcular diferencias entre variables en la misma columna
set.seed(12345) # que los datos sean al azar, siempre sean los mismo, se usa el "set.seed()" para enseñanza.
#rnorm() DATOS CON DISTRIBUCION NORMAL
data=rpois(14, 10)
df=as_tibble(data)
df## # A tibble: 14 × 1
## value
## <int>
## 1 11
## 2 12
## 3 9
## 4 8
## 5 11
## 6 4
## 7 11
## 8 7
## 9 8
## 10 11
## 11 9
## 12 10
## 13 9
## 14 11df %>%
dplyr::select(value) %>%
mutate(lag1=lag(value)) %>%
mutate(lag3=lag(value, 3)) %>%
mutate(lag7=lag(value,5))## # A tibble: 14 × 4
## value lag1 lag3 lag7
## <int> <int> <int> <int>
## 1 11 NA NA NA
## 2 12 11 NA NA
## 3 9 12 NA NA
## 4 8 9 11 NA
## 5 11 8 12 NA
## 6 4 11 9 11
## 7 11 4 8 12
## 8 7 11 11 9
## 9 8 7 4 8
## 10 11 8 11 11
## 11 9 11 7 4
## 12 10 9 8 11
## 13 9 10 11 7
## 14 11 9 9 8## Calcular la diferencia usando lag
df %>%
dplyr::select(value) %>%
mutate(lag1=lag(value)) %>%
mutate(Changes=value-lag(value, 1)) # El cambio en posición de los valores entre las filas## # A tibble: 14 × 3
## value lag1 Changes
## <int> <int> <int>
## 1 11 NA NA
## 2 12 11 1
## 3 9 12 -3
## 4 8 9 -1
## 5 11 8 3
## 6 4 11 -7
## 7 11 4 7
## 8 7 11 -4
## 9 8 7 1
## 10 11 8 3
## 11 9 11 -2
## 12 10 9 1
## 13 9 10 -1
## 14 11 9 210.6 Usa “Lag” con “IncCasosSaludNuevo” en COVID-19 PR
Evalúa la diferencia en números de casos entre 7 días de la semana en números de casos nuevos de COVID, “IncCasosSaludNuevo”
library(readr)
library(dplyr)
#names(url_COVID_PR)
url_COVID_PR <- read_csv("Datos/url_COVID_PR.csv")
head(url_COVID_PR, 100)## # A tibble: 100 × 18
## ...1 Fecha Muertes IncrementoMuertes CasosPCR_Salud IncCasosPCR_Salud
## <dbl> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 1 3/12/20 0 0 NA NA
## 2 2 3/13/20 0 0 NA NA
## 3 3 3/14/20 0 0 NA NA
## 4 4 3/15/20 0 0 NA NA
## 5 5 3/16/20 0 0 NA NA
## 6 6 3/17/20 0 0 NA NA
## 7 7 3/18/20 0 0 NA NA
## 8 8 3/19/20 0 0 NA NA
## 9 9 3/20/20 0 0 NA NA
## 10 10 3/21/20 0 0 NA NA
## # ℹ 90 more rows
## # ℹ 12 more variables: CasosSaludNuevo <dbl>, IncCasosSaludNuevo <dbl>,
## # HospitCOV19 <dbl>, CamasICU <dbl>, CamasICU_disp <dbl>, Ventiladores <dbl>,
## # MuertesSalud <dbl>, IncMueSalud <dbl>, VacDoses <dbl>, VacAdm <dbl>,
## # N1MoreDoses <dbl>, N2Doses <dbl>## [1] "...1" "Fecha" "Muertes"
## [4] "IncrementoMuertes" "CasosPCR_Salud" "IncCasosPCR_Salud"
## [7] "CasosSaludNuevo" "IncCasosSaludNuevo" "HospitCOV19"
## [10] "CamasICU" "CamasICU_disp" "Ventiladores"
## [13] "MuertesSalud" "IncMueSalud" "VacDoses"
## [16] "VacAdm" "N1MoreDoses" "N2Doses"df2=url_COVID_PR %>%
dplyr::select(IncCasosSaludNuevo) %>%
mutate(Cambios_Casos=IncCasosSaludNuevo-lag(IncCasosSaludNuevo,7))
df2## # A tibble: 587 × 2
## IncCasosSaludNuevo Cambios_Casos
## <dbl> <dbl>
## 1 2 NA
## 2 3 NA
## 3 3 NA
## 4 0 NA
## 5 9 NA
## 6 7 NA
## 7 6 NA
## 8 5 3
## 9 14 11
## 10 12 9
## # ℹ 577 more rows## IncCasosSaludNuevo Cambios_Casos
## 257.8310580 0.450777210.7 lead(),
is the “next” (lead()) values in a vector/column
## # A tibble: 15 × 1
## value
## <int>
## 1 11
## 2 12
## 3 9
## 4 8
## 5 11
## 6 4
## 7 11
## 8 7
## 9 8
## 10 11
## 11 9
## 12 10
## 13 9
## 14 11
## 15 13## # A tibble: 15 × 3
## value lead1 lead3
## <int> <int> <int>
## 1 11 12 8
## 2 12 9 11
## 3 9 8 4
## 4 8 11 11
## 5 11 4 7
## 6 4 11 8
## 7 11 7 11
## 8 7 8 9
## 9 8 11 10
## 10 11 9 9
## 11 9 10 11
## 12 10 9 13
## 13 9 11 NA
## 14 11 13 NA
## 15 13 NA NA# Calculate the change in value from one (1) time period and four (4) time periods
df%>%
dplyr::select(value) %>%
mutate(lead1=value-lead(value)) %>%
mutate(lead7=value-lead(value, 7))## # A tibble: 15 × 3
## value lead1 lead7
## <int> <int> <int>
## 1 11 -1 4
## 2 12 3 4
## 3 9 1 -2
## 4 8 -3 -1
## 5 11 7 1
## 6 4 -7 -5
## 7 11 4 0
## 8 7 -1 -6
## 9 8 -3 NA
## 10 11 2 NA
## 11 9 -1 NA
## 12 10 1 NA
## 13 9 -2 NA
## 14 11 -2 NA
## 15 13 NA NA10.8 cumsum
Suma cumulativa: los valores se suman a los largo del vector o columna
set.seed(12345) # set.seed() es para que los datos NO sean al azar y se puede replicar los resultados, tipicamente esto se usa para enseñanzar.
x <- sample(1:15, 10, replace=TRUE) # sample es para seleccionar valores al azar de un vector
x## [1] 14 3 10 12 8 10 13 11 8 2## # A tibble: 10 × 1
## value
## <int>
## 1 14
## 2 3
## 3 10
## 4 12
## 5 8
## 6 10
## 7 13
## 8 11
## 9 8
## 10 2## # A tibble: 10 × 2
## value suma
## <int> <int>
## 1 14 14
## 2 3 17
## 3 10 27
## 4 12 39
## 5 8 47
## 6 10 57
## 7 13 70
## 8 11 81
## 9 8 89
## 10 2 91## [1] "...1" "Fecha" "Muertes"
## [4] "IncrementoMuertes" "CasosPCR_Salud" "IncCasosPCR_Salud"
## [7] "CasosSaludNuevo" "IncCasosSaludNuevo" "HospitCOV19"
## [10] "CamasICU" "CamasICU_disp" "Ventiladores"
## [13] "MuertesSalud" "IncMueSalud" "VacDoses"
## [16] "VacAdm" "N1MoreDoses" "N2Doses"## # A tibble: 6 × 18
## ...1 Fecha Muertes IncrementoMuertes CasosPCR_Salud IncCasosPCR_Salud
## <dbl> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 1 3/12/20 0 0 NA NA
## 2 2 3/13/20 0 0 NA NA
## 3 3 3/14/20 0 0 NA NA
## 4 4 3/15/20 0 0 NA NA
## 5 5 3/16/20 0 0 NA NA
## 6 6 3/17/20 0 0 NA NA
## # ℹ 12 more variables: CasosSaludNuevo <dbl>, IncCasosSaludNuevo <dbl>,
## # HospitCOV19 <dbl>, CamasICU <dbl>, CamasICU_disp <dbl>, Ventiladores <dbl>,
## # MuertesSalud <dbl>, IncMueSalud <dbl>, VacDoses <dbl>, VacAdm <dbl>,
## # N1MoreDoses <dbl>, N2Doses <dbl>url_COVID_PR %>%
dplyr::select(IncCasosSaludNuevo, CasosSaludNuevo) %>%
mutate(suma=cumsum(IncCasosSaludNuevo))## # A tibble: 587 × 3
## IncCasosSaludNuevo CasosSaludNuevo suma
## <dbl> <dbl> <dbl>
## 1 2 2 2
## 2 3 5 5
## 3 3 8 8
## 4 0 8 8
## 5 9 17 17
## 6 7 24 24
## 7 6 30 30
## 8 5 35 35
## 9 14 49 49
## 10 12 61 61
## # ℹ 577 more rows10.9 cmean() and cvar() del paquete TidyDensity
Para calcular el promedio cumulativo y la varianza
- las funciones son
- cmean() # del paquete cumstats
- cvar() # del paquete cumstats
Para calcular el promedio en periodos cumulativos
- rollmean() # del paquete zoo
- rollapply( ) # del paquete zoo para calcular el rolling varianza
Vea las otras funciones en el paquete cumstats: hay otra que podría usar en sus estudios?
## [1] 4.999227 5.000933 5.000466 4.998915 4.997844 4.999281## # A tibble: 6 × 1
## value
## <dbl>
## 1 5.00
## 2 5.00
## 3 5.00
## 4 5.00
## 5 5.00
## 6 5.00## [1] 4.999966library(MASS)
library(TidyDensity)
library(zoo)
df3=df %>%
dplyr::select(value) %>%
mutate(Prom_cum=cmean(value)) %>%
mutate(Var_cum=TidyDensity::cvar(value)) |>
mutate(promedio_corriendo= zoo::rollmean(value, k=7, fill=NA, align="left")) |>
mutate(varianza_corriendo= zoo::rollapply(value, width=7, FUN=var, fill=NA, align="left"))
df3## # A tibble: 1,000 × 5
## value Prom_cum Var_cum promedio_corriendo varianza_corriendo
## <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 5.00 5.00 NaN 5.00 0.00000139
## 2 5.00 5.00 0.00000146 5.00 0.00000145
## 3 5.00 5.00 0.000000778 5.00 0.00000123
## 4 5.00 5.00 0.000000937 5.00 0.00000133
## 5 5.00 5.00 0.00000154 5.00 0.00000135
## 6 5.00 5.00 0.00000124 5.00 0.000000532
## 7 5.00 5.00 0.00000139 5.00 0.000000813
## 8 5.00 5.00 0.00000129 5.00 0.00000139
## 9 5.00 5.00 0.00000115 5.00 0.00000131
## 10 5.00 5.00 0.00000113 5.00 0.00000132
## # ℹ 990 more rows10.10 Uso de varianza cumulativa en investigación:
Un método para determinar si la cantidad de muestras recolectada es suficiente, es evaluar si la varianza cumulativa sigue cambiando cuando se añade nuevas recolección de datos.
## # A tibble: 1,000 × 6
## value Prom_cum Var_cum promedio_corriendo varianza_corriendo order
## <dbl> <dbl> <dbl> <dbl> <dbl> <int>
## 1 5.00 5.00 NaN 5.00 0.00000139 1
## 2 5.00 5.00 0.00000146 5.00 0.00000145 2
## 3 5.00 5.00 0.000000778 5.00 0.00000123 3
## 4 5.00 5.00 0.000000937 5.00 0.00000133 4
## 5 5.00 5.00 0.00000154 5.00 0.00000135 5
## 6 5.00 5.00 0.00000124 5.00 0.000000532 6
## 7 5.00 5.00 0.00000139 5.00 0.000000813 7
## 8 5.00 5.00 0.00000129 5.00 0.00000139 8
## 9 5.00 5.00 0.00000115 5.00 0.00000131 9
## 10 5.00 5.00 0.00000113 5.00 0.00000132 10
## # ℹ 990 more rows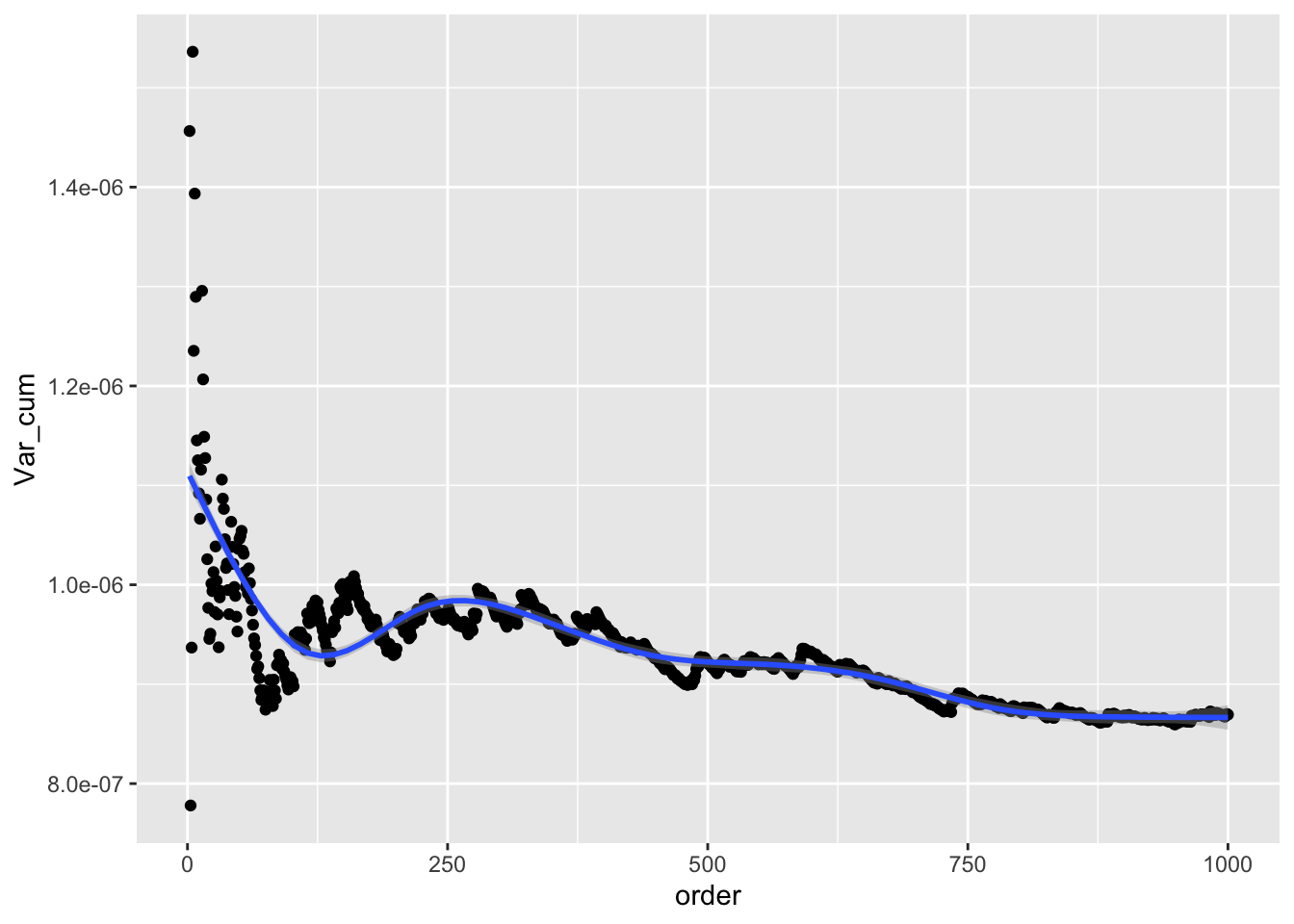
10.12 if_else()
La función if_else() es una función de reemplazo de valores en una columna basado en una condición
## # A tibble: 10 × 1
## day
## <int>
## 1 1
## 2 2
## 3 3
## 4 4
## 5 5
## 6 6
## 7 7
## 8 8
## 9 9
## 10 10## # A tibble: 10 × 2
## day day_p
## <int> <chr>
## 1 1 pre
## 2 2 pre
## 3 3 pre
## 4 4 normal
## 5 5 normal
## 6 6 normal
## 7 7 normal
## 8 8 normal
## 9 9 normal
## 10 10 normal## # A tibble: 13 × 1
## num_flowers
## <dbl>
## 1 0
## 2 0
## 3 0
## 4 0
## 5 1
## 6 2
## 7 0
## 8 1
## 9 2
## 10 0
## 11 2
## 12 100
## 13 1000## # A tibble: 13 × 2
## num_flowers flower_status
## <dbl> <chr>
## 1 0 not reproductive
## 2 0 not reproductive
## 3 0 not reproductive
## 4 0 not reproductive
## 5 1 reproductive
## 6 2 reproductive
## 7 0 not reproductive
## 8 1 reproductive
## 9 2 reproductive
## 10 0 not reproductive
## 11 2 reproductive
## 12 100 reproductive
## 13 1000 reproductiveplant_repr |>
mutate(flower_status = if_else(num_flowers %in% c(0), "not reproductive",
"reproductive"))## # A tibble: 13 × 2
## num_flowers flower_status
## <dbl> <chr>
## 1 0 not reproductive
## 2 0 not reproductive
## 3 0 not reproductive
## 4 0 not reproductive
## 5 1 reproductive
## 6 2 reproductive
## 7 0 not reproductive
## 8 1 reproductive
## 9 2 reproductive
## 10 0 not reproductive
## 11 2 reproductive
## 12 100 reproductive
## 13 1000 reproductiveplant_repr |>
mutate(flower_status =
if_else(num_flowers %in% c(0),
"not reproductive",
if_else(num_flowers %in% c(1:2), "reproductive",
"super reproductive")))## # A tibble: 13 × 2
## num_flowers flower_status
## <dbl> <chr>
## 1 0 not reproductive
## 2 0 not reproductive
## 3 0 not reproductive
## 4 0 not reproductive
## 5 1 reproductive
## 6 2 reproductive
## 7 0 not reproductive
## 8 1 reproductive
## 9 2 reproductive
## 10 0 not reproductive
## 11 2 reproductive
## 12 100 super reproductive
## 13 1000 super reproductive