Histogramas con geom_histogram
Fecha de la ultima revisión
## [1] "2026-04-15"

Histogramas con geom_histogram
Un histograma es una representación gráfica de datos agrupados en compartimentos o bins. Estos compartimentos incluyen individuos cuyos valores son similares o numéricamente cercanos. Una vez definidos los compartimentos, se suma la cantidad de observaciones que cae dentro de cada uno de ellos. El histograma es un tipo de gráfico muy común para visualizar la dispersión y la distribución de los datos.
Continuaremos con el ejemplo de Dipodium para demostrar la función geom_histogram a continuación.
En el primer caso de geom_histogram, la cantidad de observaciones (datos) se agrupa y se suma según la posición de los compartimentos o bins. En el segundo caso, para mostrar menos barras y observar mejor la agrupación en intervalos de tamaño 2, se utiliza geom_histogram(binwidth = 1). Como se puede apreciar, el número de compartimentos cambia al utilizar el parámetro binwidth, cuyo valor representa el ancho de cada compartimento (en este caso igual a 1). El número predeterminado de bins es 30. Cada barra representa la frecuencia de observaciones en cada categoría a un metro de distancia. En ambos casos se utilizó color = “white” (color blanco) para dibujar una línea alrededor de cada barra y así diferenciar mejor los grupos o bins. Nota que el programa retorna el mensaje:
\[\text{binwidth} = \frac{\text{max}(\text{data}) - \text{min}(\text{data})}{\text{bins}}\] Nota que el valor predeterminado de bins es 30, pero se puede modificar según sea necesario utilizando el parámetro binwidth.
Ahora haremos un ejercicio a mano para calcular el intervalo de los bins utilizando un conjunto de datos generado al azar, proveniente de una distribución normal con media 10 y desviación estándar 2.
set.seed(1234) ## usar la misma semilla para reproducibilidad
datos=rnorm(100, mean=10, sd=2)
datos # 100 datos de una distribución normal con media de 10 y desviación estándar de 2## [1] 7.585869 10.554858 12.168882 5.308605 10.858249 11.012112 8.850520
## [8] 8.906736 8.871096 8.219924 9.045615 8.003227 8.447492 10.128918
## [15] 11.918988 9.779429 8.977981 8.177609 8.325657 14.831670 10.268176
## [22] 9.018628 9.118904 10.919179 8.612560 7.103590 11.149511 7.952689
## [29] 9.969723 8.128103 12.204595 9.048814 8.581120 8.997484 6.741813
## [36] 7.664761 5.639921 7.318014 9.411412 9.068205 12.898993 7.862715
## [43] 8.289271 9.438754 8.011320 8.062971 7.785364 7.496028 8.952344
## [50] 9.006300 6.387937 8.835848 7.782221 7.970076 9.675381 11.126112
## [57] 13.295635 8.453293 13.211819 7.684383 11.313177 15.097982 9.930479
## [64] 8.660733 9.984790 13.554169 7.722785 12.735654 12.659130 10.672946
## [71] 10.013786 9.089063 9.266952 11.296573 14.140542 9.693203 7.218598
## [78] 8.552836 10.516524 9.365882 9.644420 9.660012 7.255396 9.652426
## [85] 11.700465 11.395217 11.099995 9.194536 9.616812 7.610944 9.893682
## [92] 10.510392 13.411928 12.003027 9.008833 10.711101 7.730784 11.756407
## [99] 11.945834 14.242234Cual es valor mínimo y máximo de los datos?
## [1] 5.308605## [1] 15.09798Usamos la formula anterior para calcular el intervalo de los bins. para tener 10 bins dividimos la diferencia entre el maximo y el mínimo por 10.
## [1] 0.9789378## [1] 5.308605Ahora calculamos los bins con la función cut para ver la frecuencia de los datos en cada bin.
Que quiere decir la parentesis y el corchete en los bins?
(a, b] significa que el bin no incluye el valor a, pero sí incluye el valor b.
[a, b] significa que el bin incluye tanto el valor a como el valor b.
(a, b) significa que el bin no incluye ni el valor a ni el valor b.
[a, b) significa que el bin incluye el valor a, pero no incluye el valor b.
bins=cut(datos, breaks=seq(min(datos), max(datos), binwidth), right=TRUE)
#bins # cada valor y en cual bin estará
levels(bins) # los niveles de los bins## [1] "(5.31,6.29]" "(6.29,7.27]" "(7.27,8.25]" "(8.25,9.22]" "(9.22,10.2]"
## [6] "(10.2,11.2]" "(11.2,12.2]" "(12.2,13.1]" "(13.1,14.1]" "(14.1,15.1]"## datos
## 1 7.585869
## 2 10.554858
## 3 12.168882
## 4 5.308605
## 5 10.858249
## 6 11.012112
## 7 8.850520
## 8 8.906736
## 9 8.871096
## 10 8.219924
## 11 9.045615
## 12 8.003227
## 13 8.447492
## 14 10.128918
## 15 11.918988
## 16 9.779429
## 17 8.977981
## 18 8.177609
## 19 8.325657
## 20 14.831670
## 21 10.268176
## 22 9.018628
## 23 9.118904
## 24 10.919179
## 25 8.612560
## 26 7.103590
## 27 11.149511
## 28 7.952689
## 29 9.969723
## 30 8.128103
## 31 12.204595
## 32 9.048814
## 33 8.581120
## 34 8.997484
## 35 6.741813
## 36 7.664761
## 37 5.639921
## 38 7.318014
## 39 9.411412
## 40 9.068205
## 41 12.898993
## 42 7.862715
## 43 8.289271
## 44 9.438754
## 45 8.011320
## 46 8.062971
## 47 7.785364
## 48 7.496028
## 49 8.952344
## 50 9.006300
## 51 6.387937
## 52 8.835848
## 53 7.782221
## 54 7.970076
## 55 9.675381
## 56 11.126112
## 57 13.295635
## 58 8.453293
## 59 13.211819
## 60 7.684383
## 61 11.313177
## 62 15.097982
## 63 9.930479
## 64 8.660733
## 65 9.984790
## 66 13.554169
## 67 7.722785
## 68 12.735654
## 69 12.659130
## 70 10.672946
## 71 10.013786
## 72 9.089063
## 73 9.266952
## 74 11.296573
## 75 14.140542
## 76 9.693203
## 77 7.218598
## 78 8.552836
## 79 10.516524
## 80 9.365882
## 81 9.644420
## 82 9.660012
## 83 7.255396
## 84 9.652426
## 85 11.700465
## 86 11.395217
## 87 11.099995
## 88 9.194536
## 89 9.616812
## 90 7.610944
## 91 9.893682
## 92 10.510392
## 93 13.411928
## 94 12.003027
## 95 9.008833
## 96 10.711101
## 97 7.730784
## 98 11.756407
## 99 11.945834
## 100 14.242234## [1] 0.9789378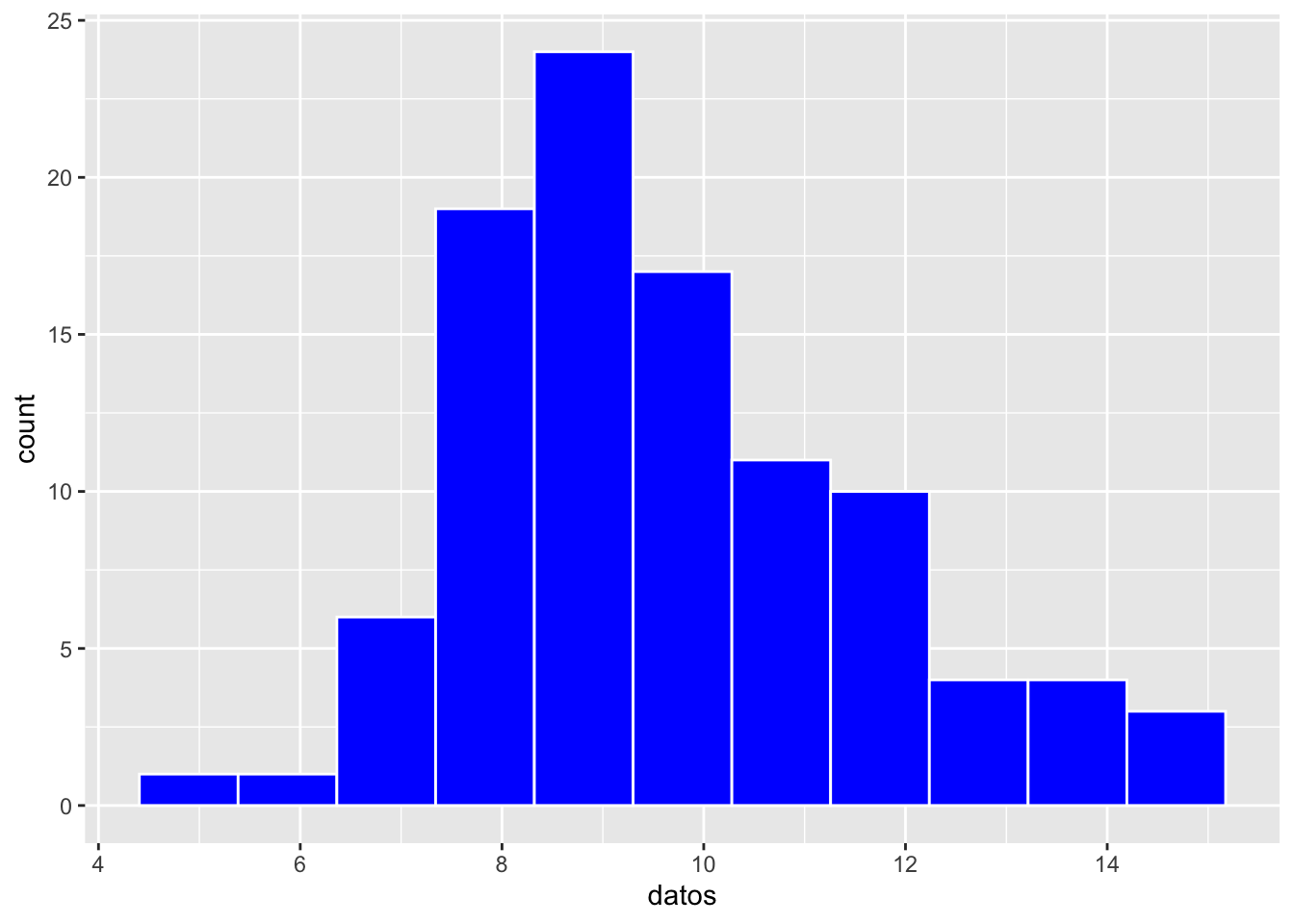
## `stat_bin()` using `bins = 30`. Pick better value `binwidth`.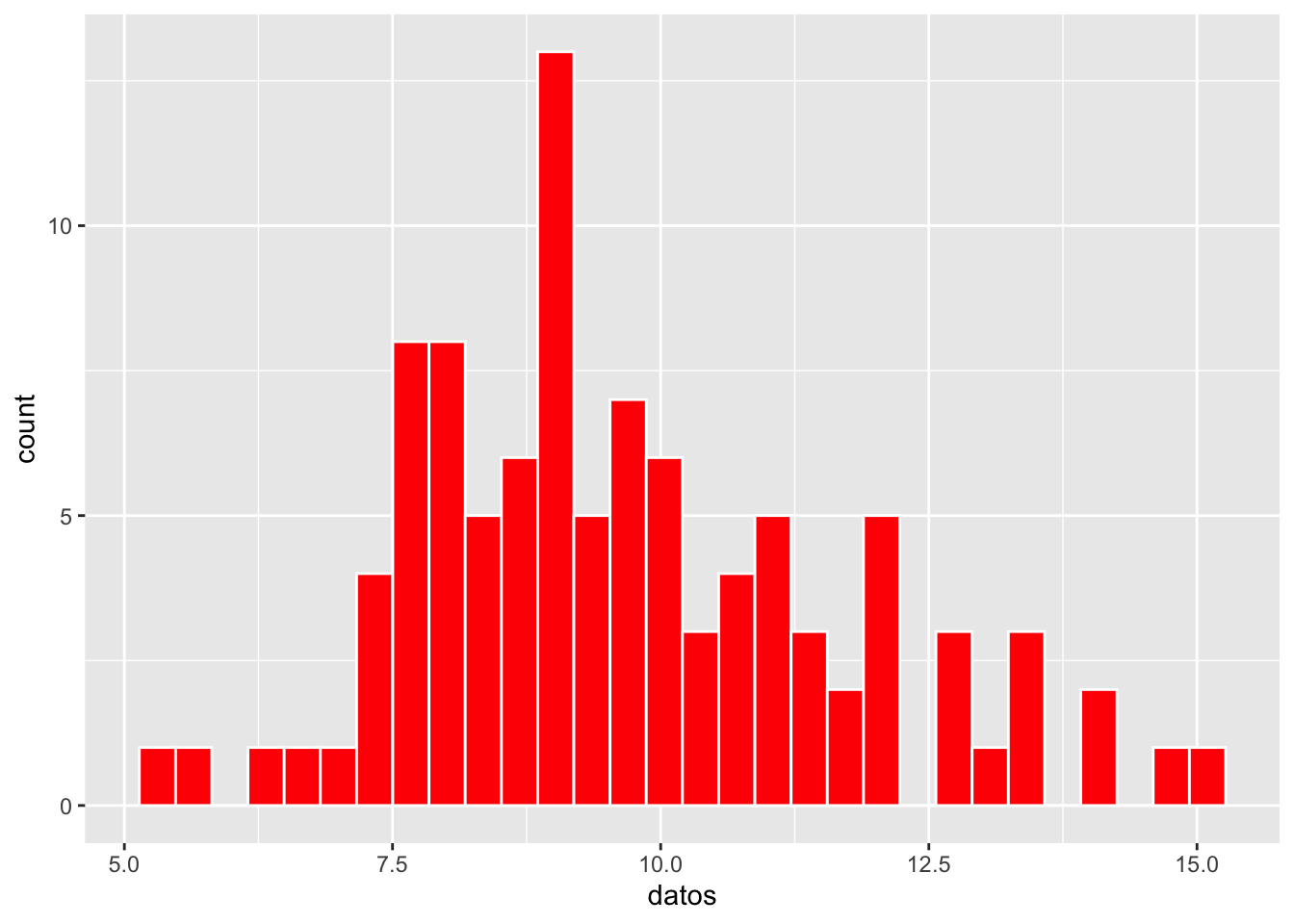
Histograma de la distancia de la orquidea focal al arbol más cercano
En el siguiente histograma se muestra la distancia de las orquídeas Dipodium roseum al árbol más cercano. Este histograma se generó utilizando la base de datos dipodium, disponible en el paquete ggversa. Se puede observar que la mayoría de las orquídeas se encuentran a menos de 5 metros de los árboles más cercanos. El histograma se construyó mediante la función geom_histogram, la cual permite visualizar la distribución de frecuencias de una variable continua.
La función geom_histogram contiene varios parámetros que se pueden modificar para ajustar la apariencia del gráfico. En este caso:
- Se cambió el color de las barras a azul.
- Se definió el color de la línea de borde como blanco para separar visualmente los bins.
- Se modificaron los nombres de los ejes para presentarlos en español.
Estos ajustes permiten mejorar la claridad del gráfico y facilitar su interpretación. Si deseas, también puedo corregir o mejorar la descripción del código que acompaña este texto.
library(janitor)
library(ggversa)
DW=clean_names(dipodium) # este archivo de datos se encuentra en el paquete "ggversa"
names(DW)## [1] "tree_number" "tree_species"
## [3] "dbh" "plant_number"
## [5] "ramet_number" "distance"
## [7] "orientation" "number_of_flowers"
## [9] "height_inflo" "herbivory"
## [11] "row_position_nf" "number_flowers_position"
## [13] "number_of_fruits" "perc_fr_set"
## [15] "pardalinum_or_roseum" "fruit_position_effect"
## [17] "frutos_si_o_no" "p_or_r_infl_lenght"
## [19] "num_of_fruits" "species_name"
## [21] "cardinal_orientation"| tree_number | tree_species | dbh | plant_number | ramet_number | distance | orientation | number_of_flowers | height_inflo | herbivory | row_position_nf | number_flowers_position | number_of_fruits | perc_fr_set | pardalinum_or_roseum | fruit_position_effect | frutos_si_o_no | p_or_r_infl_lenght | num_of_fruits | species_name | cardinal_orientation |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | E.o | 75 | 1 | 1 | 2.47 | 40 | 11 | 35 | n | 1 | 24 | 0 | 0.00 | r | 1 | 0 | r | 0 | r | 1 |
| 1 | E.o | 76 | 2 | 1 | 1.97 | 50 | 19 | 47 | n | 2 | 23 | 0 | 0.00 | r | 2 | 0 | r | 0 | r | 2 |
| 2 | E.o | 76 | 3 | 1 | 1.95 | 350 | 18 | 63 | n | 3 | 25 | 1 | 0.04 | r | 3 | 0 | r | 1 | r | 8 |
| 3 | E.o | 58 | 4 | 1 | 3.24 | 210 | 24 | 47 | n | 4 | 20 | 5 | 0.25 | r | 4 | 0 | r | 5 | r | 5 |
| 4 | E.o | NA | 5 | 1 | 0.85 | 80 | 25 | 61 | n | 5 | 13 | 0 | 0.00 | r | 5 | 0 | r | 0 | r | 2 |
| 5 | E.o | 59 | 6 | 1 | 2.62 | 160 | 17 | 35 | n | 6 | 25 | 2 | 0.08 | p | 6 | 0 | r | 2 | p | 4 |
a=ggplot(DW, aes(distance))
a+geom_histogram(color="white", fill="blue")+
labs(x="Distancia", y="Frecuencia")+
theme(axis.title=element_text(size=10,face="bold"))## `stat_bin()` using `bins = 30`. Pick better value `binwidth`.
Cambio del tamaño de los compartimiento con binwidth
Este histograma muestra las distancias entre las orquídeas Dipodium roseum y los árboles más cercanos. Esta especie es una orquídea mioheterótrofa obligada, dependiente de hongos micorrícicos para obtener carbono y otros nutrientes, ya que no realiza fotosíntesis.
La hipótesis ecológica subyacente es que las micorrizas —los hongos simbiontes— reciben nutrientes de las raíces de los árboles hospedadores, y esos nutrientes son posteriormente transferidos a las orquídeas a través de las redes micorrícicas. En consecuencia, si esta relación es fuerte, se esperaría observar una distancia óptima entre las orquídeas y los árboles proveedores de recursos. Una distribución muy alejada de los árboles podría indicar menor probabilidad de establecer la relación micorrícica, mientras que distancias demasiado cercanas podrían no ser ecológicamente viables por competencia u otros factores.
En el segundo gráfico, se modificó el parámetro binwidth a 1, lo cual representa un intervalo de 1 metro. Con este ajuste:
- El primer bin abarca aproximadamente desde –0.5 hasta 0.5 metros.
- El segundo bin representa el intervalo >0.5 a 1.5 metros.
- Los intervalos continúan de manera equivalente (por ejemplo, 1.5–2.5 m, 2.5–3.5 m, etc.).
Estos cambios permiten visualizar con mayor claridad la agrupación de distancias en unidades ecológicamente significativas, facilitando la interpretación de cómo se distribuyen las orquídeas en relación con sus posibles árboles hospedadores.
## [1] 1365a=ggplot(DW, aes(distance))
a+geom_histogram(binwidth=.3,color="white", fill="blue")+
labs(x="Distancia (m)", y="Frecuencia")+
theme(axis.title=element_text(size=10,face="bold"))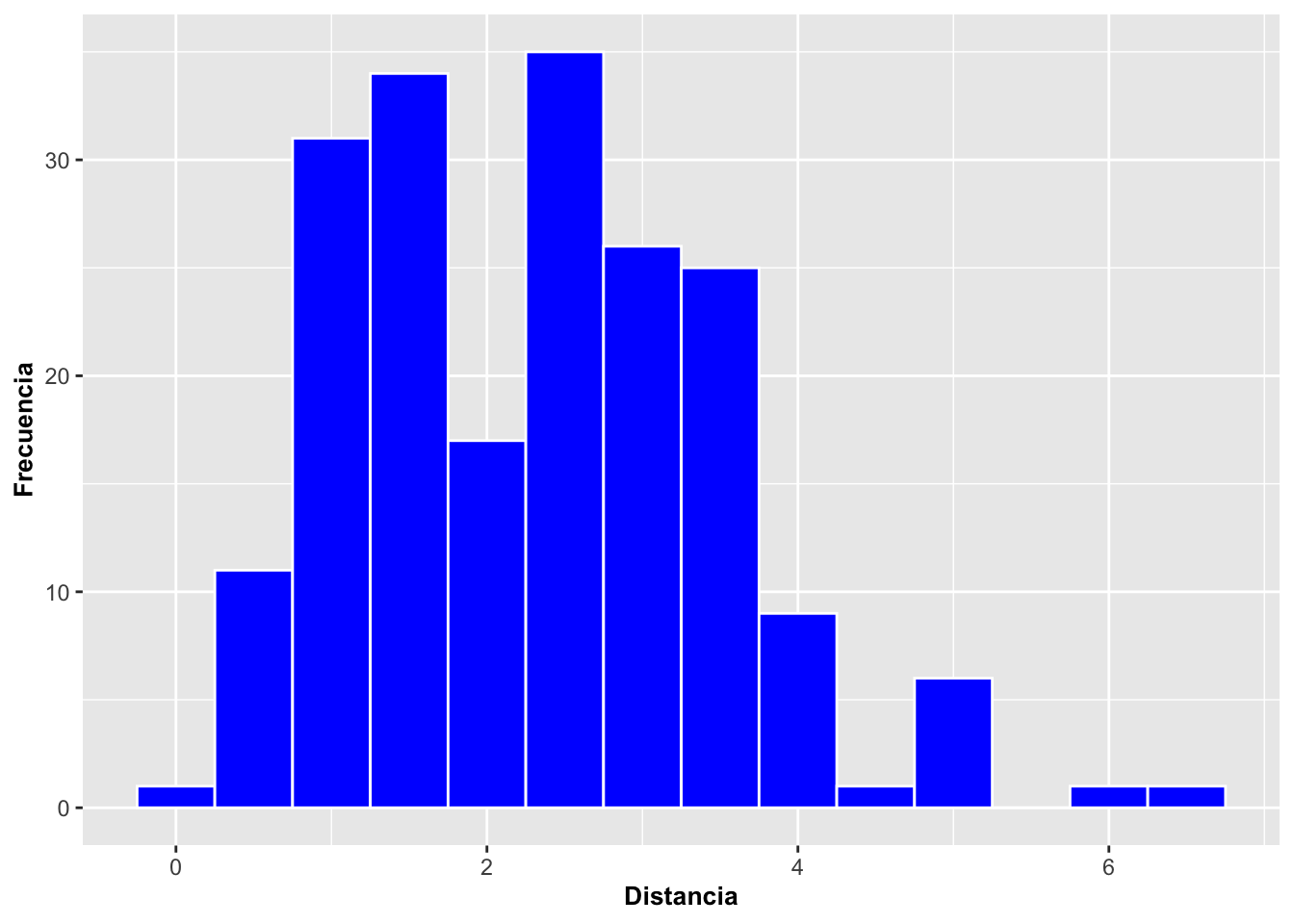
Números de camas en hospitales por 1000 habitantes en diferenctes paises
En el siguiente gráfico, vemos la frecuencia de número de camas de hospital por cada 1000 habitantes para 67 países utilizando la base de datos Camas_Hospital. Se hizo con la información que estaba disponible solo para los años 1996 y 2006. Tenemos dos gráficos solapados para visualizar si la distribución ha cambiado de entre el año 1996 y 2006. Note que las frecuencias del 2006 aparecen sobre las del 1996.
| Pais | Year | Poblacion | Camas |
|---|---|---|---|
| Armenia | 1996 | 3173425 | 7.13 |
| Australia | 1996 | 18311000 | 8.50 |
| Austria | 1996 | 7959017 | 9.30 |
| Azerbaijan | 1996 | 7763000 | 9.81 |
| Bahamas, The | 1996 | 283792 | 3.94 |
| Barbados | 1996 | 265940 | 7.56 |
## 'data.frame': 134 obs. of 4 variables:
## $ Pais : Factor w/ 67 levels "Armenia","Australia",..: 1 2 3 4 5 6 7 8 9 10 ...
## $ Year : int 1996 1996 1996 1996 1996 1996 1996 1996 1996 1996 ...
## $ Poblacion: int 3173425 18311000 7959017 7763000 283792 265940 10160000 213674 7717445 8362826 ...
## $ Camas : num 7.13 8.5 9.3 9.81 3.94 ...## [1] 1996 2006ggplot(Camas_Hospital, aes(Camas, fill=factor(Year)))+
geom_histogram(stat="bin", alpha=.5, colour="white")+
xlab("Número de camas por cada 1000 habitantes")+
ylab("Frecuencia")## `stat_bin()` using `bins = 30`. Pick better value `binwidth`.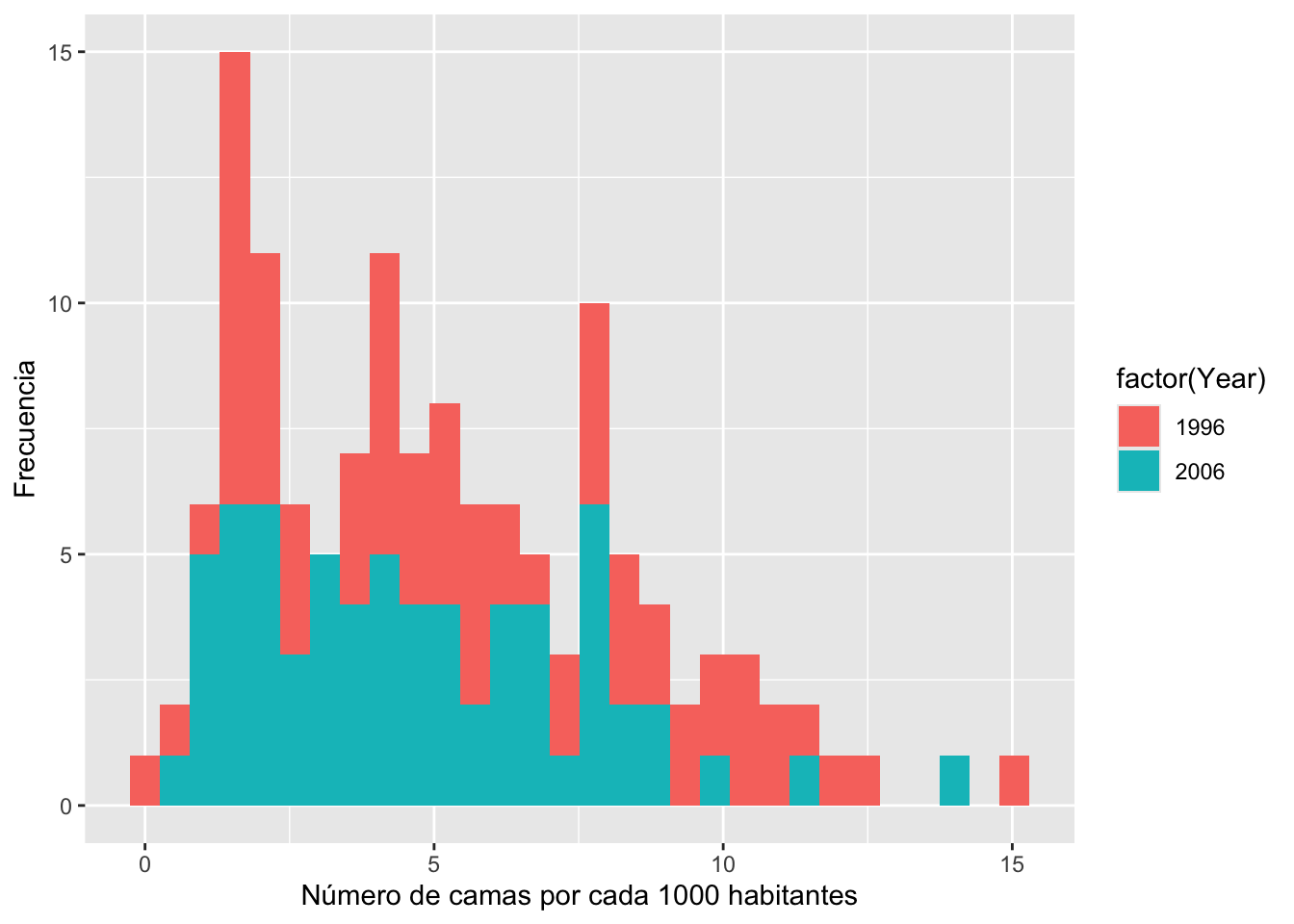
Modificando las escalas continuas con scale_y_continuous y scale_x_continuous
Se demuestra también cómo modificar la escala, primero con un método poco práctico numerando en el eje de Y cada valor donde queremos una línea. Note que se excluye el número 10 y por eso no aparece en el eje de Y la función es scale_y_continuous(breaks=c(x,x,x…x). En el eje de X se numera también pero esta vez se define la escala con scale_x_continuous(breaks=c( ), y c(x:xx) con un valor inicial de 1 y final de 15 para identificar cual son los valores que uno quiere en los ejes; eso es más práctico e incluye al valor 10. También se modifica la información de los ejes usando xlab y ylab, de manera tal que la descripción de la columnas se pueda presentar de forma específica y así hacer la información más clara para propósitos del gráfico. =
a=ggplot(Camas_Hospital, aes(Camas, fill=factor(Year)))+
geom_histogram(stat="bin", alpha=0.3)+
scale_y_continuous(breaks=c(0,1,4,5,6,7,8,9,11,12,13,14,15))+
scale_x_continuous(breaks=c(0:15))+
theme(axis.title=element_text(size=10,face="bold"))
a## `stat_bin()` using `bins = 30`. Pick better value `binwidth`.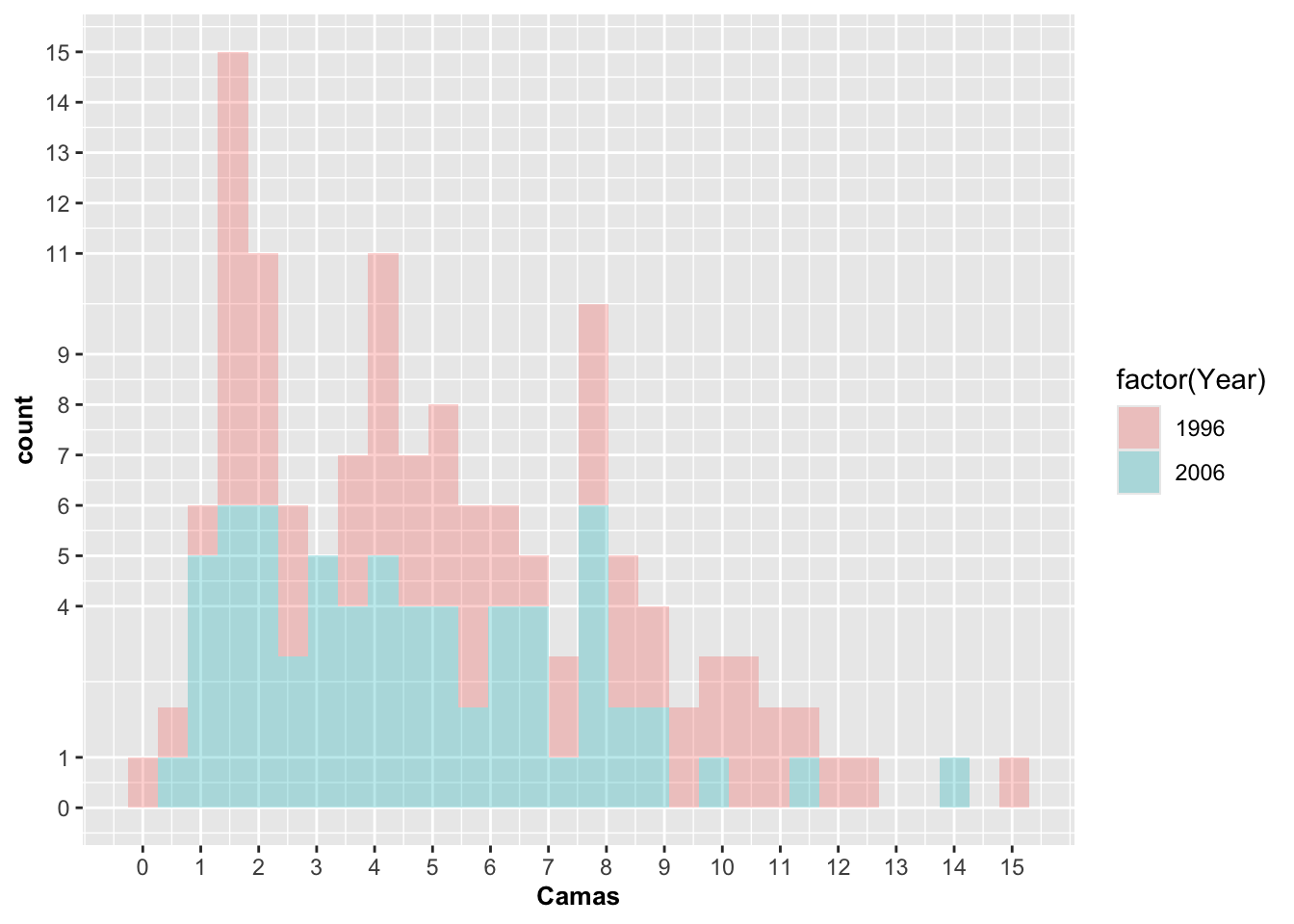
Solapamiento de frecuencia y intensidad de color
Podríamos pensar que, debido a que las frecuencias están solapadas, es difícil tener una buena apreciación de la distribución de los datos. Para comparar las frecuencias entre los grupos con más facilidad, se pueden diferenciar las frecuencias con 3 colores; en este caso el color azul para el año 2006, el color durazno para el año 1996, y el color grisáceo para las frecuencias que se solapan con ambos años. Se usa position=identity y alpha= pata modicar la intensidades de color de la barras. Ahora vemos que, por ejemplo, en el año 1996 la frecuencia más común en los países era de menos de 2 camas por 1,000 habitantes, y que ya para el año 2006 ya era de 2 y 8 camas por cada 1,000 habitantes.
a=ggplot(Camas_Hospital, aes(Camas, fill=factor(Year)))
a+geom_histogram(stat="bin", alpha=0.5,
position="identity")+
xlab("Número de camas por \n 1000 habitantes")+
ylab("Frecuencia")+
scale_y_continuous(breaks=c(0:9))+
scale_x_continuous(breaks=c(0:15))+
theme(axis.title=element_text(size=10,face="bold"))## `stat_bin()` using `bins = 30`. Pick better value `binwidth`.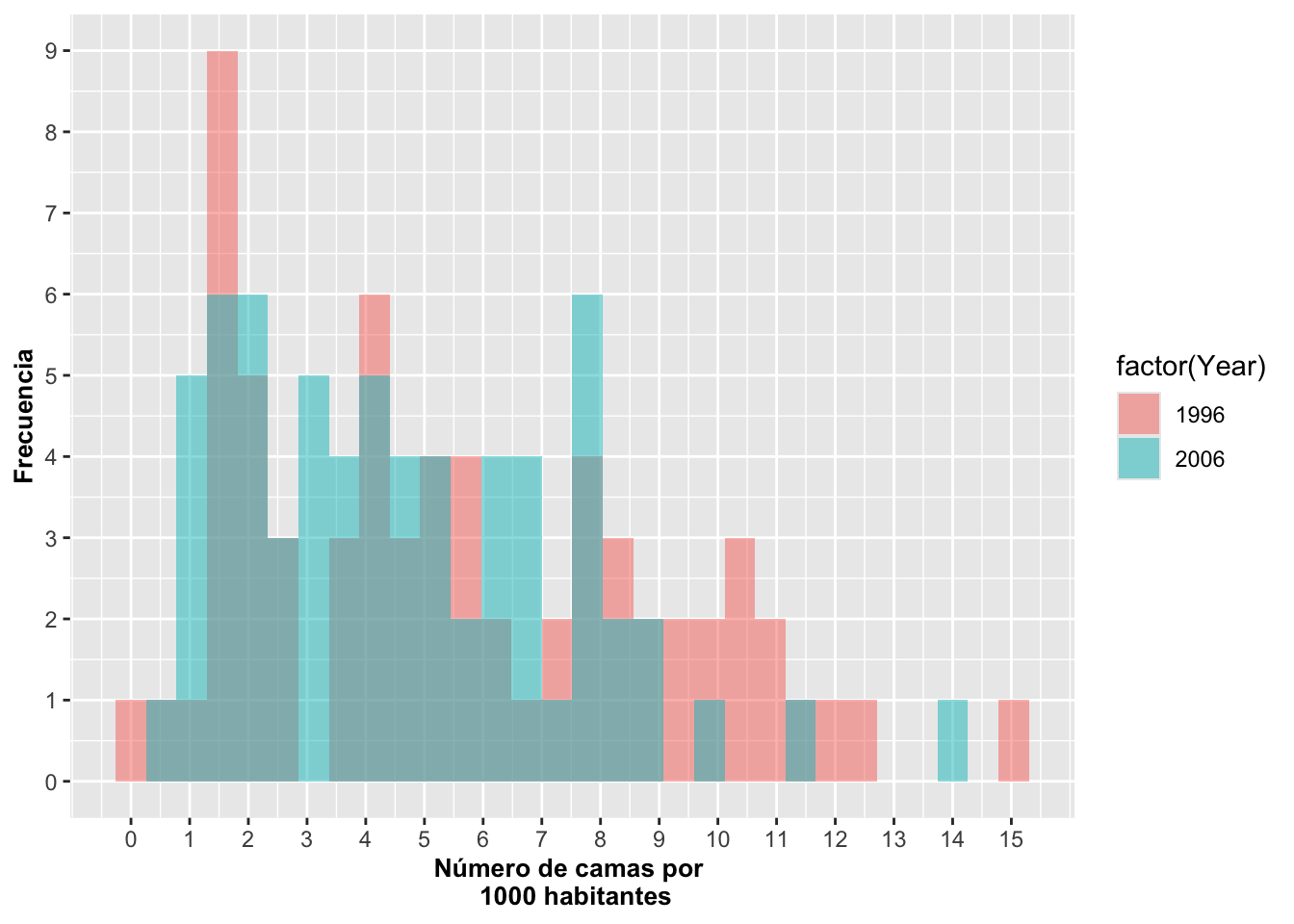
Posicionar las barras uno al lado del otro con la función dodge
Para posicionar las barras unos al lado de los otros, se usa la función dodge. En este caso, se usó position=“dodge” para posicionar las barras uno al lado del otro. Se puede ver que la frecuencia de camas por 1,000 habitantes en los países ha aumentado en el año 2006 comparado con el año 1996. Se puede ver que en el año 2006 hay más países con más de 5 camas por 1,000 habitantes que en el año 1996. Se puede ver que en el año 1996 la frecuencia más común en los países era de menos de 2 camas por 1,000 habitantes, y que ya para el año
a=ggplot(Camas_Hospital, aes(Camas, fill=factor(Year)))
a+geom_histogram(color="black", bins=15, alpha=0.9,
position="dodge")+
xlab("Número de camas por \n 1000 habitantes")+
ylab("Frecuencia")+
scale_y_continuous(breaks=c(0:12))+
scale_x_continuous(breaks=c(0:15))+
theme(axis.title=element_text(size=10,face="bold"))+
theme_minimal()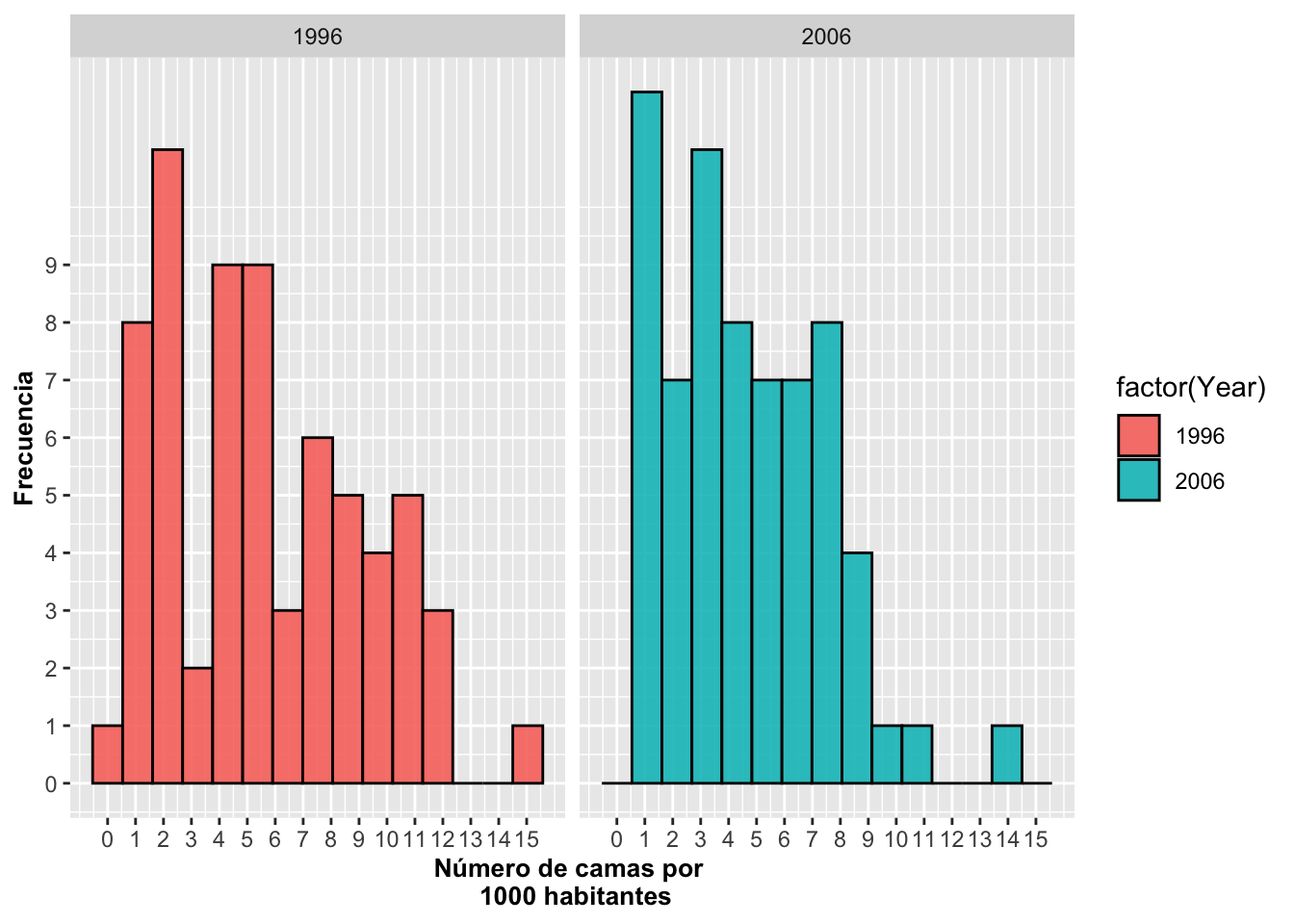
Gráficos para grupo con Facet_wrap
Cambio de colores del gráfico manualmente
Otra alternativa es usar dos gráficos para cada año; o sea, uno por cada grupo. En tal caso usaremos la opción facet_wrap. facet_wrap se explican con más detalle más adelante. Podemos cambiar el color de las barras usando scale_fill_manual; en nuestro caso, cyan4 para el 1996 y darkorange para el 2006. Además, note que con scale_color_manual podemos cambiar la línea alrededor de las barras; en nuestro caso la cambiamos a negro o black.
ggplot(Camas_Hospital, aes(Camas, fill=factor(Year),
color=factor(Year)))+
geom_histogram(stat="bin", alpha=0.5)+
xlab("Número de camas \n por cada 1000 habitantes")+
ylab("Frecuencia")+
scale_fill_manual(values=c("cyan4", "red"))+
scale_color_manual(values=c("yellow", "black"))+
theme(axis.title=element_text(family="mono",size=10,face="italic", colour="#4ea7ad"))+
facet_wrap(~Year)+
scale_y_continuous(breaks=c(0:9))+
scale_x_continuous(breaks=c(1:15))+
theme(axis.title.x=element_text(angle=180))+ # NOTE the x legend text
theme(axis.text.x=element_text(size=8, angle=45))+
theme(axis.title.y = element_text(angle=270))## `stat_bin()` using `bins = 30`. Pick better value `binwidth`.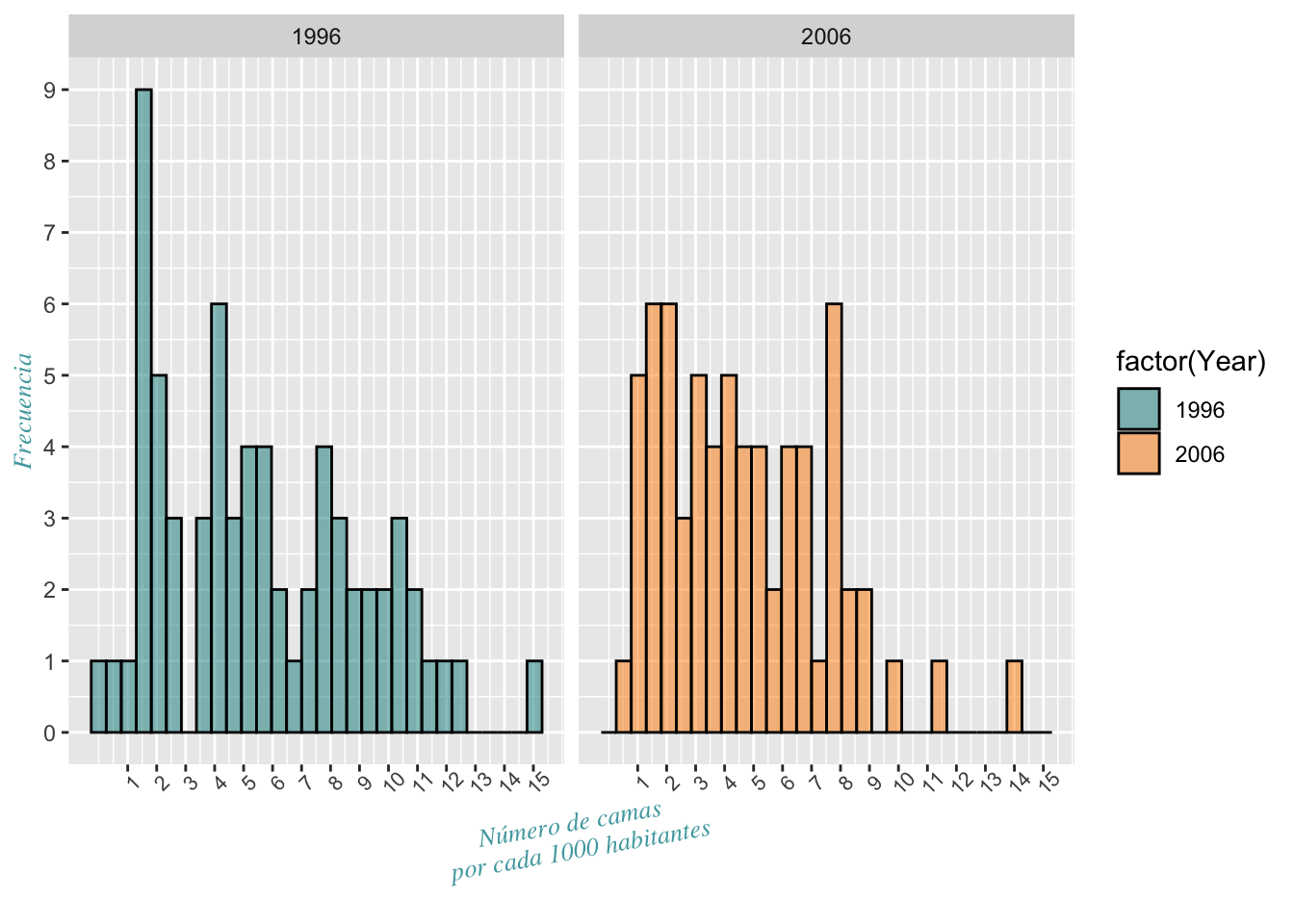
Opciones y Parametros de geom_histogram:
ggplot(el archivo de datos, aes(la variable continua))
- geom_histogram (), binwidth, x, y, alpha, color, fill, stat, position.
- binwidth: el ancho de los compartimentos donde por defecto es de 1/30 el rango de los datos.
- alpha: la intensidad del color
- fill: el color del área; ej., color=blue
- color: el color de la línea alrededor del área; ej., color=white
- position: “identity”, “stack”, “dodge”.
| carat | cut | color | clarity | depth | table | price | x | y | z |
|---|---|---|---|---|---|---|---|---|---|
| 0.23 | Ideal | E | SI2 | 61.5 | 55 | 326 | 3.95 | 3.98 | 2.43 |
| 0.21 | Premium | E | SI1 | 59.8 | 61 | 326 | 3.89 | 3.84 | 2.31 |
| 0.23 | Good | E | VS1 | 56.9 | 65 | 327 | 4.05 | 4.07 | 2.31 |
| 0.29 | Premium | I | VS2 | 62.4 | 58 | 334 | 4.20 | 4.23 | 2.63 |
| 0.31 | Good | J | SI2 | 63.3 | 58 | 335 | 4.34 | 4.35 | 2.75 |
| 0.24 | Very Good | J | VVS2 | 62.8 | 57 | 336 | 3.94 | 3.96 | 2.48 |
- Usando el archivo de datos de diamonds en el paquete ggplot2, haga un histograma del precio de los diamantes, en diferentes chunks.
- cambia el color de las barras
- pon una linea blanca alrededor de las barras
- separa los diamantes de diferentes color en histograma diferentes
- evalúa como se ve los gráficos con las diferentes arreglos: position: “identity”, “stack”, “dodge”
- cambia la intensidad del color
- cambia los nombres de los ejes al español
- salvar los gráficos en formato .png, o .tiff o .jpeg y subir por lo menos uno de estos a MSTeam.