Código
library(popdemo)
library(popbio)
library(ggplot2)
library(dplyr)
library(scales)
library(Rage)
source("R/figuras_helpers.R") # plc_save(), grviz_save(), save_plot_png()Por: Mariana Hernández-Apolinar y Paola Portillo Tzompa
Las propiedades de una matriz de proyección poblacional determinan cómo se comporta una población a largo plazo bajo condiciones constantes. Este capítulo introduce las principales propiedades matemáticas y biológicas de las matrices poblacionales y explica por qué son centrales para interpretar la dinámica poblacional más allá del valor de \(\lambda\).
Las matrices de proyección poblacional poseen un conjunto de propiedades matemáticas que gobiernan la dinámica demográfica de las poblaciones a largo plazo. Entre estas propiedades se encuentran la estructura estable por estadios, el valor propio dominante (\(\lambda\)), el vector reproductivo y la convergencia asintótica de la población hacia un patrón dinámico estable.
En este capítulo se examinan estas propiedades desde una perspectiva biológica, mostrando cómo emergen de la estructura del ciclo de vida y de las tasas vitales que describen supervivencia, crecimiento y fecundidad. Se explica cómo la estructura estable de la población representa la distribución proporcional de individuos entre estadios cuando la población ha alcanzado su dinámica asintótica, y por qué esta estructura es clave para interpretar proyecciones poblacionales y comparaciones entre escenarios.
Además, se introduce el concepto de valor reproductivo como una medida de la contribución relativa de cada estadio al crecimiento futuro de la población. Este capítulo se diferencia de los anteriores porque no se centra en el cálculo de \(\lambda\) ni en su sensibilidad a cambios paramétricos, sino en la comprensión de las propiedades estructurales que explican por qué las poblaciones exhiben determinados patrones de crecimiento, estabilidad o declive. Estas propiedades constituyen la base conceptual para análisis posteriores de elasticidad, LTRE y simulaciones poblacionales.
A continuación se ilustran las propiedades matemáticas de las matrices de proyección poblacional y su cálculo mediante herramientas computacionales.
library(popdemo)
library(popbio)
library(ggplot2)
library(dplyr)
library(scales)
library(Rage)
source("R/figuras_helpers.R") # plc_save(), grviz_save(), save_plot_png()En este capítulo aprenderemos sobre algunos índices que se usan con frecuencia en el análisis matricial. Estos índices nos ayudan a saber si una matriz es “buena” para trabajar y si los resultados que obtenemos son confiables.
El capítulo está dividido en dos partes:
Aquí veremos características básicas que debe cumplir una matriz para que el análisis sea válido:
Estos se basan en modelos de proyección poblacional (MPP) y nos permiten entender cómo cambia la población antes y después de un disturbio:
Si quieres profundizar en estos índices, te recomiendo consultar (Caswell 2001) y (Stott et al. 2011).
El primer paso en el análisis matricial es construir una matriz de transición poblacional, la cual resume en una tabla la supervivencia, la reproducción y las transiciones de los individuos en diferentes etapas o categorías de edad. Cada fila y columna de la matriz representa un estadio del ciclo de vida de la especie, y cada elemento dentro de la matriz describe la transición de un estadio a otro en un intervalo de tiempo determinado (por ejemplo, de un año a otro).
Una matriz de proyección poblacional (MPP) es una matriz cuadrada que permite describir y predecir la dinámica de una población a través del tiempo. En esta se organizan las probabilidades de transición entre categorías de tamaño o estado (plántulas, juveniles, adultos, etc.) junto con la fecundidad o reproducción de los individuos.
La MPP se utiliza para proyectar la estructura de una población en el futuro, a partir de su composición actual. Así, constituye la base para calcular tasas de crecimiento poblacional, estructuras estables, valores reproductivos y otros índices demográficos fundamentales.
A continuación se construye la matriz poblacional de Lepanthes rubripetala. Esta matriz se compone de cuatro estados: plántulas (PL), juveniles (J), adultos no reproductivos (NR) y adultos reproductivos (AR).
# Capturar los datos de la matriz para L. rubripetala (Tremblay et al. 2015)
Lr1 <- matrix(c(
0.4324, 0, 0, 0.146,
0.3784, 0.8459, 0, 0,
0, 0.0034, 0.7954, 0.2300,
0, 0.0890, 0.1841, 0.7510
), byrow = TRUE, ncol = 4)
# Capturar las categorías de estado
estadios <- c("PL", "J", "NR", "AR")
colnames(Lr1) <- rownames(Lr1) <- estadios
# Obtener la matriz L. rubripetala
Lr1 <- matrix(Lr1[1:4, ], nrow = 4, dimnames = list(estadios, estadios))
Lr1 PL J NR AR
PL 0.4324 0.0000 0.0000 0.146
J 0.3784 0.8459 0.0000 0.000
NR 0.0000 0.0034 0.7954 0.230
AR 0.0000 0.0890 0.1841 0.751Las matrices poblacionales deben tener dimensiones cuadradas, es decir, deben tener el mismo número de filas que de columnas. Esta característica es importante porque cada columna y fila representa una categoría de edad o un estado del ciclo de vida de la especie. Las columnas representan la categoría de los individuos al inicio del estudio, mientras que las filas representan su tránsito a otra categoría después de un periodo de tiempo. Si la matriz no es cuadrada, no hay correspondencia que permita comparar el número de individuos por categoría al inicio y al final de un periodo de estudio, por lo que será imposible estimar la tasa de crecimiento poblacional. En el caso de L. rubripetala, la matriz poblacional tiene 4 filas y 4 columnas, por lo que cumple con la propiedad de dimensión cuadrada. Esto puede verificarse fácilmente en R usando la función dim().
dim(Lr1)[1] 4 4Decimos que la propiedad de ergodicidad se cumple cuando el crecimiento asintótico predicho por la matriz es independiente de la estructura poblacional inicial considerada en el estudio. En otras palabras, sin importar el estado inicial de la población, su comportamiento converge a una estructura estable y a una tasa de crecimiento constante a largo plazo. Si una matriz poblacional no es ergódica, el crecimiento poblacional depende de la estructura poblacional inicial, lo que implica que el promedio o la tasa de crecimiento poblacional no son buenos predictores del comportamiento poblacional a largo plazo (Mangalam y Kelty-Stephen 2022). Para comprobar si la matriz es ergódica puede emplearse la función isErgodic() del paquete popbio en R. Esta función da como resultado el valor lógico TRUE si la matriz es ergódica y FALSE en el caso contrario. En L. rubripetala se espera que la matriz sea ergódica, ya que los autores reportaron que la población alcanza tanto una estructura estable como una tasa de crecimiento constante en el tiempo (Tremblay et al. 2015).
isErgodic(Lr1, digits = 5, return.eigvec = FALSE)[1] TRUEUna matriz no cumple la condición de ergodicidad cuando, por ejemplo, ningún individuo logra pasar del estado de plántula al juvenil ni al adulto. En este caso, la población queda «atascada» en las primeras etapas y no puede alcanzar una estructura estable. Si evaluamos esta matriz con la función isErgodic() del paquete popbio en R, el resultado será FALSE. Esto indica que:
# Capturar los datos de la matriz para L. rubripetala (Tremblay et al. 2015)
Lr1_No_erg <- matrix(c(
0.4324, 0., 0., 0.146,
0., 0.8459, 0., 0.,
0., 0.0034, 0.7954, 0.2300,
0., 0.0890, 0.1841, 0.7510
), byrow = TRUE, ncol = 4)
plc_save(Lr1_No_erg, stages = estadios, fontsize = 8, png = "images/Indice5_Lr1_No_erg.png")isErgodic(Lr1_No_erg, digits = 4, return.eigvec = FALSE)[1] FALSEUna matriz poblacional debe ser no negativa, lo que significa que todas sus entradas son mayores o iguales a cero. ¿Por qué? Porque cada valor representa el número o la proporción de individuos que pasan de una etapa a otra. Tener valores negativos no tendría sentido biológico: no puede haber «menos» individuos que los existentes.
Además, si la matriz tuviera elementos negativos:
En el caso de L. rubripetala, la matriz cumple esta condición, ya que todos sus valores son mayores o iguales a cero. En R, esto se puede verificar con la función IsPositive(), que devuelve:
TRUE si la matriz es no negativa.FALSE si contiene algún valor negativo.# No negativa
IsPositive <- function(mat) {
if (all(mat >= 0)) {
return(TRUE)
} else {
return(FALSE)
}
}
IsPositive(Lr1)[1] TRUEA continuación se muestra un ejemplo de una matriz que no cumple la propiedad de no negatividad. En este caso, el elemento ubicado en la posición (4, 3) es negativo, lo que indica que la transición desde la categoría adulto reproductivo hacia adulto no reproductivo tiene un valor inválido.
Al evaluar esta matriz con la función IsPositive() en R, el resultado es FALSE. Esto significa que:
# Capturar los datos de la matriz para L. rubripetala (Tremblay et al. 2015)
Lr1_No_pos <- matrix(c(
0.4324, 0, 0, 0.146,
0.3784, 0.8459, 0, 0,
0, 0.0034, 0.7954, -0.2300,
0, 0.0890, 0.1841, 0.7510
), byrow = TRUE, ncol = 4)
IsPositive(Lr1_No_pos)[1] FALSEUna matriz de transición poblacional debe ser irreducible, lo que significa que todas sus categorías están conectadas y existe al menos una ruta que permite llegar desde cualquier estado a los demás. Esta propiedad es esencial porque, si la matriz no es irreducible, la población no podrá alcanzar una estructura estable ni una tasa de crecimiento constante a largo plazo.
En el caso de L. rubripetala, la matriz es irreducible: todas las etapas del ciclo de vida están conectadas y existe una ruta entre ellas. Para comprobar esta propiedad en R, se utiliza la función isIrreducible() del paquete popdemo, que devuelve:
TRUE si la matriz es irreducible.FALSE si no lo es.Es importante destacar que no todas las matrices reducibles son inválidas. En algunos casos, pueden aceptarse, por ejemplo, en especies con etapas que no influyen en el crecimiento poblacional, como las fases postreproductivas en mamíferos (humanos, ballenas, etc.).
En resumen, para L. rubripetala, la función isIrreducible() devuelve TRUE, lo que confirma que todas las categorías están conectadas y que la población puede alcanzar una estructura estable y una tasa de crecimiento constante a largo plazo.
isIrreducible(Lr1)[1] TRUEA continuación se muestra un ejemplo de matriz en la que el cuarto estadio no presenta valores de reproducción. Al evaluar esta matriz con la función isIrreducible() en R, el resultado es FALSE.
¿Por qué ocurre esto? Porque no existe un vínculo entre la categoría plántula y la categoría adulto reproductivo, lo que significa que la presencia de plántulas en la población no contribuye a la reproducción.
Esta ausencia de conexión provoca dos problemas:
Lr1_Irr <- matrix(c(
0.4324, 0., 0.0, 0,
0.3784, 0.8459, 0, 0,
0., 0.0034, 0.7954, 0.2300,
0, 0.0890, 0.1841, 0.7510
), byrow = TRUE, ncol = 4)
plc_save(Lr1_Irr, stages = estadios, fontsize = 8, png = "images/Indice_Lr1_Irr.png")isIrreducible(Lr1_Irr)[1] FALSEUna matriz de transición poblacional debe ser primitiva, lo que significa que, al elevarla a potencias altas, se obtiene un único valor positivo dominante (la tasa de crecimiento poblacional). Esta propiedad es clave porque asegura que la población alcanzará una estructura estable y una tasa de crecimiento constante a largo plazo.
En el caso de L. rubripetala, la matriz es primitiva: al elevarla a potencias altas, aparece un único valor positivo. En R, esto se puede comprobar con la función isPrimitive() del paquete popdemo, que devuelve:
TRUE si la matriz es primitiva.FALSE si no lo es.isPrimitive(Lr1)[1] TRUEUna matriz no primitiva tendría una dinámica inestable a largo plazo, como ocurre en poblaciones con comportamiento cíclico, donde las proporciones entre categorías oscilan sin llegar a estabilizarse.
Irreducible vs primitiva: la sutileza.
Por eso popdemo ofrece tanto isIrreducible() como isPrimitive(): los modelos poblacionales bien comportados deben pasar ambos chequeos.
Verifica estos cinco supuestos antes de calcular \(\lambda\), sensibilidades o elasticidades. Si la matriz falla alguno, los análisis posteriores pueden ser inválidos o difíciles de interpretar:
| Propiedad | Función en R | Por qué importa |
|---|---|---|
| Cuadrada | dim() |
Origen y destino deben ser comparables. |
| No negativa | IsPositive() |
No tiene sentido biológico tener entradas negativas. |
| Irreducible | popdemo::isIrreducible() |
Asegura que todas las etapas estén conectadas. |
| Primitiva | popdemo::isPrimitive() |
Asegura una tasa de crecimiento única (no oscilaciones). |
| Ergódica | popbio::isErgodic() |
Asegura que la dinámica asintótica no dependa del estado inicial. |
Cuando alguna falla, conviene revisar el ciclo de vida y las matrices originales (ver el capítulo de Ciclos de Vida) antes de pasar a análisis avanzados.
En esta sección se revisan los índices poblacionales obtenidos a partir del análisis matricial, los cuales se estiman una vez que se ha verificado que la matriz cumple con los supuestos. Estos índices permiten comprender el comportamiento de la población a largo plazo y anticipar cómo se espera que se comporte en el tiempo. Los índices que se abordan a continuación son: estructura estable, valor reproductivo, análisis de convergencia y análisis de amortiguamiento. Todos estos se calculan a partir de la matriz de transición poblacional y del vector de la estructura poblacional observada al inicio del estudio.
La estructura poblacional estable (\(W\), también conocida como eigenvector derecho) indica la proporción esperada de individuos en cada categoría de edad o estado cuando la población ha alcanzado el equilibrio a largo plazo. Por ejemplo, en L. rubripetala se espera que la estructura estable sea:
Este índice supone que la tasa de crecimiento poblacional (\(\lambda\)) se mantiene constante en el tiempo, lo cual solo ocurre bajo condiciones ambientales estables. Sin embargo, en la naturaleza esto es poco común. Además, la estructura estable asume que el periodo de muestreo y las condiciones abióticas y bióticas son típicas y no cambian.
En la revisión de Williams et al. (2011), se reportó que más del 80% de las poblaciones analizadas no cumplían con la condición de estructura estable, especialmente en especies con matrices grandes (n × n) y tiempos generacionales prolongados. De manera similar, Tremblay observó que la mayoría de las orquídeas estudiadas no estaban en estructura estable al inicio del muestreo poblacional.
La estructura estable rara vez se observa en la naturaleza. Williams et al. (2011) reportan que más del 80% de las poblaciones analizadas no estaban en estructura estable, especialmente en especies longevas con matrices grandes. Esto significa que las proyecciones basadas en \(\lambda\) describen el comportamiento que tendría la población si las condiciones se mantuvieran constantes —no necesariamente lo que observaremos en el corto plazo. Para poblaciones lejos del equilibrio, conviene complementar \(\lambda\) con análisis de dinámica transitoria (ver capítulo de Dinámica de transiciones).
# Estructura estable de estados
stable.stage(Lr1) PL J NR AR
0.08614082 0.20286284 0.37222782 0.33876852 Uno puede visualizar la estructura poblacional usando el código siguiente.
Wmax <- stable.stage(Lr1)
Wdf <- data.frame(Wmax)
Wdf$Categorias <- c(
"Plántulas",
"Juveniles",
"Adultos no reproductivos",
"Adultos reproductivos"
)
Wdf$Categorias <- factor(
Wdf$Categorias,
levels = c(
"Plántulas",
"Juveniles",
"Adultos no reproductivos",
"Adultos reproductivos"
)
)
library(ggplot2)
ggplot(Wdf, aes(y = Wmax, x = Categorias)) +
geom_bar(stat = "identity", aes(fill = "blue")) +
labs(
title = "Estructura estable de estados esperada",
x = "Etapas",
y = "Proporción"
) +
rlt_style_fill() +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
theme(legend.position = "null")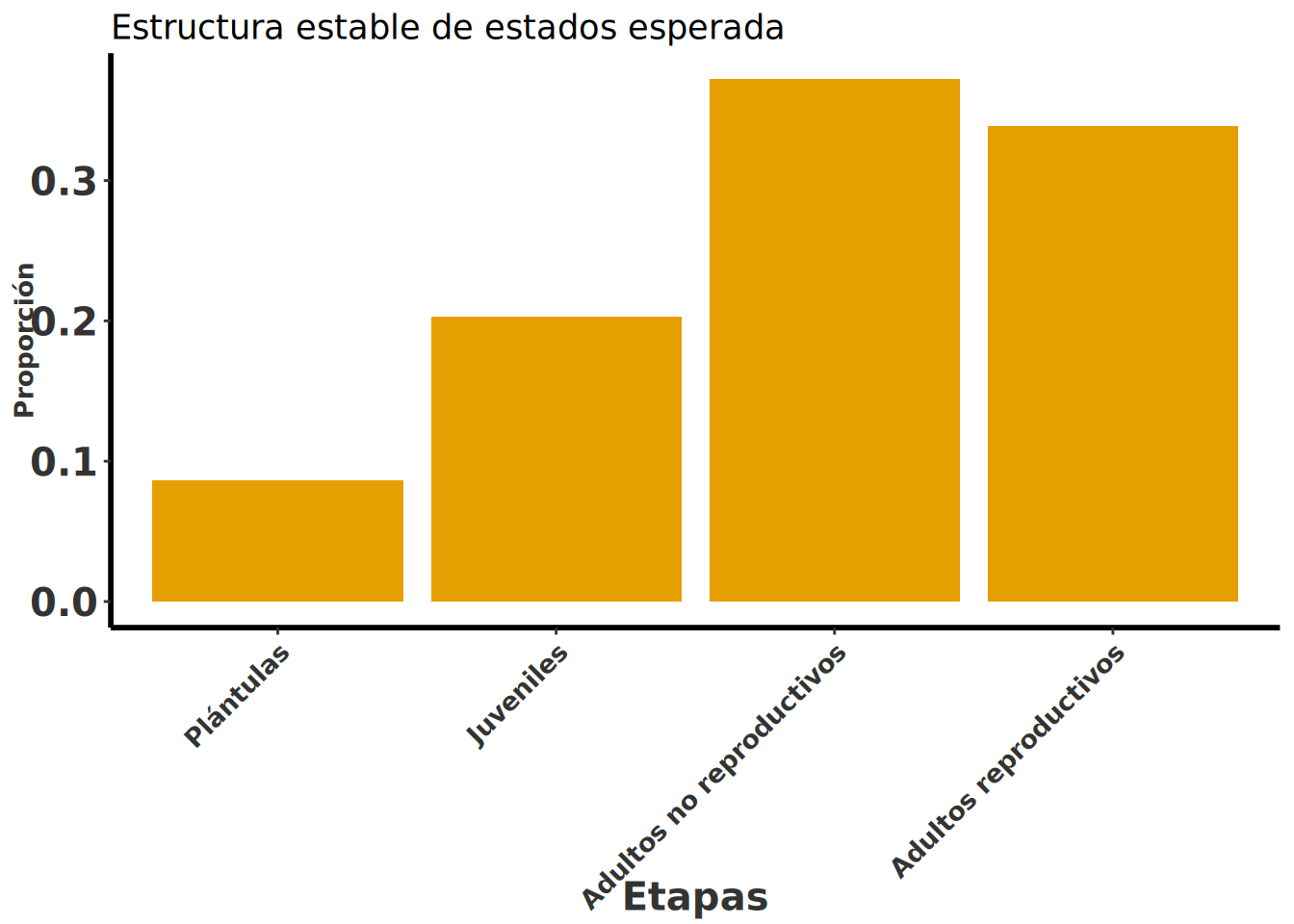

El valor reproductivo (\(v\), también llamado eigenvector izquierdo) indica la contribución esperada de cada categoría de edad o estado a la reproducción de la población.
En el caso de L. rubripetala, los valores reproductivos esperados son:
Este índice es muy útil porque muestra qué etapas son más importantes para el crecimiento poblacional a largo plazo. La primera categoría siempre tiene un valor de 1.00, ya que representa el inicio del ciclo de vida y sirve como referencia para calcular los demás valores.
Además, el valor reproductivo ayuda a definir estrategias de manejo. Por ejemplo:
En Spathoglottis plicata, una orquídea terrestre invasora, las acciones de control deberían enfocarse en las categorías con mayor valor reproductivo, porque son las que más contribuyen al crecimiento poblacional.
Por el contrario, si se busca remover individuos con el menor impacto posible, conviene actuar sobre las etapas con valores reproductivos bajos.
# Valor reproductivo
reproductive.value(Lr1) PL J NR AR
1.000000 1.517385 2.311211 2.651157 El análisis de convergencia mide el tiempo esperado para que una población alcance su estructura estable y un crecimiento asintótico después de un disturbio. Es decir, indica qué tan rápido la población regresa a su estructura estable tras una perturbación (Stott et al. 2011). Este comportamiento se cuantifica mediante el índice de amortiguamiento (damping ratio), que evalúa la influencia del valor propio subdominante, \(\lambda_2\), durante el periodo de convergencia.
El índice se expresa a través del cociente entre el valor propio dominante, \(\lambda_1\), y el valor absoluto del subdominante:
\[\rho=\frac{\lambda_1}{\left|\lambda_2\right|}\]
donde \(\rho\) representa el índice de amortiguamiento, \(\lambda_1\) corresponde al valor propio dominante de la matriz de transición poblacional y \(\lambda_2\) al módulo del segundo valor propio más grande. Este índice no tiene unidades y es independiente de la estructura inicial de la población.
En el caso de L. rubripetala, al calcular los valores propios de la matriz con la función eigen(), se obtiene un valor dominante de \(\lambda_1 = 1.00658\) y un valor subdominante de \(\lambda_2 = 0.8322\). De esta manera, el índice de amortiguamiento es:
\[\rho = \frac{\lambda_1}{|\lambda_2|} = \frac{1.00658}{|0.83220|} \approx 1.21\]
El valor obtenido indica que la población converge hacia su estructura estable tras un disturbio, aunque lentamente.
Es importante señalar que la interpretación de este índice depende de la escala temporal con que se construyó la matriz. Si bien la mayoría de los estudios poblacionales utilizan datos anuales (Crone et al. 2011), también existen estudios con periodos de muestreo mensuales, bimensuales, estacionales o bianuales, los cuales se establecen de acuerdo con el ciclo de vida de la especie estudiada.
eigen(Lr1)$values # la lista de valores propios de la matriz Lr1[1] 1.0065785+0.00000000i 0.8322016+0.00000000i 0.4929600+0.06290472i
[4] 0.4929600-0.06290472iDR <- eigen(Lr1)$values[1] / abs(eigen(Lr1)$values[2])
DR[1] 1.209537+0idr(Lr1) # usando la función "dr" para "damping ratio" en el paquete "popdemo"[1] 1.209537El comportamiento del índice de amortiguamiento se puede visualizar mediante una gráfica de líneas, que muestra cómo responde un sistema ante un cambio súbito (un «paso de entrada») y cómo varía esa respuesta en el tiempo según diferentes niveles de amortiguamiento.
Para facilitar la comprensión, en el siguiente bloque se incluye el código que genera una gráfica ilustrando el comportamiento de una población perturbada:
library(ggplot2)
# --- Definir los parametros ---
# Población inicial en el tiempo t=0. Ese el punto de equilibrio inicial.
poblacion_inicial <- 1000
# Factores de amortiguamiento para graficar.
# 0,3 = Subamortiguado (oscila)
# 1,0 = Críticamente amortiguado (retorno más rápido sin oscilación)
# 2,0 = Sobreamortiguado (retorno lento sin oscilación)
amortiguamiento <- c(0.3, 1.0, 2.0, 3.0)
# Frecuencia de la oscilación (omega_n).
frecuencia <- 0.5
# Tiempo total para la simulación
tiempo_total <- 50
# Paso de tiempo para la simulación (más pequeño para una curva más suave)
etapa_tiempo <- 0.1
# --- Generar los datos de oscilación amortiguada para múltiples coeficientes ---
# Crear un data frame vacío para almacenar todos los datos
todo_data_df <- data.frame()
# Recorra cada relación de amortiguamiento para generar los datos
for (zeta in amortiguamiento) {
# Crear una secuencia de puntos de tiempo
time_points <- seq(0, tiempo_total, by = etapa_tiempo)
# Calcular la población en cada punto de tiempo según el coeficiente de amortiguamiento.
# La forma matemática de la respuesta al escalón cambia según el coeficiente de amortiguamiento.
if (zeta < 1) {
# Caso subamortiguado: onda sinusoidal amortiguada
omega_d <- frecuencia * sqrt(1 - zeta^2)
population_data <- poblacion_inicial *
(1 -
exp(-zeta * frecuencia * time_points) *
(cos(omega_d * time_points) +
(zeta / sqrt(1 - zeta^2)) * sin(omega_d * time_points)))
} else if (zeta == 1) {
# Caso amortiguado críticamente
population_data <- poblacion_inicial *
(1 - exp(-frecuencia * time_points) * (1 + frecuencia * time_points))
} else {
# Caso sobreamortiguado
s1 <- -zeta * frecuencia + frecuencia * sqrt(zeta^2 - 1)
s2 <- -zeta * frecuencia - frecuencia * sqrt(zeta^2 - 1)
population_data <- poblacion_inicial *
(1 -
(s2 * exp(s1 * time_points) - s1 * exp(s2 * time_points)) / (s2 - s1))
}
# Añadir los datos del coeficiente actual a un data frame temporal
temp_df <- data.frame(
Time = time_points,
Population = population_data,
DampingRatio = factor(zeta) # guardar el coeficiente de amortiguamiento como factor para el color
)
# Unir el data frame temporal al data frame principal
todo_data_df <- rbind(todo_data_df, temp_df)
}
# --- Crear el gráfico usando ggplot2 ---
ggplot(todo_data_df, aes(x = Time, y = Population, color = DampingRatio)) +
# Añadir las líneas para cada coeficiente de amortiguamiento
geom_line(linewidth = 1.2) +
# Establecer el título y las etiquetas
labs(
title = "El efecto de amortiguamiento \n sobre el tamaño de población",
subtitle = "La población se estabiliza a un equilibrio de 1000",
x = "Tiempo",
y = "Tamaño poblacional",
color = expression("Amortiguamiento (" * zeta * ")")
) +
# Personalizar el tema del gráfico para mejor estética
rlt_style_colour() +
theme_minimal(base_size = 14) +
theme(
plot.title = element_text(hjust = 0.5, face = "bold"),
plot.subtitle = element_text(hjust = 0.5),
axis.title = element_text(face = "bold")
)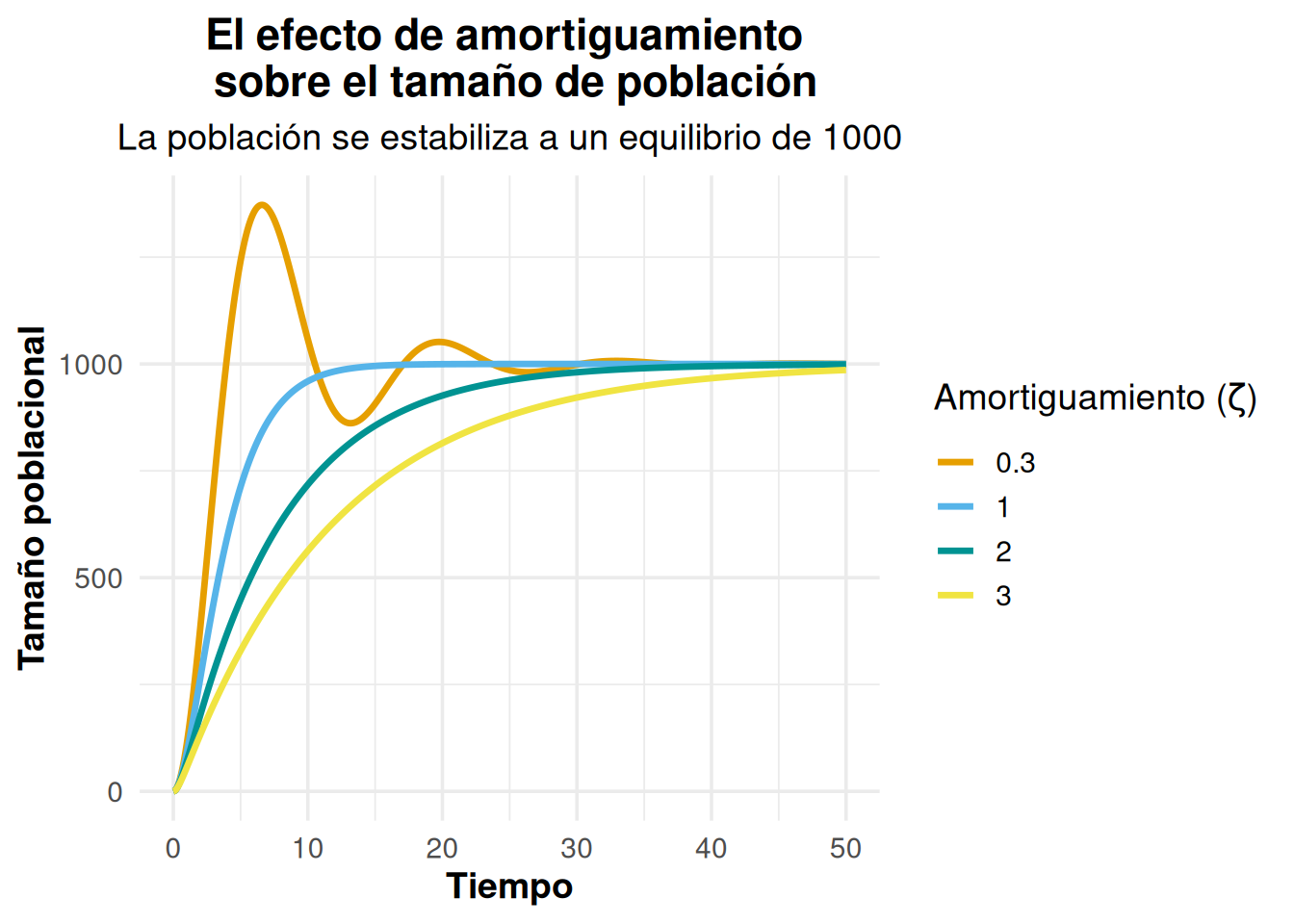
La figura resultante ilustra el efecto de diferentes coeficientes de amortiguamiento en la respuesta de una población a un cambio súbito. El gráfico muestra cuatro comportamientos distintos para la población perturbada y su retorno a un estado de equilibrio, correspondiente a un tamaño poblacional de 1000 individuos.
La respuesta de la población ante cuatro índices de amortiguamiento es la siguiente:
Cuatro regímenes de amortiguamiento.
| ζ | Régimen | Comportamiento |
|---|---|---|
| \(< 1\) | Subamortiguado | Sobrepasa el equilibrio y oscila; la amplitud decrece con el tiempo. |
| \(= 1\) | Críticamente amortiguado | Retorno más rápido posible sin oscilaciones. |
| \(> 1\) (moderado) | Sobreamortiguado | Retorno lento sin oscilaciones; la fuerza de amortiguamiento es alta. |
| \(\gg 1\) | Muy sobreamortiguado | Retorno extremadamente lento; el sistema apenas reacciona. |
En poblaciones reales, la mayoría de las matrices de proyección se encuentran en el régimen sobreamortiguado: regresan al equilibrio sin oscilar, pero pueden tardar muchas generaciones.
El tiempo de convergencia es un indicador de la dinámica poblacional, ya que estima el tiempo que tarda una población en alcanzar su estructura estable. Este índice es relevante porque facilita entender el comportamiento poblacional a largo plazo. En R este cálculo puede realizarse con dos funciones del paquete popdemo: dr() y convt(). La función dr() calcula el amortiguamiento, y a partir de este puede estimarse el tiempo de convergencia de la siguiente manera:
\[t = \frac{\log(x)}{\log(\rho)}\]
donde
Mientras mayor sea \(\rho\), más rápida será la convergencia: una matriz con \(\rho = 2\) converge mucho más rápido que una con \(\rho = 1.05\). El análisis de amortiguamiento estima la rapidez con la que una población converge a su estructura estable después de un disturbio (Jiang et al. 2020). Cabe señalar que se ha demostrado que existe una relación entre el índice de amortiguamiento y el tiempo generacional de una especie (Jiang et al. 2020).
dr(Lr1, return.time = TRUE, x = 10) # cuanto tiempo toma aumentar la población de veces$dr
[1] 1.209537
$t
[1] 12.10374A partir de la función convt() del paquete popdemo se puede estimar el tiempo esperado en que una población alcanza su estructura estable, considerando la estructura poblacional observada al inicio del estudio. Esta función simula el modelo y determina manualmente cuándo la población converge, dado un nivel de exactitud específico (accuracy). Entre más estricta sea la exactitud, mayor será el tiempo de convergencia. Para utilizar esta función es necesario indicar la estructura inicial, es decir, el número de individuos en cada estadio. En el caso de L. rubripetala se espera que el tiempo de convergencia sea de 18 ciclos (meses) para alcanzar su estructura estable.
Por ejemplo, si se comienza con una población inicial de 8, 20, 27 y 34 individuos en las categorías de plántulas, juveniles, adultos no reproductivos y adultos reproductivos, respectivamente, la población alcanzaría en 6 meses, aproximadamente, la estructura estable. En contraste, si la población inicial estuviera sesgada (compuesta únicamente por plántulas, por ejemplo), el tiempo de convergencia sería mucho mayor. Este enfoque resulta muy útil al definir estrategias de conservación; por ejemplo, al establecer una nueva población con una distribución inicial determinada.
La estructura inicial determina cuánto tarda la convergencia. Para la misma matriz de L. rubripetala:
Esto tiene implicaciones prácticas en conservación: si introduces una nueva población o una población en restauración, la composición inicial determina cuándo el modelo asintótico empieza a aplicar. Para acelerar la convergencia, conviene introducir individuos en proporciones cercanas a la estructura estable cuando sea factible.
n0 <- c(8, 20, 27, 34) # la estructura de la población inicial
convt(Lr1, accuracy = 1e-4, vector = n0, iterations = 10000) # la estructura poblacional inicial[1] 19Dado que el tiempo de convergencia es un índice que representa el periodo esperado para que una población alcance su estructura estable, se puede calcular variando la cantidad de individuos en las diferentes edades o estados al llevar a cabo una simulación.
Por ejemplo, se estima que L. rubripetala alcanzaría la estructura estable en 25 meses, si la población inicia con una población sesgada a plántulas (n = 1000) y, por lo tanto, sin la presencia de individuos de los estados posteriores.
La población comienza en cada etapa con 100 individuos y se simula durante 22 pasos de tiempo. El gráfico resultante muestra cómo la población converge a su estructura estable a lo largo del tiempo, con cada etapa representada por una línea de color diferente. La línea horizontal indica el valor de la proporción de la etapa estable y la línea vertical representa el tiempo en que se espera que la etapa llegue a su nivel de estructura estable.
Nota que si las condiciones se mantienen iguales en el tiempo, se espera que la población converja a una estructura estable, es decir, que la proporción de individuos en cada etapa se mantenga constante a lo largo del tiempo. En este caso, la proporción de individuos en cada etapa converge a 0.088, 0.206, 0.369 y 0.337 para las categorías de plántulas, juveniles, adultos no reproductivos y adultos reproductivos, respectivamente, en 3, 17, 15 y 9 periodos (el tiempo de re-muestreo corresponde a la construcción de la matriz).
# Este script utiliza un enfoque de matriz para modelar las dinámicas de una
# población de 4 etapas (por ejemplo, clases de edad o estadios de vida).
# Demuestra cómo una distribución de población converge a un estado estable.
# Instalar y cargar el paquete ggplot2 para el trazado
# install.packages("ggplot2")
library(ggplot2)
# --- Definir Parámetros de Simulación ---
# Población inicial en el tiempo t=0 para cada etapa.
# Una distribución inicial uniforme es un buen punto de partida para observar la convergencia.
initial_population <- c(100, 100, 100, 100)
# Número total de pasos de tiempo para la simulación
total_time_steps <- 22
# --- Definir la matriz de transición de la población (matriz de Leslie) ---
# Se utiliza la matriz proporcionada por el usuario.
transition_matrix <- matrix(
c(
0.4324, 0, 0, 0.146,
0.3784, 0.8459, 0, 0,
0, 0.0034, 0.7954, 0.2300,
0, 0.0890, 0.1841, 0.7510
),
nrow = 4,
byrow = TRUE
)
# --- Simular la Dinámica de la Población y Calcular Proporciones ---
# Nombres de las etapas en el orden de la matriz (PL, J, NR, AR)
stage_names <- c(
"plántula",
"juvenil",
"adulto no reproductivo",
"adulto reproductivo"
)
# Crear un data frame para almacenar los resultados de la simulación
all_data_df <- data.frame(
Time = integer(),
Proportion = numeric(),
Stage = character()
)
# Vector de población actual (distribución inicial)
n_current <- initial_population
# Bucle para simular cada paso de tiempo
for (t in 0:total_time_steps) {
# Calcular la proporción de la población en cada etapa
current_proportions <- n_current / sum(n_current)
# Crear un data frame temporal para este paso de tiempo
temp_df <- data.frame(
Time = rep(t, 4),
Proportion = current_proportions,
Stage = factor(stage_names, levels = stage_names) # Se usa factor para ordenar las etapas
)
# Añadir los datos al data frame principal
all_data_df <- rbind(all_data_df, temp_df)
# Proyectar la población al siguiente paso de tiempo
# Multiplicación de la matriz de transición por el vector de población
n_next <- transition_matrix %*% n_current
n_current <- n_next
}
# --- Calcular la Distribución de Etapa Estable (SSD) ---
# Se calcula el vector propio derecho (eigenvector) del valor propio dominante.
# Este vector representa la proporción de individuos en cada etapa en el estado estable.
eigen_results <- eigen(transition_matrix)
# Encontrar el valor propio dominante (más grande)
dominant_eigenvalue <- max(Re(eigen_results$values))
# Encontrar el vector propio derecho correspondiente (eigenvector)
stable_stage_distribution_raw <- Re(eigen_results$vectors[, which.max(Re(
eigen_results$values
))])
# Normalizar el vector propio para que sume 1
stable_stage_distribution <- stable_stage_distribution_raw /
sum(stable_stage_distribution_raw)
stable_stage_distribution_df <- data.frame(
Stage = factor(stage_names, levels = stage_names),
Proportion = stable_stage_distribution
)
# --- Calcular el Tiempo de Convergencia para cada Etapa ---
# Definir una tolerancia para la convergencia (por ejemplo, 1% de la proporción de SSD)
tolerance <- 0.01
# Crear un data frame para almacenar los tiempos de convergencia
convergence_times_df <- data.frame(
Stage = character(),
Time = numeric()
)
# Bucle por cada etapa para encontrar el primer paso de tiempo donde
# la proporción está dentro de la tolerancia de la DEE
for (i in 1:length(stage_names)) {
stage_name <- stage_names[i]
ssd_proportion <- stable_stage_distribution_df[
stable_stage_distribution_df$Stage == stage_name,
"Proportion"
]
# Filtrar los datos para la etapa actual
stage_data <- all_data_df[all_data_df$Stage == stage_name, ]
# Encontrar la primera fila donde la proporción está dentro de la banda de tolerancia
convergence_time <- stage_data$Time[which(
abs(stage_data$Proportion - ssd_proportion) <= tolerance
)[1]]
if (!is.na(convergence_time)) {
convergence_times_df <- rbind(
convergence_times_df,
data.frame(
Stage = stage_name,
Time = convergence_time
)
)
}
}
# La función `factor` es necesaria para garantizar que los nombres de las etapas
# en `convergence_times_df` se muestren en el orden correcto.
convergence_times_df$Stage <- factor(convergence_times_df$Stage, levels = stage_names)
subexpr <- bquote("El crecimiento anual de la población es " * lambda == .(round(dominant_eigenvalue, 4)))
# --- Crear el Trazado Usando ggplot2 ---
population_plot <- ggplot(
all_data_df,
aes(x = Time, y = Proportion, color = Stage)
) +
geom_line(linewidth = 1.2) +
# Añadir líneas horizontales para la distribución de etapa estable
geom_hline(
data = stable_stage_distribution_df,
aes(yintercept = Proportion, color = Stage),
linetype = "dashed",
linewidth = 0.8
) +
# Añadir líneas verticales para el tiempo de convergencia
geom_vline(
data = convergence_times_df,
aes(xintercept = Time, color = Stage),
linetype = "dotted",
linewidth = 1.0
) +
labs(
title = "Convergencia a la distribución estable ",
subtitle = subexpr,
x = "Paso de Tiempo",
y = "Proporción de la Población",
color = "Etapa de Vida"
) +
rlt_style_colour() +
theme_minimal(base_size = 12) +
theme(
plot.title = element_text(hjust = 0.5, face = "bold"),
plot.subtitle = element_text(hjust = 0.5),
axis.title = element_text(face = "bold")
) +
xlim(0, max(all_data_df$Time))
# Imprimir el gráfico final
print(population_plot)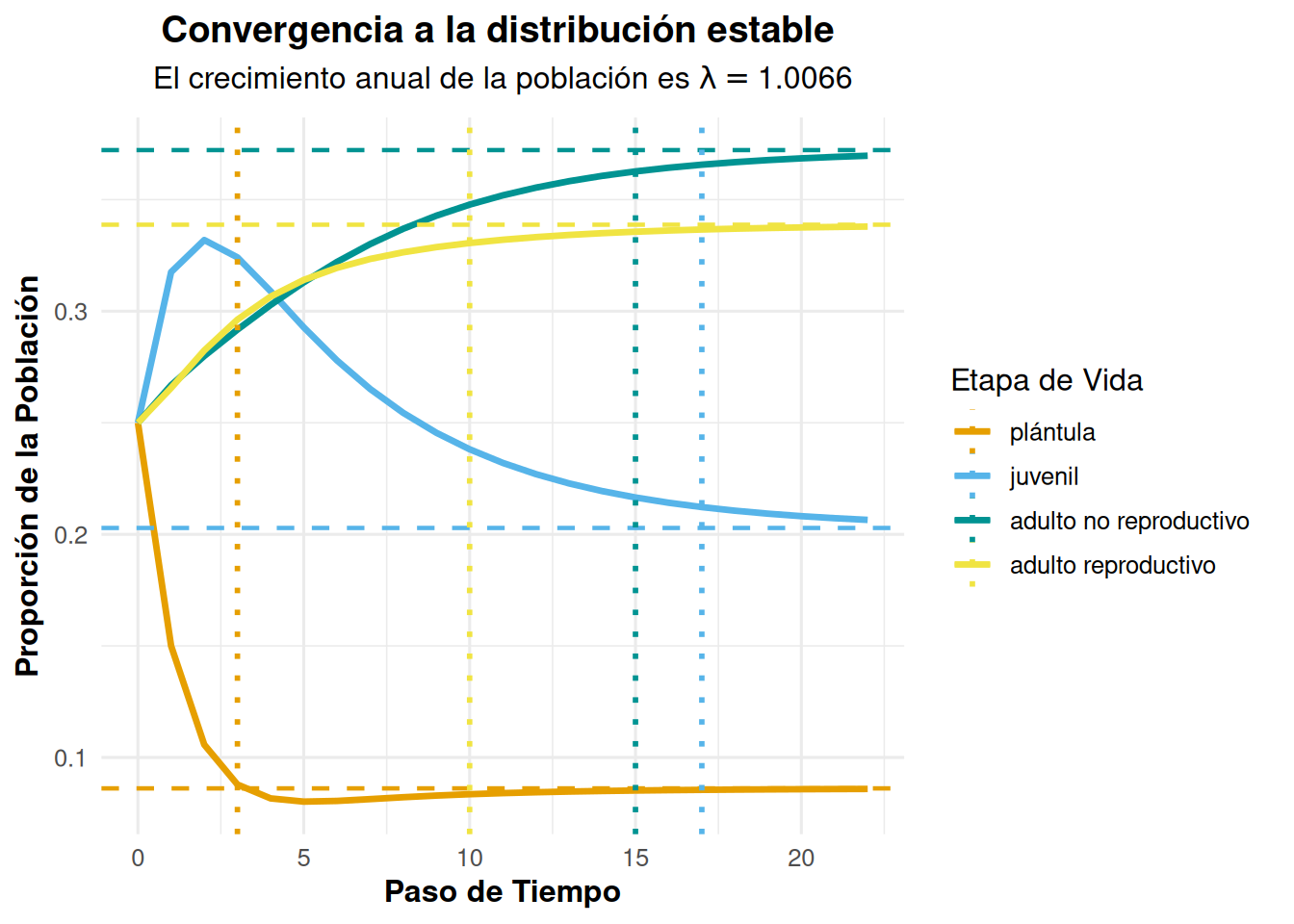
Estas propiedades estructurales permiten comprender el significado biológico de la tasa de crecimiento poblacional introducida en el capítulo sobre crecimiento poblacional.