---
description: "Guía práctica del paquete Rage organizada por pregunta de investigación: longevidad, expectativa de vida, edad reproductiva y métricas demográficas derivadas."
image: "images/Database_paper.png"
open-graph:
description: "Guía práctica del paquete Rage organizada por pregunta de investigación: longevidad, expectativa de vida, edad reproductiva y métricas demográficas derivadas."
twitter-card:
description: "Guía práctica del paquete Rage organizada por pregunta de investigación: longevidad, expectativa de vida, edad reproductiva y métricas demográficas derivadas."
---
# Rage y Orquídeas {#Rage}
Por: Raymond L. Tremblay
::: callout-note
## Qué es este capítulo
Este capítulo es una **guía práctica de uso del paquete `Rage`**, organizada por la **pregunta de investigación que cada métrica responde** —no por el orden alfabético de las funciones. Asume que ya tiene un objeto `CompadreDB` filtrado (capítulo anterior) o una matriz construida a mano (capítulos 5–8). Para cada función mostramos: la pregunta biológica, el código mínimo para responderla, y una interpretación de los resultados que tenga sentido en el contexto de orquídeas.
:::
::: callout-tip
## ¿Qué métrica para qué pregunta? — Guía rápida
| Si quiere responder… | Use la métrica | Función de `Rage` |
|----|----|----|
| ¿Cuánto vive un individuo en promedio? | Esperanza de vida media | `life_expect_mean()` |
| ¿Hay individuos longevos? ¿Y la varianza de longevidad? | Esperanza de vida + varianza | `life_expect_var()` |
| ¿Cada cuánto se reemplaza la población? | Tiempo generacional | `gen_time()` |
| ¿A qué edad los individuos llegan a reproducirse por primera vez? | Edad a la primera reproducción | `mature_age()` |
| ¿Qué proporción de individuos llegan a reproducirse? | Probabilidad de madurez | `mature_prob()` |
| ¿Cuántos descendientes deja un individuo a lo largo de su vida? | Tasa neta de reproducción ($R_0$) | `net_repro_rate()` |
| ¿La especie es iterópara o semélpara? | Entropía de Demetrius | `entropy_d()` |
| ¿Qué tan dispersa es la mortalidad a lo largo de la vida? | Entropía de Keyfitz | `entropy_k()` |
| ¿Qué tan rápido crece o decae la población? | Tasa asintótica $\lambda$ | `popbio::lambda()` (no `Rage`) |
| ¿Cómo se distribuyen los individuos entre etapas en estado estable? | Distribución estable de etapas | `popbio::stable.stage()` |
| ¿Qué transición tiene el mayor efecto sobre $\lambda$? | Sensibilidad / elasticidad | `popbio::elasticity()` |
:::
::: callout-warning
## Trampas comunes con `Rage`
- **Las funciones de `Rage` requieren las submatrices** (`matU`, `matF`, `matC`), **no la matriz A completa**. Use siempre `matU(x)`, `matF(x)`, `matC(x)` —no `matA(x)`.
- **Devuelven `NA` silenciosamente** sobre matrices degeneradas (filas vacías, columnas que suman cero, dimensiones incompatibles). Envuelva las llamadas en `tryCatch()` cuando aplique sobre listas grandes (ver ejemplos abajo).
- **El argumento `start`** define la etapa inicial desde la que se calcula la métrica. Por defecto es `start = 1L` (la primera etapa, normalmente plántula). Para una métrica desde el adulto, use el índice o nombre de la etapa adulta.
- **`life_expect_mean()` asume que el individuo "entra" al modelo en la etapa `start`**. Si su MPP comienza con una etapa cripto (banco de semillas, latencia), la esperanza de vida puede estar inflada.
- **`gen_time()` y `net_repro_rate()` requieren** que `matF` no sea idénticamente cero. Si la fecundidad sólo aparece en `matC` (clonal), use `matC` en vez de `matF` o redefina su pregunta.
:::
#### Librerías de R requeridas para el siguiente módulo
```{r Rage1, message=FALSE}
library(Rcompadre) # Paquete para trabajar con la base de datos de COMPADRE y COMADRE
library(tidyverse) # Paquete para activar múltiples paquetes
library(readxl)
library(broom)
library(ggdist)
library(distributional)
library(leaflet)
library(Rage) # función para calcular el largo de vida esperada entre otras
library(car)
library(popdemo)
library(skimr)
library(flextable) # Paquete para formatear tablas
source("R/figuras_helpers.R") # mat_to_ft(), compmat_to_ft(), pretty()
```
El presente capítulo examina una selección de funciones contenidas en el paquete `Rage`, diseñado para facilitar el análisis de datos provenientes de las bases de datos **COMPADRE** y **COMADRE**. Estos repositorios públicos reúnen información sobre la dinámica poblacional de plantas (**COMPADRE**) y animales (**COMADRE**), estructurada en matrices de transición por estados o edades (MPP). La librería `Rage` ofrece herramientas analíticas que permiten estimar parámetros demográficos clave, tales como la esperanza de vida, la edad de inicio de la reproducción, la entropía poblacional y la tasa de crecimiento, entre otros. A lo largo del capítulo, se ilustran algunas de estas funciones y se demuestra su aplicación en el estudio de la dinámica poblacional de especies de orquídeas.
```{r Rage2, echo=FALSE}
source("R/rlt_theme.R") # tema + paleta canónicos (R/rlt_theme.R)
```
------------------------------------------------------------------------
## Cargar la base de COMPADRE
Para los detalles de cómo obtener la base de datos, ver el [capítulo anterior](#Compadre). Aquí simplemente cargamos el *snapshot* incluido con el libro:
```{r Rage4, message=FALSE}
compadre <- readRDS("data/COMPADRE_2026.rds")
```
::: callout-tip
**Rage versus Rcompadre.** El paquete `Rcompadre` (capítulo anterior) se enfoca en **acceder y filtrar** la base; el paquete `Rage` se enfoca en **calcular métricas demográficas** a partir de las matrices ya filtradas. La división de tareas es intencional: cargar y validar es un paso, calcular esperanza de vida o entropía es otro. Ambos paquetes pertenecen a la misma familia y comparten convenciones de nombres (e.g., `matU()`, `matF()`).
:::
------------------------------------------------------------------------
### Filtrar para la familia *Orchidaceae*
Para filtrar únicamente las especies pertenecientes a la familia *Orchidaceae* en la base de datos COMPADRE, usamos la función `filter()` del paquete `dplyr`:
```{=latex}
\begin{landscape}
```
```{r Rage7}
Orquideas <- compadre %>%
filter(Family %in% c("Orchidaceae")) # Extraer las orquídeas de la base de datos.
# Orquideas es un objeto CompadreDB
meta_orq <- as.data.frame(cdb_metadata(Orquideas) |> head(n = 3))
meta_orq |>
dplyr::select(1:4) |>
flextable() |>
ft_wide()
```
```{=latex}
\end{landscape}
```
------------------------------------------------------------------------
## ¿Cuántos estudios únicos?
En este bloque de código se construye un nuevo conjunto de datos, SPECIES_O, que resume información clave sobre los estudios incluidos en la base de datos de orquídeas. Se seleccionan variables relevantes como el año de inicio y finalización del estudio (`StudyStart`, `StudyEnd`), el nombre científico aceptado de la especie (`SpeciesAccepted`), el año de publicación (`YearPublication`), los autores (`Authors`), el identificador del artículo (`DOI_ISBN`), el tipo de organismo (`OrganismType`), y el identificador de población (`MatrixPopulation`), junto con la matriz de proyección (`mat`).
Luego, se agrupan los datos por especie, año de publicación, tipo de organismo y periodo del estudio, y se calcula el número de poblaciones únicas muestreadas por especie mediante `length(unique(MatrixPopulation))`. El resultado se ordena alfabéticamente por especie y se normalizan los valores de los años como variables numéricas. Finalmente, se recodifica la variable `OrganismType` para traducir los términos originales del inglés al español: "Epiphyte" se convierte en "Epífita" y "Herbaceous perennial" en "Terrestre". Se eliminan los registros con valores faltantes en los años de inicio o finalización del estudio.
Este resumen permite visualizar de forma clara cuántas poblaciones fueron muestreadas por especie, en qué periodo se realizaron los estudios, y qué tipo de orquídea fue analizada, lo que facilita comparaciones entre especies y estudios.
```{r chap7, warning=FALSE, message=FALSE}
# names(Orquideas) Los nombres de las variables
SPECIES_O <- Orquideas %>%
select(
StudyStart,
StudyEnd,
SpeciesAccepted,
YearPublication,
Authors,
DOI_ISBN,
OrganismType,
MatrixPopulation,
mat
) %>%
group_by(
SpeciesAccepted,
YearPublication,
OrganismType,
StudyStart,
StudyEnd
) %>%
summarize(n_populations = length(unique(MatrixPopulation))) %>%
arrange(SpeciesAccepted) %>%
mutate(StudyStart = as.numeric(StudyStart)) %>%
mutate(StudyEnd = as.numeric(StudyEnd)) %>%
mutate(OrganismType_RC = fct_recode(OrganismType,
"Epífita" = "Epiphyte",
"Terrestre" = "Herbaceous perennial"
)) |>
drop_na(StudyStart, StudyEnd) |>
ungroup()
flextable(head(SPECIES_O))
# write_csv(SPECIES_O, "DATA/Species_O.csv")
```
------------------------------------------------------------------------
### Determinar cuántas poblaciones fueron muestreadas por especie
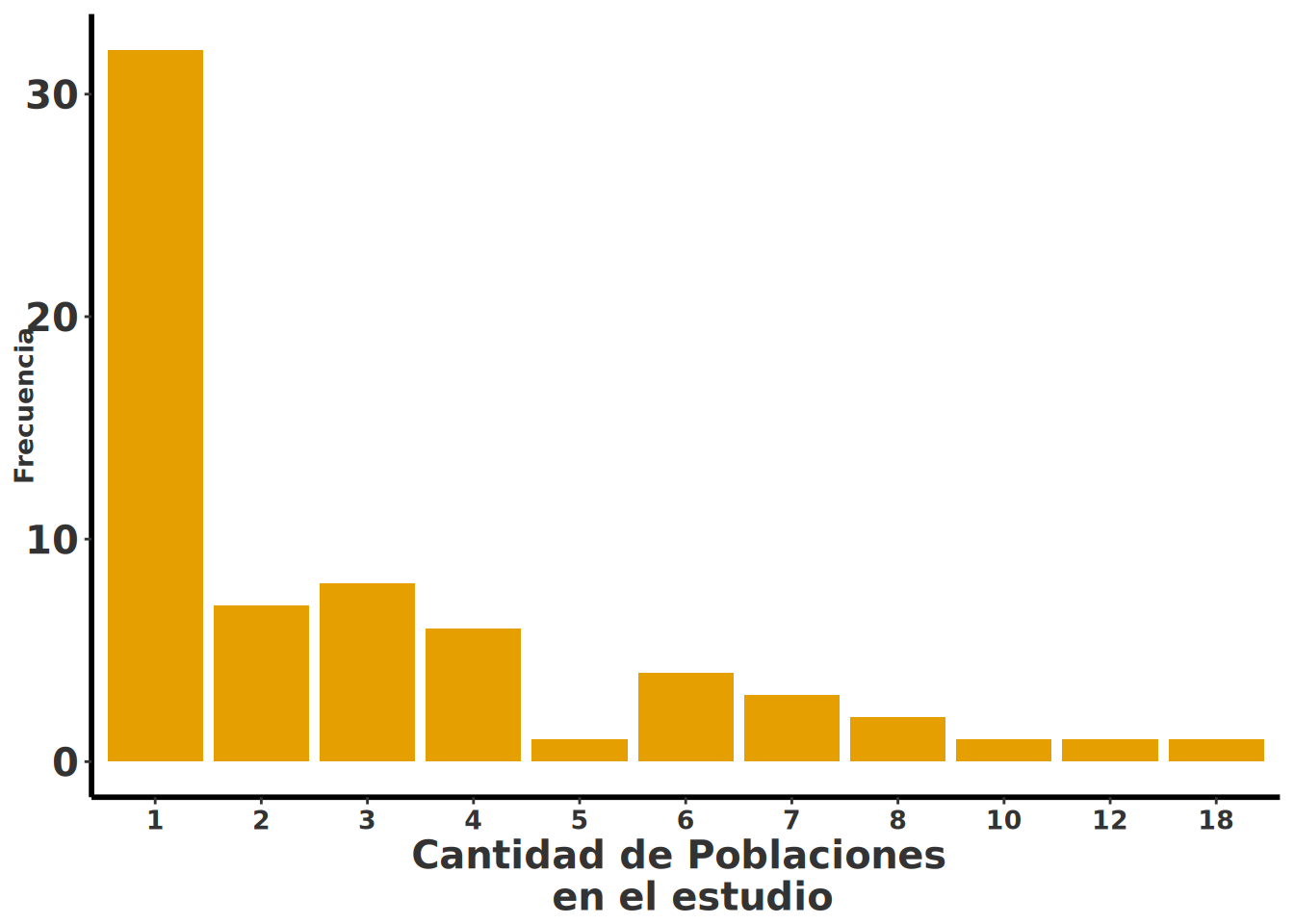
¿Cuál es la frecuencia de poblaciones por especie en la base de datos?
- La mayoría de las especies fueron estudiadas en una sola población.
- Sin embargo, hay casos en los que se muestrearon hasta 18 poblaciones distintas para una misma especie.
Este gráfico permite observar claramente la concentración de estudios en pocas poblaciones, así como los casos excepcionales con mayor cobertura. Esto puede reflejar diferencias en el diseño de los estudios, disponibilidad de datos o interés ecológico particular en ciertas especies.
```{r}
#| label: fig-Rage8
#| fig-cap: "Gráfico de barras (geom_bar) de la frecuencia de estudios según la cantidad de poblaciones muestreadas, generado con ggplot a partir de SPECIES_O."
as.data.frame(table(SPECIES_O$n_populations)) |>
ggplot(aes(Var1, Freq)) +
geom_bar(stat = "identity", aes(fill = "lightblue")) +
rlt_style_fill() +
ylab("Frecuencia") +
xlab("Cantidad de Poblaciones \n en el estudio") +
theme(legend.position = "none")
```
------------------------------------------------------------------------
### La cantidad de poblaciones por especies en la base de datos de COMPADRE.
La cantidad de poblaciones muestreadas por especie en la base de datos de COMPADRE varía considerablemente. Aunque la mayoría de las especies están representadas por una sola población, existen casos en los que se han registrado hasta 20 poblaciones distintas para una misma especie. Estas poblaciones pueden provenir de diferentes publicaciones científicas o representar datos recolectados en distintos momentos o con distintos objetivos dentro de una misma población. Por ejemplo, los datos de *Lepanthes rupestris* provienen de dos estudios independientes [@tremblay2001gene; @tremblay2014bayesian]. En el primero, se utilizaron matrices poblacionales para estimar el tamaño efectivo de las poblaciones (Ne), mientras que en el segundo se emplearon los mismos datos para desarrollar un enfoque bayesiano que permite estimar los elementos de las matrices de transición, especialmente útil cuando se dispone de pocos datos por población o periodo. Este enfoque aprovecha la información conjunta de todas las poblaciones para generar estimaciones más robustas y biológicamente realistas.
------------------------------------------------------------------------
### ¿Cuán largos fueron los estudios?
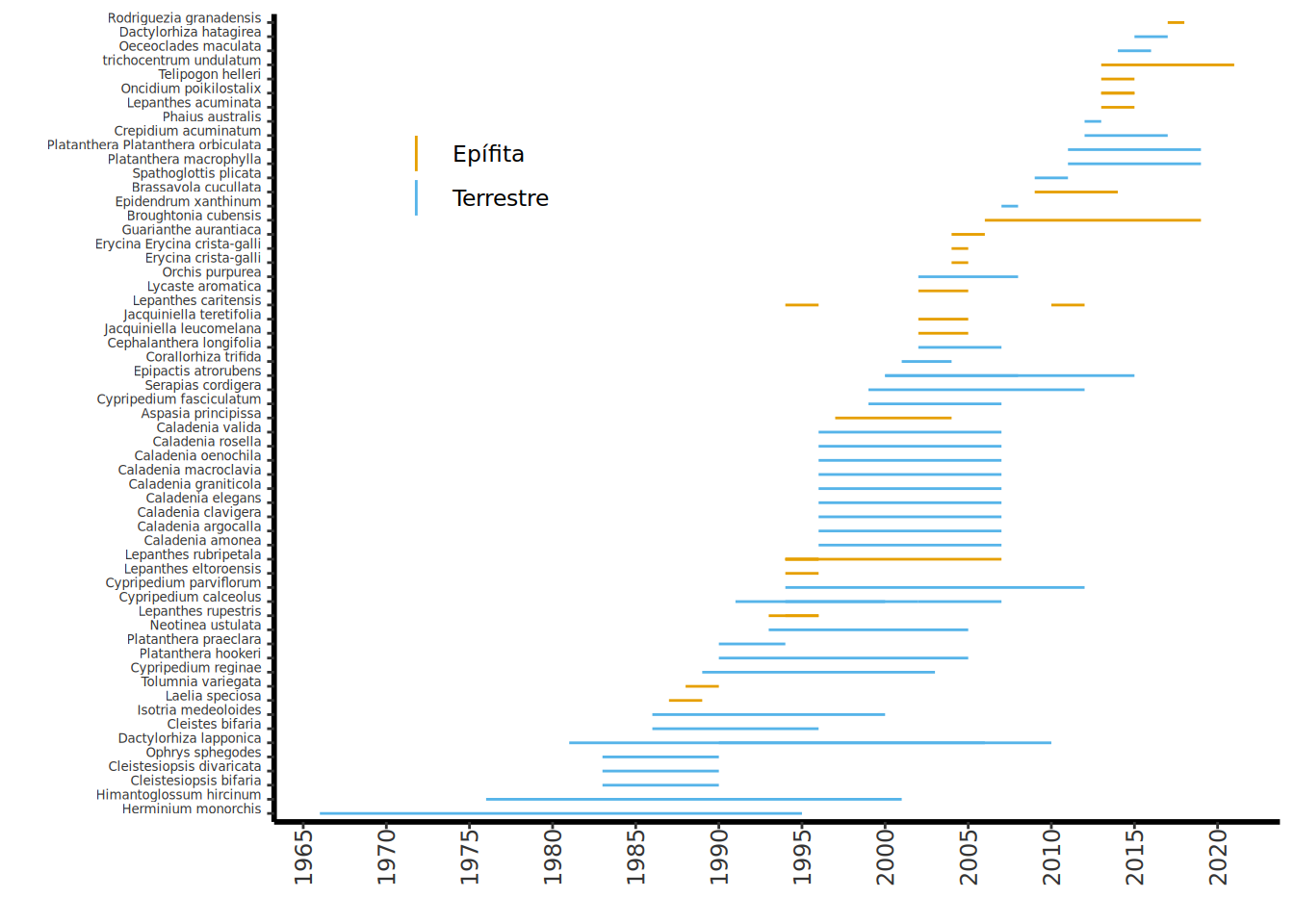
La duración de los estudios en la base de datos de orquídeas de COMPADRE varía considerablemente. Aunque muchos estudios abarcan solo unos pocos años —el mínimo requerido para calcular una matriz de transición poblacional es de dos periodos—, también existen investigaciones que se extienden por lapsos más prolongados. Algunos estudios, como los realizados por Tremblay con *Lepanthes rupestris*, incluyen muestreos mensuales, mientras que otros se basan en observaciones anuales. Esta diversidad en la temporalidad refleja tanto los objetivos específicos de cada investigación como las estrategias metodológicas empleadas.
La siguiente visualización muestra cómo varía la duración de los estudios según el tipo de orquídea, diferenciando entre especies epífitas y terrestres:
```{r}
#| label: fig-Rage9
#| fig-height: 10
#| fig-cap: "Diagrama de rangos (geom_linerange con coord_flip) que muestra el inicio y el fin de cada estudio por especie, coloreado según OrganismType_RC."
SPECIES_O$SpeciesAccepted <- fct_reorder(
SPECIES_O$SpeciesAccepted,
SPECIES_O$StudyStart,
.desc = FALSE
)
ggplot(SPECIES_O, aes(SpeciesAccepted, ymin = StudyStart, ymax = StudyEnd, color = OrganismType_RC)) +
geom_linerange() +
coord_flip() +
theme(legend.position.inside = c(0.2, 0.8)) +
ylab("") +
xlab("") +
rlt_style_colour() +
theme(
axis.text.x = element_text(
color = "grey20",
size = 9,
angle = 90,
hjust = .5,
vjust = .5,
face = "plain"
),
axis.text.y = element_text(
color = "grey20",
size = 7,
angle = 0,
hjust = 1,
vjust = 0,
face = "plain"
),
axis.title.x = element_text(
color = "grey20",
size = 12,
angle = 0,
hjust = .5,
vjust = 0,
face = "plain"
),
axis.title.y = element_text(
color = "grey20",
size = 12,
angle = 90,
hjust = .5,
vjust = .5,
face = "plain"
)
) +
theme(
legend.position = c(0.2, 0.8),
legend.title = element_blank()
) +
theme(axis.text.y = element_text(size = 8)) +
scale_y_continuous(n.breaks = 12)
# ggsave("images/Lenght_survey.png")
```
------------------------------------------------------------------------
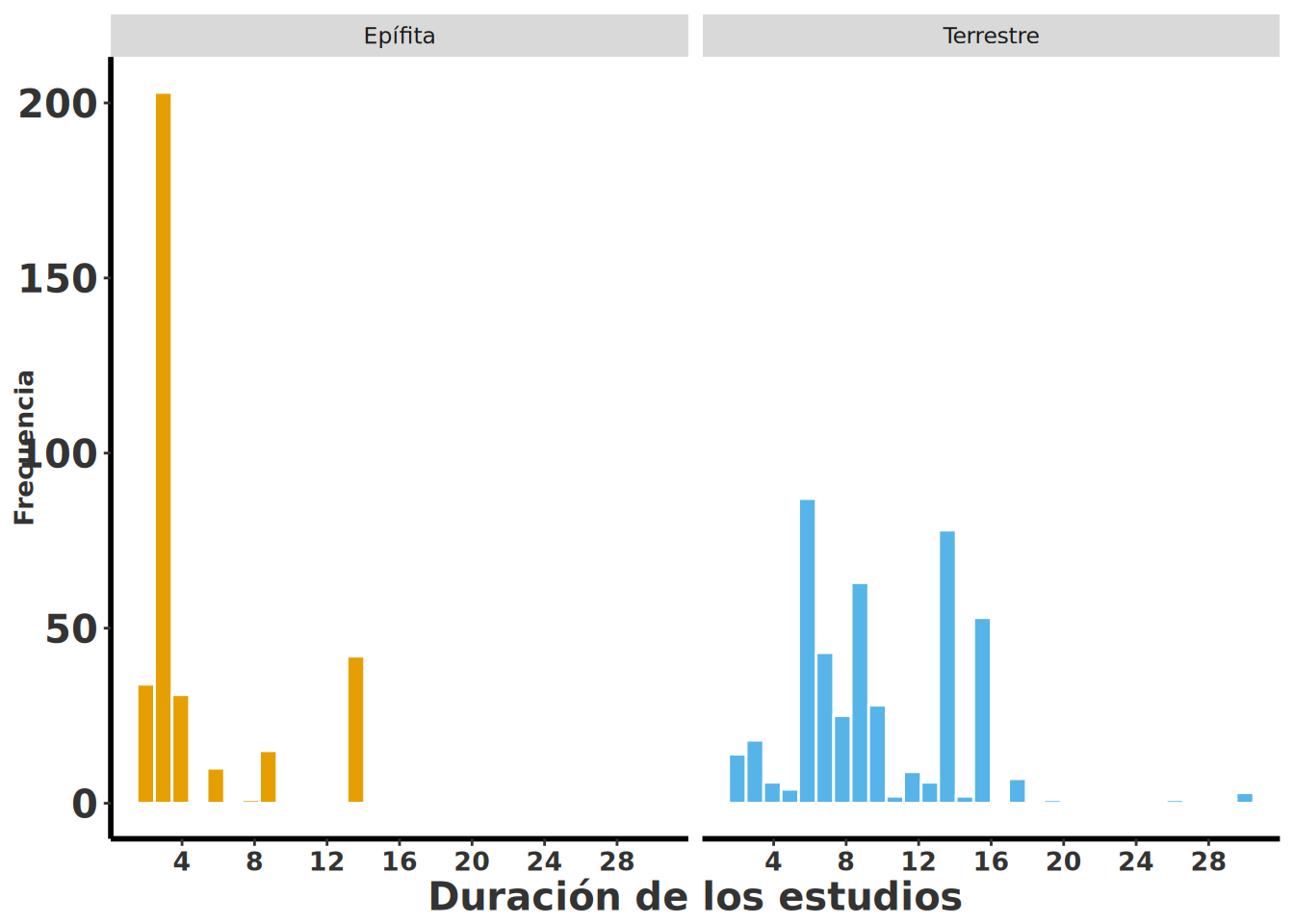
### Tiempo de duración de las investigaciones.
La siguiente figura muestra la duración de los estudios realizados sobre orquídeas epífitas y terrestres. Según los datos extraídos de la base de datos COMPADRE, la mayoría de las investigaciones tuvieron una duración relativamente corta, especialmente en el caso de las especies epífitas. Sin embargo, también se registran estudios que se extendieron por más de 20 años, lo que evidencia un compromiso a largo plazo en algunos casos para entender mejor la dinámica poblacional de estas plantas.
```{r, message=FALSE, warning=FALSE}
#| label: fig-Rage10
#| fig-cap: "Histograma de la duración de los estudios en Orquideas con relleno por OrganismType_RC y facetas por tipo de organismo (epífita o terrestre)."
Orquideas <- Orquideas %>%
mutate(
StudyDuration = as.numeric(StudyDuration),
OrganismType_RC = fct_recode(
OrganismType,
"Epífita" = "Epiphyte",
"Terrestre" = "Herbaceous perennial"
)
)
# table(Orquideas$StudyDuration)
# table(Orquideas$OrganismType)
ggplot(Orquideas, aes(StudyDuration, fill = OrganismType_RC)) +
geom_histogram(colour = "white") +
facet_wrap(~OrganismType_RC) +
theme(legend.position = "none") +
xlab("Duración de los estudios") +
ylab("Frecuencia") +
rlt_style_fill() +
scale_x_continuous(n.breaks = 10) +
theme(axis.text.x = element_text(angle = 45, hjust = 1))
# ggsave("Duración_Epi_Ter.pdf")
ggsave("images/Duración_Epi_Ter.png")
```
------------------------------------------------------------------------
------------------------------------------------------------------------
### Cálculo del Valor Propio Dominante (λ) en Matrices Ergódicas e Irreducibles
A partir del conjunto de matrices previamente filtradas por cumplir con las condiciones de ergodicidad e irreducibilidad, se procede al cálculo del valor propio dominante ($\lambda$), el cual representa la tasa de crecimiento poblacional asintótica en modelos matriciales.
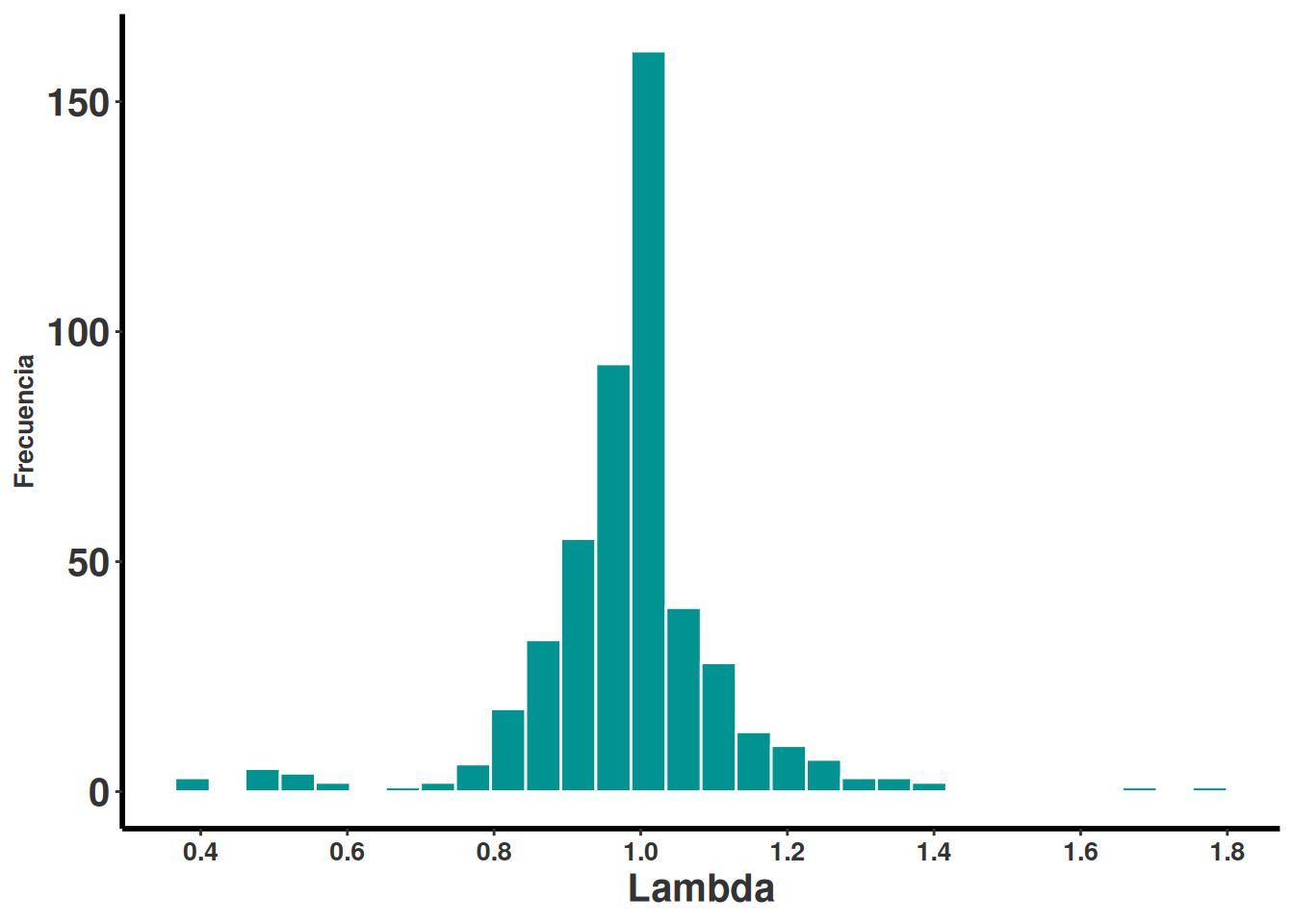
Para ello, se emplea la función `eigs()` del paquete `popdemo`, que permite obtener los valores propios de una matriz. Esta función se aplica a cada matriz seleccionada mediante `sapply()`, generando una lista de valores de ($\lambda$) almacenados en el objeto `lambdaVals`. Cada entrada en esta lista corresponde al valor propio dominante de una matriz `matA` incluida en el conjunto de datos.
Posteriormente, se utiliza la función `summary()` para obtener una descripción estadística de los valores de ($\lambda$), y la función `hist()` para visualizar su distribución, lo que permite evaluar la variabilidad en las tasas de crecimiento poblacional entre las distintas especies o poblaciones representadas.
#### Matrices ergódicas e irreductibles
```{=latex}
\begin{landscape}
```
```{r Rage12c}
Compadre_flagged <- cdb_flag(Orquideas)
Mat_erg_irred <- subset(
Compadre_flagged,
check_NA_A == FALSE & check_irreducible == TRUE & check_ergodic == TRUE
) # para evaluar si las matrices son ergódicas e irreducibles al mismo tiempo
meta_ei_R <- as.data.frame(cdb_metadata(Mat_erg_irred) |> head(n = 2))
meta_ei_R |>
dplyr::select(1:4) |>
flextable() |>
ft_wide()
```
```{=latex}
\end{landscape}
```
```{r Rage13, warning=FALSE, message=FALSE}
lambdaVals_list <- sapply(matA(Mat_erg_irred), popdemo::eigs, what = "lambda")
lambdaVals <- as_tibble(lambdaVals_list)
tidy(lambdaVals) |> flextable()
ggplot(lambdaVals, aes(value)) +
geom_histogram(aes(fill = "lightblue"), colour = "white") +
rlt_style_fill() +
xlab("Lambda") +
ylab("Frecuencia") +
scale_x_continuous(n.breaks = 10) +
theme(legend.position = "none")
```
Una metodología alternativa para calcular los valores propios dominantes ($\lambda$) de las matrices de transición poblacional consiste en utilizar la función `map_dbl()` de la librería `purrr`. Esta función permite aplicar una operación a cada elemento de una lista, devolviendo un vector numérico de igual longitud. En este contexto, se aplica una función de cálculo de $\lambda$ a cada matriz de transición (matA), obteniendo así un valor de $\lambda$ por matriz. Esta estrategia resulta eficiente para el procesamiento simultáneo de múltiples matrices dentro de un flujo de trabajo reproducible en R.
```{r Rage23}
## con el paquete popdemo
lambdaVals1 <- map_dbl(
matA(Mat_erg_irred),
~ popdemo::eigs(.x, what = "lambda")
)
## O puede calcular lambda con el paquete popbio, que evita algunos mensajes de advertencia
lambdaVals2 <- map_dbl(matA(Mat_erg_irred), ~ popbio::lambda(.x))
```
------------------------------------------------------------------------
## Demografía con `Rage`
Hasta este punto hemos usado `Rcompadre` para acceder y filtrar matrices, y `popbio`/`popdemo` para calcular $\lambda$. El paquete `Rage` complementa este flujo con funciones que derivan estadísticos demográficos directamente de las matrices U, F y C. A continuación mostramos tres ejemplos sobre el subconjunto filtrado en `Mat_erg_irred`.
::: callout-tip
## Recordatorio sobre las submatrices
Las funciones de `Rage` requieren que las matrices estén descompuestas en sus partes (U = supervivencia/crecimiento, F = fecundidad sexual, C = crecimiento clonal). Por eso se extraen con `matU()`, `matF()` y `matC()` en lugar de usar la matriz completa A.
:::
### Esperanza de vida — ¿cuánto vive un individuo?
**Pregunta biológica.** Dado que un individuo sobrevive su etapa inicial (plántula), ¿cuánto tiempo vive en promedio? `life_expect_mean()` lo calcula a partir de la matriz U, modelándola como una cadena de Markov absorbente donde "muerte" es el estado absorbente.
```{r Rage_lifeexpect}
# life_expect_mean(), gen_time() y mature_age() modelan la matriz U como una
# cadena de Markov ABSORBENTE: calculan la matriz fundamental N = (I - U)^-1 y
# suman sus columnas. Esto solo tiene sentido si toda etapa puede llegar a la
# muerte, es decir, si cada columna de U suma < 1 (siempre hay algo de
# mortalidad). Si colSums(U) >= 1, el individuo es "inmortal", (I - U) es
# (casi) singular y su inversa devuelve valores NEGATIVOS o ENORMES —datos sin
# sentido biológico (ver el capítulo correspondiente). tryCatch() solo atrapa
# los casos que fallan por completo (NA); los casi-singulares NO dan error y se
# colarían como basura. Por eso filtramos con es_valida ANTES de calcular.
U_valido <- function(U, tol = 1e-8) {
all(is.finite(U)) && all(colSums(U) < 1 - tol)
}
matsU <- matU(Mat_erg_irred)
matsF <- matF(Mat_erg_irred)
es_valida <- map_lgl(matsU, U_valido)
esperanza_vida <- map_dbl(
matsU,
~ if (U_valido(.x)) {
tryCatch(Rage::life_expect_mean(.x, start = 1L),
error = function(e) NA_real_
)
} else {
NA_real_
}
)
pretty(summary(esperanza_vida))
```
De las `r length(es_valida)` matrices del subconjunto, `r sum(!es_valida)` tienen al menos una columna de U con supervivencia ≥ 1 (sin sentido biológico) y se excluyen de esta y las dos métricas siguientes; las `r sum(es_valida)` restantes son cadenas de Markov absorbentes válidas.
::: callout-tip
## Interpretación
Una esperanza de vida alta (\> 30 pasos de tiempo) indica una especie longeva con mortalidad adulta baja —típico de orquídeas epífitas adultas establecidas. Valores bajos (\< 5 pasos de tiempo) sugieren mortalidad juvenil dominante, lo que es esperable cuando `start = 1L` corresponde a plántulas con supervivencia baja. Si el valor parece irrealista, verifique: (1) que `start` apunte a la etapa correcta, y (2) que la matriz U no contenga valores de supervivencia perfecta (ver el capítulo sobre datos sin sentido biológico).
:::
### Tiempo generacional — ¿cada cuánto se reemplaza la población?
**Pregunta biológica.** ¿Cuántos años (o pasos de tiempo) pasan entre que un individuo nace y produce su descendencia "promedio"? Es la unidad fundamental para comparar la velocidad evolutiva entre especies. `gen_time()` combina la matriz U (supervivencia/crecimiento) con la matriz F (reproducción).
```{r Rage_gentime}
# Misma condición que en esperanza de vida: gen_time() integra sobre (I - U)^-1,
# así que una U con colSums >= 1 produce tiempos generacionales sin sentido.
# Reutilizamos es_valida (definido en el chunk Rage_lifeexpect) para excluir
# esas matrices antes de calcular.
tiempo_gen <- pmap_dbl(
list(matsU, matsF, es_valida),
function(U, Fmat, ok) {
if (ok) {
tryCatch(Rage::gen_time(U, Fmat), error = function(e) NA_real_)
} else {
NA_real_
}
}
)
pretty(summary(tiempo_gen))
```
::: callout-tip
## Interpretación
Un tiempo generacional alto (\> 10) indica especies "lentas", longevas, con generaciones traslapadas —el patrón típico de orquídeas epífitas perennes. Tiempos bajos (\< 2) sugieren especies "rápidas" con ciclos cortos —raras en orquídeas, comunes en hierbas anuales. Las orquídeas terrestres templadas y las epífitas tropicales suelen ubicarse en el rango 5–25, dependiendo de la longevidad observada. Comparar tiempos generacionales entre poblaciones de la misma especie en hábitats distintos es una forma poderosa de detectar diferenciación demográfica local.
:::
### Edad de primera reproducción — ¿cuándo arranca la reproducción?
**Pregunta biológica.** ¿A qué edad llega un individuo, en promedio, a su primera etapa reproductiva? Es un componente clave de las estrategias de historia de vida —la diferencia entre "rápido y arriesgado" y "lento y seguro". `mature_age()` integra a través de la matriz U partiendo de la etapa `start`.
```{r Rage_matureage}
# Igual que las dos métricas anteriores: mature_age() integra a través de la
# matriz U, por lo que una U con colSums >= 1 (supervivencia perfecta) da
# resultados sin sentido. Reutilizamos es_valida para excluir esas matrices.
edad_madurez <- pmap_dbl(
list(matsU, matsF, es_valida),
function(U, Fmat, ok) {
if (ok) {
tryCatch(Rage::mature_age(U, Fmat, start = 1L), error = function(e) NA_real_)
} else {
NA_real_
}
}
)
pretty(summary(edad_madurez))
```
::: callout-tip
## Interpretación
En orquídeas terrestres templadas se han documentado edades de primera reproducción de 5–15 años; en epífitas tropicales el rango puede ser similar o mayor. Comparar `mature_age` con `life_expect_mean` da el "esfuerzo prereproductivo" relativo: si un individuo gasta el 40% de su vida esperada antes de reproducirse, la mortalidad juvenil tiene un peso desproporcionado en la dinámica poblacional —y por tanto en cualquier estrategia de conservación.
:::
::: callout-warning
## Cómo defender estos números frente a una revisión crítica
Las tres métricas anteriores son robustas matemáticamente pero **sensibles** a tres decisiones del modelador: 1. **Etapa inicial (`start`).** ¿Está reportando esperanza de vida desde la semilla, la plántula, o el adulto recién reclutado? Especifique siempre. 2. **Calidad de la matriz U.** Si `colSums(matU) == 1` para alguna columna (supervivencia perfecta —ver capítulo sobre datos sin sentido biológico), las tres métricas se inflan artificialmente. La esperanza de vida puede tender a infinito. 3. **Reproducción clonal vs. sexual.** Si la mayoría de la reproducción ocurre en `matC` (clonal) y `matF` está casi vacía, `gen_time()` y `mature_age()` no representan lo que el lector espera. Reporte ambas matrices y, si la clonalidad domina, considere usar `matU + matC` en lugar de `matU + matF`.
:::
------------------------------------------------------------------------
## Variación en el crecimiento poblacional entre especies epífitas y terrestres
En esta sección se seleccionan las especies clasificadas como epífitas y terrestres, agrupándolas en objetos distintos que contienen todas las poblaciones muestreadas correspondientes. Esta separación permite evaluar comparativamente la variación en las tasas de crecimiento poblacional entre ambos grupos funcionales, facilitando el análisis de patrones ecológicos y demográficos asociados a sus respectivos hábitos de vida.
::: callout-warning
## Cuidado con la pseudoreplicación
Cada matriz de COMPADRE corresponde a una combinación específica de población, año y especie. Una sola especie puede aportar muchas matrices, de modo que comparar directamente los $\lambda$ entre grupos (epífitas vs. terrestres) sin tener en cuenta esta estructura jerárquica subestima la varianza real y puede inflar las diferencias aparentes. Para inferencias formales conviene usar modelos mixtos con la especie (y, idealmente, la población) como efecto aleatorio.
:::
```{r Rage25}
epifitas <- Orquideas %>%
filter(OrganismType == "Epiphyte")
terrestres <- Orquideas %>%
filter(OrganismType == "Herbaceous perennial")
```
```{r Rage26}
Compadre_flagged_epif <- cdb_flag(epifitas)
x_epif <- subset(
Compadre_flagged_epif,
check_NA_A == FALSE & check_ergodic == TRUE
)
# sapply(matA(x_epi), popdemo::eigs, what="lambda")
lambda_epif <- map_dbl(matA(x_epif), ~ popdemo::eigs(.x, what = "lambda"))
# Or with popbio, which avoids some warning messages…
Compadre_flagged_terrestres <- cdb_flag(terrestres)
x_terr <- subset(
Compadre_flagged_terrestres,
check_NA_A == FALSE & check_ergodic == TRUE
)
lambda_terr <- map_dbl(matA(x_terr), ~ popdemo::eigs(.x, what = "lambda"))
```
------------------------------------------------------------------------
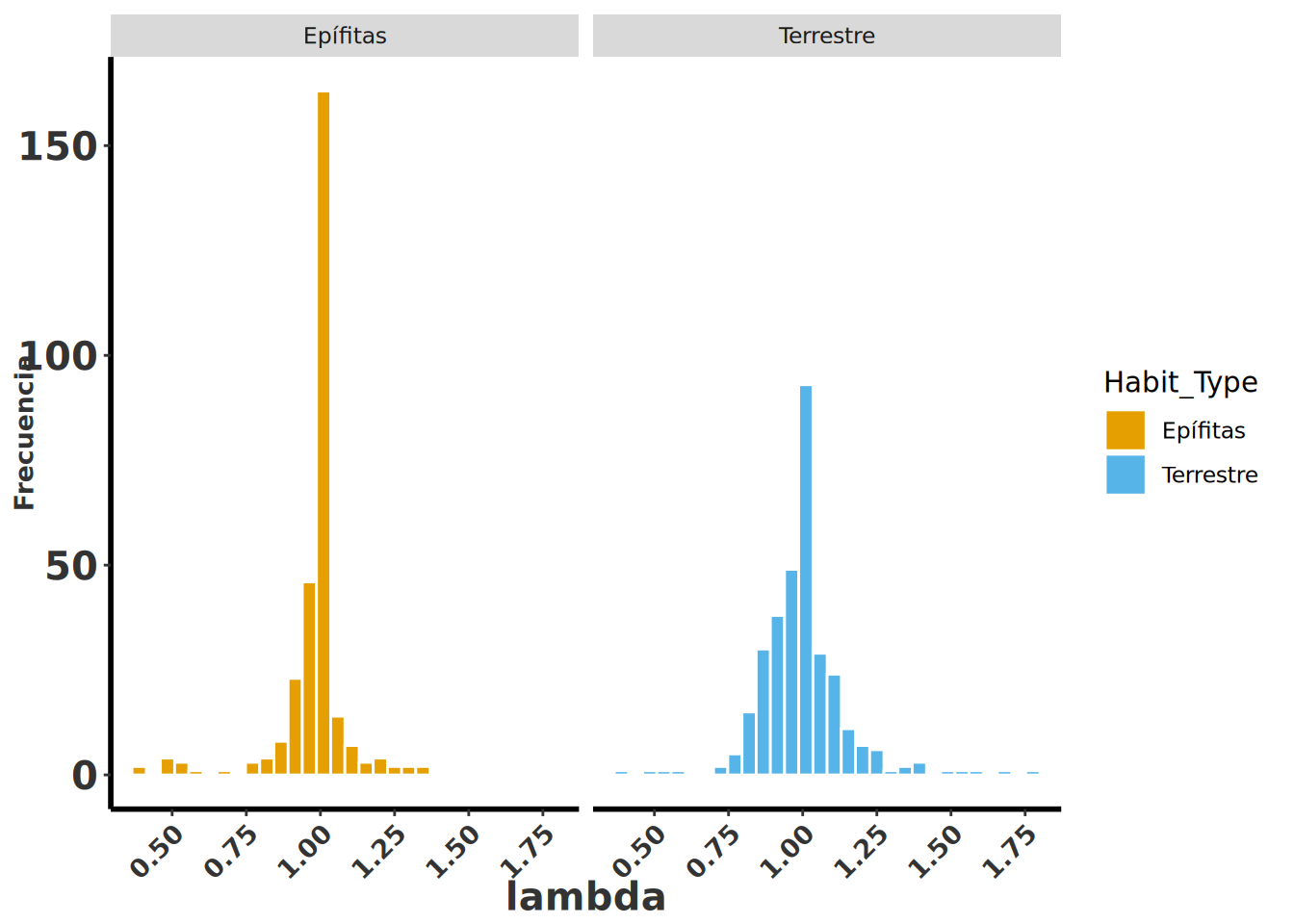
### Evaluación de Tendencias Centrales y Dispersión en Especies Terrestres y Epífitas
Mediante el uso de la función summary, se analizaron las medidas de tendencia central y dispersión de los valores propios de lambda correspondientes a especies terrestres y epífitas. Los resultados indican que las especies terrestres presentan una mayor dispersión en los valores de lambda en comparación con las especies epífitas. Aunque los promedios difieren ligeramente entre ambos grupos, las medianas resultaron ser similares, lo que sugiere patrones demográficos comparables en términos de centralidad, pero con variabilidad distinta en su comportamiento poblacional.
```{r Rage27}
library(flextable)
# Calcular resúmenes
epif_summary <- summary(lambda_epif)
terr_summary <- summary(lambda_terr)
# Unire los resúmenes en un solo data frame
combined_df <- rbind(
Epífita = epif_summary,
Terrestre = terr_summary
)
# Convertir a data frame y añadir columna de hábitat
combined_df <- as.data.frame(combined_df)
combined_df$Habit <- rownames(combined_df)
# Reordenar columnas
combined_df <- combined_df[, c("Habit", names(epif_summary))]
flextable(combined_df)
```
Para visualizar los datos en una figura de `ggplot2`, hay que convertir estas filas en un *data frame* y añadir una columna con el tipo de hábitat, renombrar la columna lambda y unir los dos *data frames* en uno solo.
```{r Rage28}
df_Lamb_epif <- as.data.frame(lambda_epif)
df_Lamb_terr <- as.data.frame(lambda_terr)
```
Crear una columna con el tipo de hábitat y renombrar la columna lambda
```{r Rage28b}
df_Lamb_epi <- df_Lamb_epif %>%
add_column(Habit_Type = "Epífitas") %>%
rename(lambda = lambda_epif)
df_Lamb_terr <- as.data.frame(lambda_terr)
df_Lamb_terr <- df_Lamb_terr %>%
add_column(Habit_Type = "Terrestre") %>%
rename(lambda = lambda_terr)
```
Unir los dos data.frame en uno solo
```{r Rage28c}
ALL_Lambdas <- rbind(df_Lamb_epi, df_Lamb_terr) # unir los dos data frame en uno
```
Visualizar el crecimiento poblacional por tipo de hábitat
```{r, warning=FALSE, message=FALSE}
#| label: fig-Rage29
#| fig-cap: "Histograma de los valores de lambda en ALL_Lambdas con relleno por Habit_Type y facetas por hábito de vida."
ggplot(ALL_Lambdas, aes(lambda, fill = Habit_Type)) +
geom_histogram(colour = "white") +
facet_wrap(~Habit_Type) +
rlt_style_fill() +
scale_x_continuous(n.breaks = 8) +
theme(axis.text.x = element_text(angle = 45, hjust = 1)) +
ylab("Frecuencia")
# ggsave("images/Terr_Epi_lambda.png")
```
------------------------------------------------------------------------
## Estimación del crecimiento promedio y evaluación de diferencias significativas
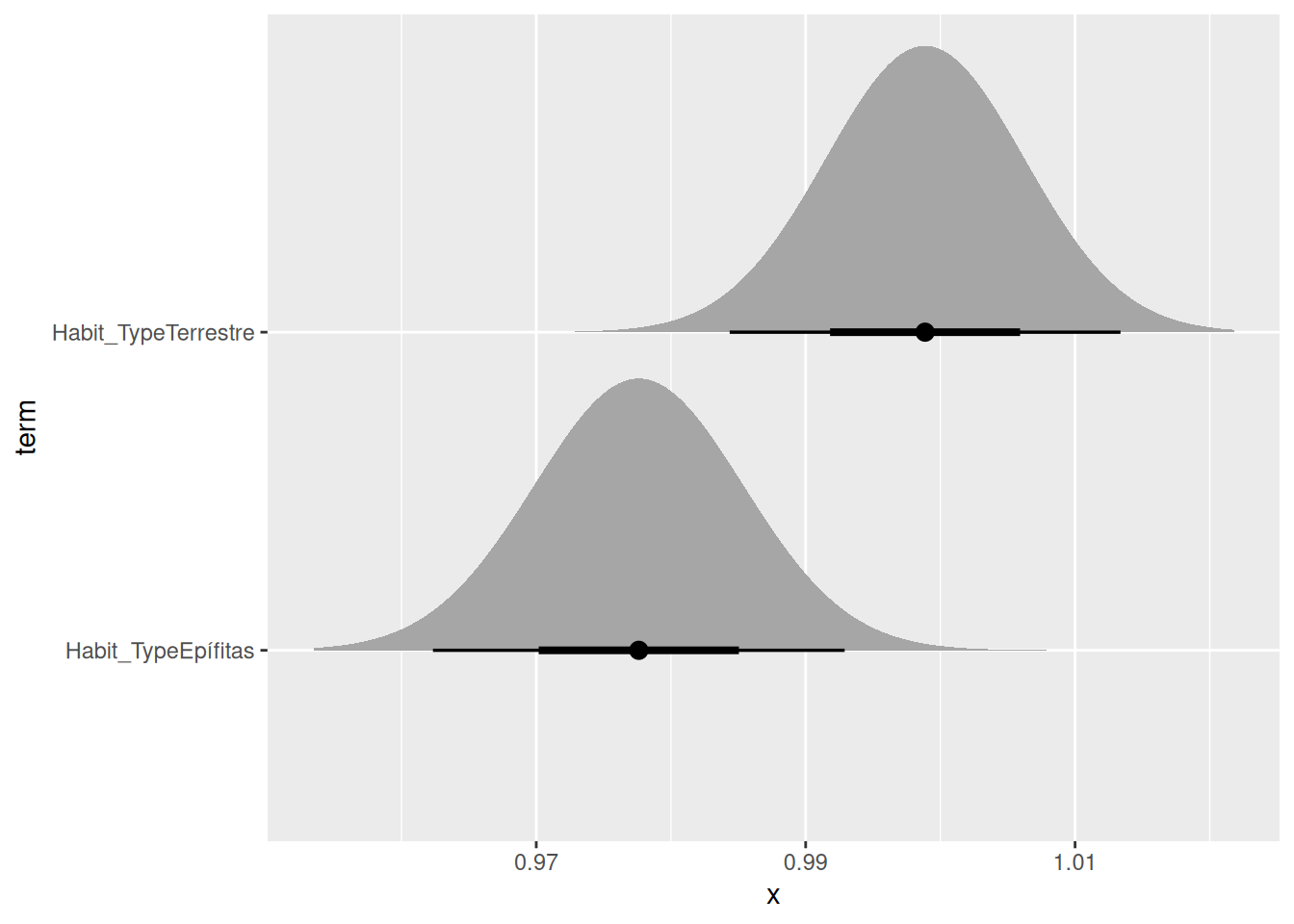
Para evaluar si existen diferencias significativas en los valores propios de lambda entre especies epífitas y terrestres, se emplea un modelo lineal utilizando la función `lm()`. En este análisis, la variable **Habit_Type** se utiliza como predictor del valor propio dominante ($\lambda$), lo que permite estimar el efecto del tipo de hábitat sobre la tasa de crecimiento poblacional. Los resultados del modelo indican que las especies epífitas tienden a presentar valores de lambda más bajos en comparación con las especies terrestres. Para obtener los coeficientes específicos de cada grupo, se ajusta un segundo modelo excluyendo el intercepto mediante la inclusión de `-1` en la fórmula. Esta parametrización permite calcular directamente el promedio de lambda para cada grupo funcional, facilitando la comparación entre ellos.
::: callout-note
## ¿Modelar $\lambda$ o $\log(\lambda)$?
Los valores de $\lambda$ son estrictamente positivos y su escala es multiplicativa: $\lambda = 1$ separa crecimiento de declive y los desvíos por arriba (1.2) y por abajo (0.8) no son simétricos. Por eso muchos demógrafos prefieren modelar $\log(\lambda)$ (o $r = \log(\lambda)$), que sí es simétrico alrededor de cero, suele cumplir mejor los supuestos de normalidad, y conecta directamente con la teoría de crecimiento estocástico (ver el capítulo de simulaciones). Para el ajuste mostrado aquí podrías usar `lm(log(lambda) ~ Habit_Type, data = ALL_Lambdas)`.
:::
```{r Rage30}
model_lambda <- lm(lambda ~ Habit_Type, data = ALL_Lambdas)
# summary(model_lambda)
model_lambda_epi_terr <- lm(lambda ~ Habit_Type - 1, data = ALL_Lambdas)
# summary(model_lambda_epi_terr)
tidy_results <- tidy(model_lambda_epi_terr)
flextable(tidy_results)
```
------------------------------------------------------------------------
### Visualización de las distribuciones de los lambda's
Para representar gráficamente las distribuciones de los coeficientes estimados en el modelo lineal, se emplean las librerías `ggdist` y `distributional`, utilizando la función `stat_halfeye()`. Esta función permite visualizar la forma y dispersión de las distribuciones de los parámetros, proporcionando una representación intuitiva de la incertidumbre asociada a cada estimación. Es importante destacar que `stat_halfeye()` requiere especificar explícitamente la distribución de los datos; en este análisis, se asume que los valores propios de lambda ($\lambda$) siguen una distribución normal. La información utilizada para esta visualización proviene del modelo ajustado previamente (model_lambda), lo que permite comparar directamente los coeficientes entre grupos funcionales como epífitas y terrestres.
```{r}
#| label: fig-Rage31
#| fig-cap: "Gráfico stat_halfeye de las distribuciones t de Student de los coeficientes del modelo model_lambda_epi_terr extraídos con tidy()."
model_lambda_epi_terr %>%
tidy() %>%
ggplot(aes(y = term)) +
stat_halfeye(
aes(
xdist = dist_student_t(
df = df.residual(model_lambda_epi_terr),
mu = estimate,
sigma = std.error
)
)
)
```
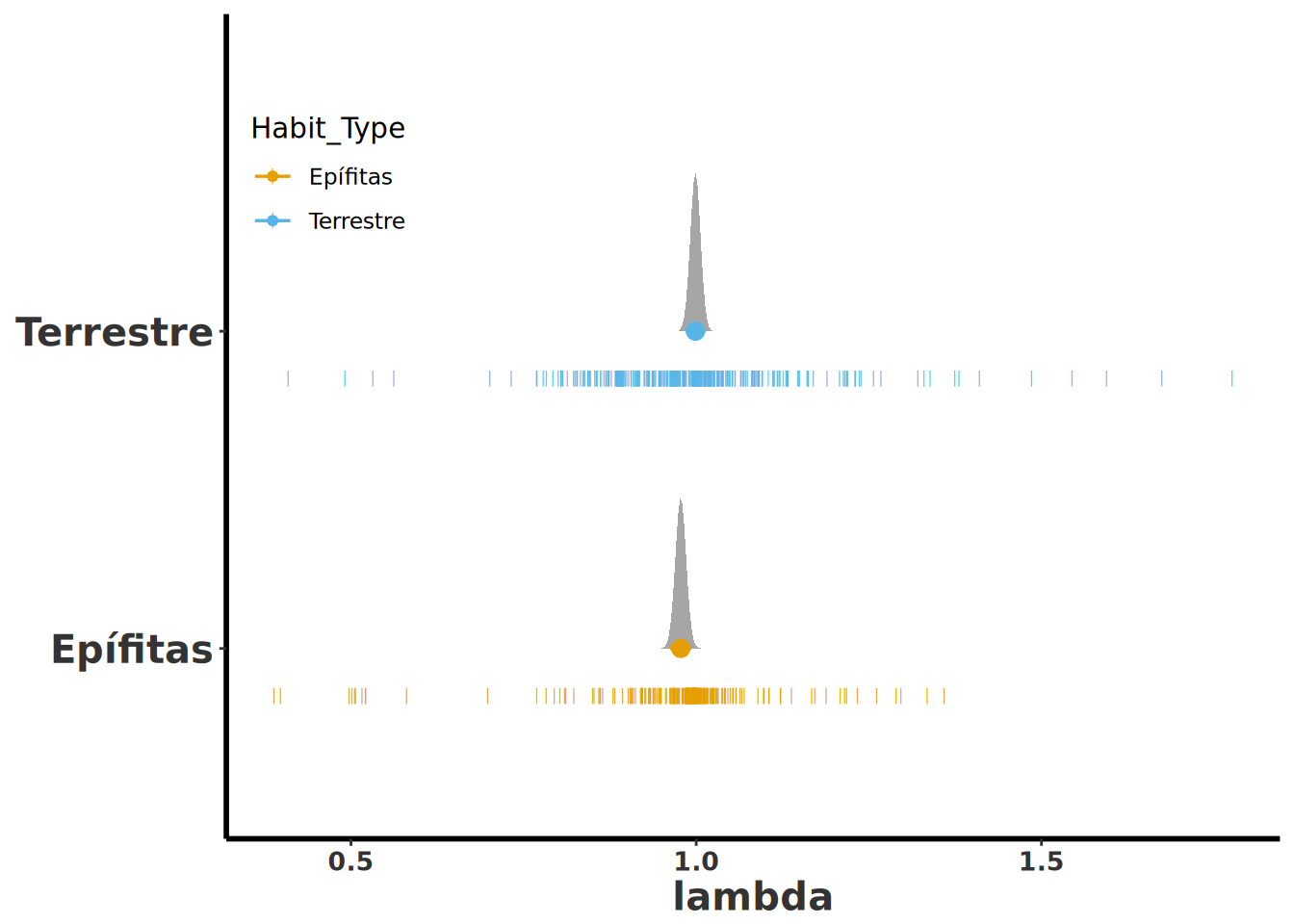
La gráfica anterior puede ocultar la dispersión de los datos, especialmente cuando hay sesgos. Para abordar esto, se pueden añadir los datos originales a la figura. En este caso, se ha incorporado un símbolo de barra **\|** por cada valor de lambda en la parte inferior de la gráfica. Al observar esta nueva visualización, se nota que la dispersión varía significativamente si se compara la representación basada en el promedio y el error estándar con la distribución real de los datos, representada por los **\|**. Esta figura permite apreciar mejor tanto la dispersión como la distribución de los datos. En comparación con la gráfica anterior, esta ofrece una perspectiva más completa, destacando los valores que se alejan del centro de la distribución.
```{r}
#| label: fig-Rage32
#| fig-cap: "Distribuciones predichas (stat_halfeye) de lambda según Habit_Type a partir del modelo model_lambda, con los valores observados superpuestos como marcas."
ALL_Lambdas %>%
expand(Habit_Type) %>%
augment(model_lambda, newdata = ., se_fit = TRUE) %>%
ggplot(aes(y = Habit_Type, colour = Habit_Type)) +
stat_halfeye(
aes(
xdist = dist_student_t(
df = df.residual(model_lambda),
mu = .fitted,
sigma = .se.fit
)
),
scale = .5
) +
geom_point(
aes(x = lambda),
data = ALL_Lambdas,
pch = "|",
size = 2,
position = position_nudge(y = -.15)
) +
theme(legend.position = c(0.1, 0.8)) +
rlt_style_colour() +
ylab("")
```
------------------------------------------------------------------------
## Mapa de distribución de los estudios.
La lista presentada corresponde a los datos extraídos de la base de datos COMPADRE, complementados con información obtenida directamente de los artículos científicos, con el objetivo de construir un mapa que muestre dónde se han realizado estudios de dinámica poblacional.
Lamentablemente, COMPADRE aún carece de muchos datos y detalles importantes que deberían incorporarse a su base. En esta sección, se realizó una búsqueda específica de estudios sobre orquídeas dentro de COMPADRE, extrayendo las coordenadas de latitud y longitud directamente de los artículos originales.
En los casos en que no se encontraron coordenadas exactas, pero sí se identificó el país o región del estudio, se utilizó Google Maps para estimar las coordenadas aproximadas del sitio de muestreo. Cuando no fue posible obtener ninguna información sobre la localización del estudio, esos casos fueron excluidos del mapa.
Agradezco a Diana Molina Ozuma por su valiosa colaboración en la búsqueda de las coordenadas de los sitios de estudio.
```{r Rage33}
Orchid_data_DOI_Diana_3a <- read_excel("data/Orchid_data_DOI_Diana_3a.xlsx")
```
```{r Rage34, warning=FALSE, message=FALSE}
Lat_Long <- Orchid_data_DOI_Diana_3a %>%
select(SpeciesAccepted, Lon, Lat, OrganismType) |>
distinct(SpeciesAccepted, Lon, Lat, OrganismType)
# write_csv(Lat_Long, "data/Orchid_data_DOI_Diana_3a.csv")
```
------------------------------------------------------------------------
### Visualización de distribución geoespacial
Para representar la distribución geográfica de las orquídeas registradas en la base de datos `COMPADRE`, se utilizó el paquete `ggplot2`. En esta visualización, se emplea la función `borders()`, que incorpora los contornos de los países al mapa. Esta función se basa en el paquete `maps`, el cual proporciona los datos geográficos necesarios para delinear los límites nacionales, permitiendo contextualizar espacialmente los puntos de muestreo.
```{r, message=FALSE, warning=FALSE}
#| label: fig-Rage35
#| fig-cap: "Mapa mundial con borders() y geom_point que ubica las poblaciones de Lat_Long en coordenadas Lon y Lat, coloreadas por OrganismType."
ggplot2::ggplot(Lat_Long, aes(Lon, Lat, colour = OrganismType)) +
borders(database = "world", fill = "grey80", colour = NA) +
geom_point(size = 1.0, alpha = 0.5) +
theme(legend.position = c(0.15, 0.2)) +
rlt_style_colour()
# ggsave("orchid_map.jpg")
```
------------------------------------------------------------------------
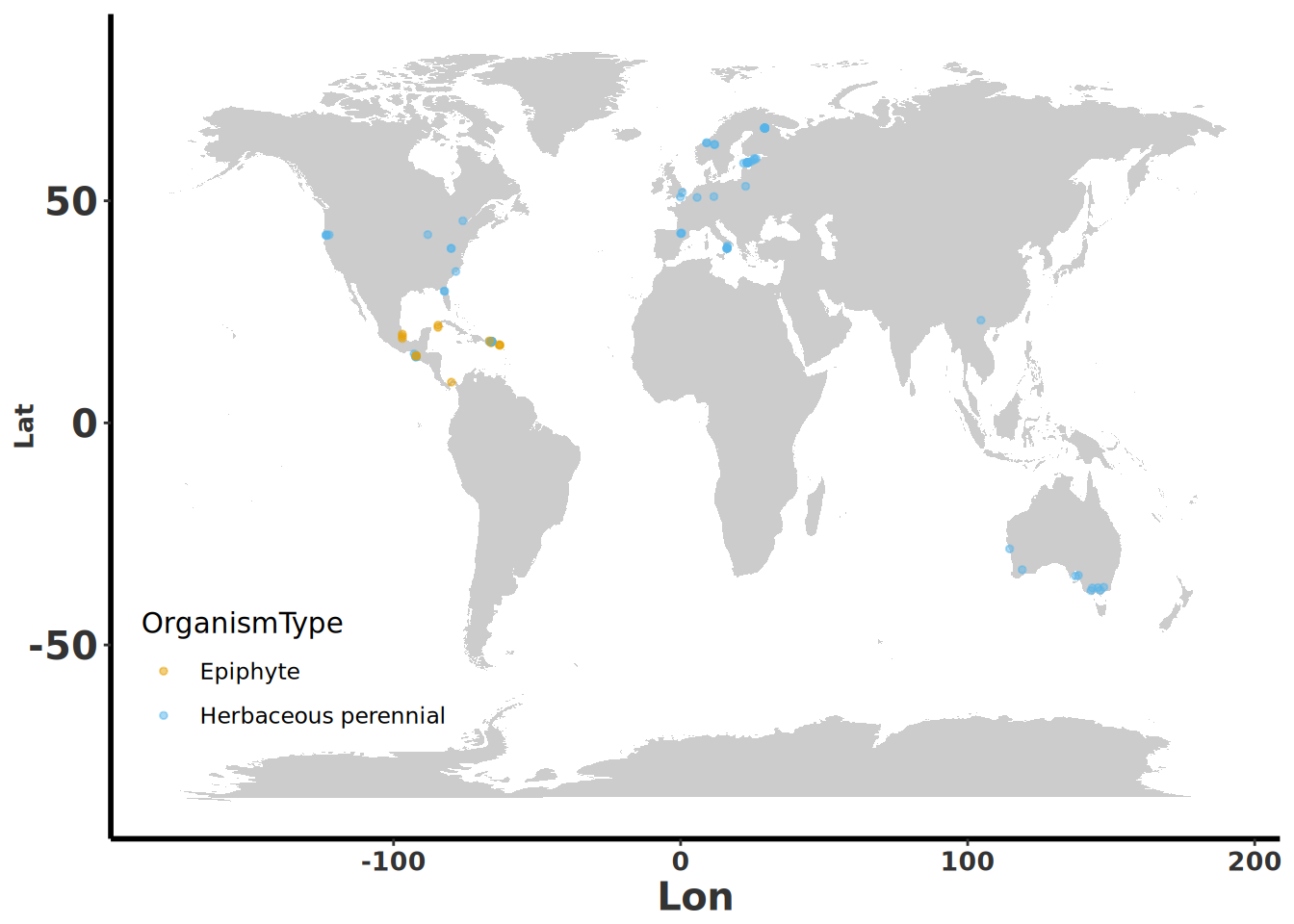
## Mapa de distribución interactivo con Leaflet
Se utilizó el paquete `leaflet` para crear un mapa interactivo que muestra los sitios de muestreo de las especies de orquídeas estudiadas en campo. Este enfoque permite explorar visualmente la distribución geográfica de las poblaciones incluidas en los estudios.
El mapa revela una marcada disparidad en los sitios de muestreo entre los dos tipos de orquídeas. Las poblaciones marcadas en naranja corresponden a especies epífitas, mientras que las azules representan especies terrestres. Se observa que las especies terrestres están principalmente distribuidas en Europa y América del Norte, con escasa representación en Asia y ninguna en África. Por otro lado, las especies epífitas se concentran en el Caribe y América Central (especialmente México), sin presencia en África, Asia ni Australia.
::: callout-important
## Sesgo geográfico de COMPADRE
La distribución que se ve en el mapa **no refleja la diversidad real de las orquídeas en el mundo**, sino la distribución geográfica del esfuerzo de investigación demográfica. Regiones con altísima diversidad de orquídeas (Borneo, Nueva Guinea, los Andes, el África tropical) están casi ausentes de la base de datos. Cualquier conclusión global sobre patrones demográficos debe interpretarse con esta limitación en mente: estamos describiendo *dónde se ha estudiado*, no *dónde habitan* las orquídeas.
:::
Además, el mapa es interactivo y permite hacer zoom para examinar áreas específicas con mayor detalle. Presiona sobre los puntos para obtener información adicional sobre el nombre científico de la especie muestreada en este sitio.
::: {.content-visible when-format="html"}
```{r Rage36}
PointUsePalette <- leaflet::colorFactor(
palette = c("#009392", "#CF597E"),
domain = c("Epiphyte", "Herbaceous perennial")
) # para asignar los colores a los factores (clase de Vida)
Orchid_map <- leaflet(Lat_Long) %>% # los datos
addTiles() %>%
addCircleMarkers(
lng = ~Lon, # la longitud
lat = ~Lat, # la latitud
radius = 2, # el tamaño del punto
color = ~ PointUsePalette(OrganismType), # Para colorear los puntos por el tipo clase de vida
popup = ~ paste0("<I>", SpeciesAccepted, "</I>") # para poner los nombres científicos en itálicos
)
Orchid_map
# htmltools::save_html(Orchid_map, file = "Orchid_map.html") # El script para crear un archivo aparte del mapa
```
:::
::: {.content-visible when-format="pdf"}
*El mapa interactivo de distribución de orquídeas está disponible únicamente en la versión HTML del libro.*
:::
------------------------------------------------------------------------
## De la métrica al argumento biológico
Calcular esperanzas de vida y tiempos generacionales es la mitad fácil. La mitad difícil —y la que separa un análisis presentable de uno que sobrevive la revisión por pares— es **construir un argumento biológico** a partir de las métricas, no sólo reportarlas.
A continuación se ilustra el patrón en cuatro pasos, usando los objetos calculados arriba (`esperanza_vida`, `tiempo_gen`, `edad_madurez`) sobre el subconjunto filtrado `Mat_erg_irred`.
### Paso 1 — Tabla resumen por hábito de vida
Combinamos las tres métricas con el `OrganismType` correspondiente para comparar epífitas vs. terrestres:
```{r Rage_compare}
# Construir un data frame con las tres métricas + hábito de vida.
# Los tres vectores están alineados con el orden de Mat_erg_irred (mismo length),
# y las matrices sin sentido biológico (colSums(U) >= 1) ya quedaron como NA en
# los chunks anteriores, así que drop_na() las elimina aquí automáticamente.
metricas <- tibble(
habito = cdb_metadata(Mat_erg_irred)$OrganismType,
esperanza_vida = esperanza_vida,
tiempo_gen = tiempo_gen,
edad_madurez = edad_madurez
) %>%
drop_na() %>%
mutate(
habito = case_when(
habito == "Epiphyte" ~ "Epífita",
habito == "Herbaceous perennial" ~ "Terrestre",
TRUE ~ habito
)
)
# Resumen por hábito
metricas %>%
group_by(habito) %>%
summarise(
n = n(),
esperanza_med = round(median(esperanza_vida, na.rm = TRUE), 2),
tiempo_gen_med = round(median(tiempo_gen, na.rm = TRUE), 2),
edad_madurez_med = round(median(edad_madurez, na.rm = TRUE), 2)
) %>%
flextable()
```
### Paso 2 — Pregunta concreta
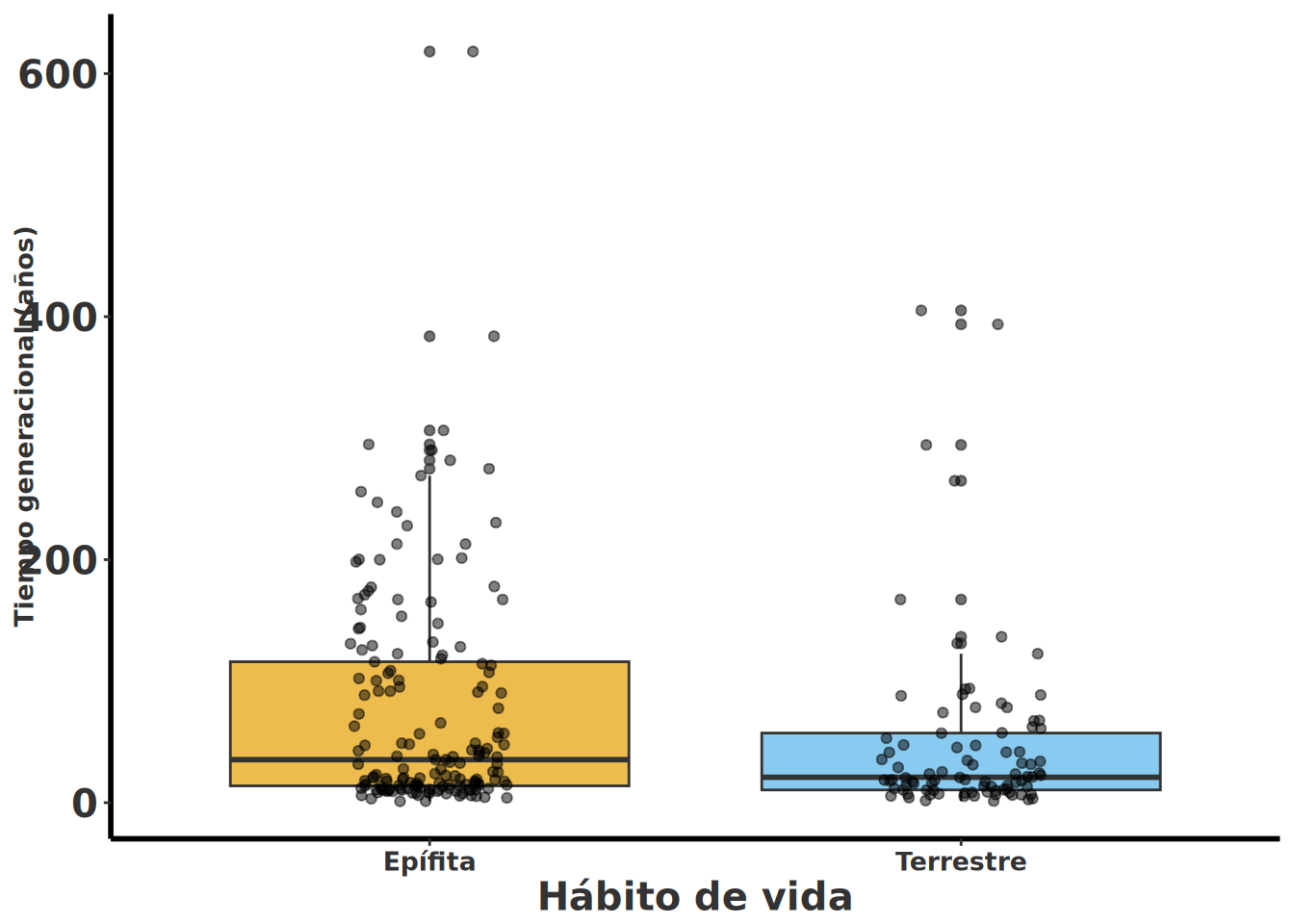
¿Las epífitas tienen tiempos generacionales más largos que las terrestres? Si así fuera, sería evidencia de que viven en un régimen "lento" (longevidad alta, reproducción tardía) coherente con su hábito —un sustrato menos predecible favorece el riesgo distribuido a través de muchos eventos reproductivos pequeños.
### Paso 3 — Visualización antes que estadística
```{r}
#| label: fig-Rage_compare_plot
#| fig-cap: "Diagrama de cajas con puntos superpuestos (geom_boxplot más geom_jitter) del tiempo generacional en años según el hábito de vida."
ggplot(metricas, aes(x = habito, y = tiempo_gen, fill = habito)) +
geom_boxplot(alpha = 0.7) +
geom_jitter(width = 0.15, alpha = 0.5) +
ylab("Tiempo generacional (años)") +
xlab("Hábito de vida") +
theme(legend.position = "none") +
rlt_style_fill()
```
### Paso 4 — La discusión que un revisor pediría
Suponga que el gráfico muestra una mediana mayor en epífitas. Antes de afirmar que esto refleja una diferencia evolutiva real, un revisor crítico preguntará:
::: callout-warning
## Las cuatro preguntas que un revisor hará
1. **¿Pseudoreplicación?** Una sola especie (p. ej. *Lepanthes caritensis*) puede contribuir varias matrices del mismo estudio. Si esa especie está en uno solo de los grupos, el resultado puede deberse a esa especie, no al hábito de vida. Verifíquelo con `count(metricas, SpeciesAccepted)` y use modelos mixtos con la especie como efecto aleatorio para inferencias formales.
2. **¿Sesgo geográfico?** ¿Las epífitas en su muestra son tropicales y las terrestres templadas? La diferencia que ve podría reflejar el clima, no el hábito. Mapéelas (sección anterior) y considere agregar latitud como covariable.
3. **¿Sesgo de detección?** Las orquídeas terrestres con latencia subterránea son menos detectables; sus tiempos generacionales pueden estar subestimados si la latencia no se modeló (ver capítulos sobre etapas crípticas y fecundidad). Reporte qué especies tienen `MatrixCriteriaOntogeny` con etapas latentes.
4. **¿Calidad de la matriz?** ¿Filtró por `check_NA_A`, `check_ergodic` y `check_irreducible`? ¿Las matrices que pasaron tienen `colSums(matU) ≤ 1`? Sin esas garantías, los números son numéricamente válidos pero biológicamente sospechosos (ver el capítulo sobre datos sin sentido biológico).
:::
Un análisis comparativo que **anticipe** estas cuatro preguntas en su discusión —y muestre los gráficos / estadísticas correspondientes— es el que sobrevive la revisión por pares. Reportar la métrica sin enfrentarlas es invitar al rechazo.
------------------------------------------------------------------------
## Ejercicios — Pruebe usted mismo
::: callout-tip
## Ejercicio 1 — Esperanza de vida por especie
Calcule la mediana de la esperanza de vida (`life_expect_mean`) para cada especie de orquídea en COMPADRE con al menos dos matrices. ¿Cuál es la especie con la esperanza de vida más alta? ¿Y la más baja? ¿Tiene sentido biológico?
:::
::: callout-tip
## Ejercicio 2 — Tiempo generacional \~ longevidad
Cree un gráfico de dispersión de `gen_time` contra `life_expect_mean` para todas las matrices del subconjunto. ¿Hay correlación? ¿Qué especies se separan del patrón general?
:::
::: callout-tip
## Ejercicio 3 — Sensibilidad al `start`
Recalcule `life_expect_mean` con `start = 2L` (juvenil) y `start = N` (donde N es la última etapa). Compare con los resultados originales (`start = 1L`). ¿Cuánto cambia? ¿Qué reportaría usted en un manuscrito —y por qué?
:::
::: callout-tip
## Ejercicio 4 — Iteroparidad vs. semelparidad
Use `Rage::entropy_d()` sobre el subconjunto. ¿Las orquídeas son más iteróparas (entropía baja) o más semélparas (entropía alta)? Compare con grupos no-orquídeas usando otro `Family` en COMPADRE.
:::